sizzle分析记录:分解流程
<form>
<label>Name:</label>
<input name="name" />
<fieldset>
<label>Newsletter:</label>
<div name="newsletter" /><p>1<p</div>
<div name="letter" /><p name='aaron'>2<p></div>
<div name="tter" /><p>3<p</div>
</fieldset>
</form>
js
$("form div > p[name=aaron]")
解析的流程:
编译器:分5个步骤
涉及: TAG元素 关系选择器 属性选择器
1:通过tokenize词法分析器分组

2:遍历tokens,从右边往左边开始筛选,最快定位到目标元素合集
//先看看有没有搜索器find,搜索器就是浏览器一些原生的取DOM接口,简单的表述就是以下对象了
// Expr.find = {
// 'ID' : context.getElementById,
// 'CLASS' : context.getElementsByClassName,
// 'TAG' : context.getElementsByTagName
// }
操作如下
Expr.find["TAG"] = support.getElementsByTagName ?
function( tag, context ) {
if ( typeof context.getElementsByTagName !== strundefined ) {
return context.getElementsByTagName( tag );
}
} :
那么第一筛选找到的定位元素,就形成了一个 seed种子合集,那么余下的所有的操作都是围绕这个种子合集处理
因为节点总是存在各种关系的,所以不管是通过这个最靠近的目标的元素,往上还是往下 都是可以处理的
3:重组选择器,开始执行继续分解"form div > [name=aaron]"
因为种子合已经抽出了,所以选择器就需要重新排列
"form div > [name=aaron]"
踢掉了P元素,已经被抽离了
4 : 生成编译处理器
这里为什么要这么复杂,因为生成了编译闭包可以缓存起来,通过这种机制,增加了重复选择器的效率
在matcherFromTokens方法中通过分解tokens生成对应的处理器
例如:form div [name=aaron]
在分解过程中分2大块
A:关系选择器的处理 > + ~ 空
B: ATTR CHILD CLASS ID PSEUDO TAG的处理
用matchers保留组合关系
1:分解第一个TAG:form 保存处理器到matchers.push( Expr.filter[“TAG”]) ;
2:分解第二个“空”的关系选择器,此时
A:用elementMatcher把之前的matchers压入到这个匹配里面,生成一个遍历方法的处理
function elementMatcher( matchers ) {
return matchers.length > 1 ?
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
return true;
} :
matchers[0];
}
B:用addCombinator再次包装,生成一个位置关系的查找关系
function addCombinator( matcher, combinator, base ) {
var dir = combinator.dir,
checkNonElements = base && dir === "parentNode",
doneName = done++; return
// Check against all ancestor/preceding elements
// 检查所有祖先/元素
function( elem, context, xml ) {
var oldCache, outerCache,
newCache = [ dirruns, doneName ];
while ( (elem = elem[ dir ]) ) {
if ( elem.nodeType === 1 || checkNonElements ) {
outerCache = elem[ expando ] || (elem[ expando ] = {});
if ( (oldCache = outerCache[ dir ]) &&
oldCache[ 0 ] === dirruns && oldCache[ 1 ] === doneName ) { // Assign to newCache so results back-propagate to previous elements
return (newCache[ 2 ] = oldCache[ 2 ]);
} else {
// Reuse newcache so results back-propagate to previous elements
outerCache[ dir ] = newCache; // A match means we're done; a fail means we have to keep checking
if ( (newCache[ 2 ] = matcher( elem, context, xml )) ) {
return true;
}
}
}
}
};
}
所以此时的matchers的关系是一个层级的包含结构,然后依次这样递归
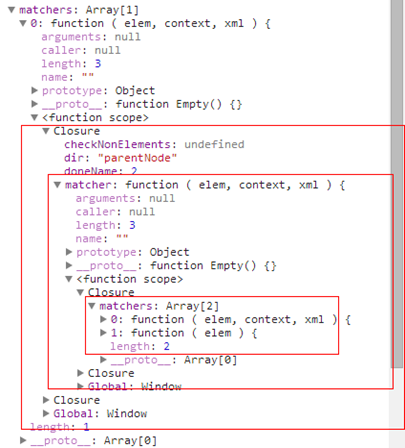
这个地方相当绕!!!!
生成的最后
cached = matcherFromTokens( match[i] );
变成了一个超大的嵌套闭包
5: 通过matcherFromGroupMatchers这个函数来生成最终的匹配器
var bySet = setMatchers.length > 0,
byElement = elementMatchers.length > 0, superMatcher = function(seed, context, xml, results, outermost) {
//分解这个匹配处理器
} return superMatcher
通过matcherFromGroupMatchers的处理最直接的就是能看出,elementMatchers, setMatchers 2个结果不需要再返回出去,直接形成curry的方法,在内部就合并参数
外面就直接调用了,这样
var compileFunc = compiled || compile( selector, match ); compileFunc(
seed,
context,
!documentIsHTML,
results,
outermost
);
compileFunc 一直是持有elementMatchers, setMatchers 的引用的,这个设计的手法还是值得借鉴的
执行期:
至此之前的5个步骤都是编译成函数处理器的过程,然后就是开始执行了
粗的原理就是把直接分解出来的seed种子合集丢到这个处理器中,然后处理器就会根据各种关系进行分解匹配
从而得到结果集
superMatcher:
while ( (matcher = elementMatchers[j++]) ) {
if ( matcher( elem, context, xml ) ) {
results.push( elem );
break;
}
}
抽出第一个seed元素,p
然后把p丢到atrr是过滤筛选器中去匹配下,看看是否能找到对应的这个属性
当然还是继续从右往左边匹配过滤了
一次是【name=aaron】 => div => from
matchers[i] => Expr.filter.ATTR =>
p.getAttribute(‘name=aaron’) => 得到结果
function elementMatcher( matchers ) {
return matchers.length > 1 ?
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
return true;
} :
matchers[0];
}
如果匹配失败,自然就退出了 return false ,就不需要在往前找了 ,然后再次递归seed
如果成功,就需要再深入的匹配了
因为是从右到左逐个匹配,所以往前走就会遇到关系选择器的问题,
那么jQuery把四种关系 > + ~ 空的处理给抽出一个具体的方法就是addCombinator
1 "form div > p[name=aaron]"
2 seed => p
3 筛选[name=aaron]
4 > => addCombinator方法 找到对应关系映射的父节点elem
5 elem中去匹配div 递归elementMatcher方法
6 “空” => addCombinator方法找到祖先父节点elem
7 elem中去找form为止
可见这个查找是及其复杂繁琐的
总结:
sizzle对选择器的大概是思路:
分解所有的选择器为最小单元,从右往左边开始挑出一个浏览器的API能快速定位的元素TAG,ID,CLASS节点,这样就能确定最终的元素跟这个元素是有关系的
然后把剩余的选择器单元开始生成一个匹配器,主要是用来做筛选,最后根据关系分组
如果就依次匹配往上查找,通过关系处理器定位上一个节点的元素,通过普通匹配器去确定是否为可选的内容
sizzle分析记录:分解流程的更多相关文章
- sizzle分析记录:词法分析器(tokenize)
词法分析器(tokenize)? 词法分析器又称扫描器.词法分析是指将我们编写的文本代码流解析为一个一个的记号,分析得到的记号以供后续语法分析使用. sizzle引入了tokenize这个概念,意义? ...
- sizzle分析记录:关于querySelectorAll兼容问题
querySelector和querySelectorAll是W3C提供的新的查询接口 目前几乎主流浏览器均支持了他们.包括 IE8(含) 以上版本. Firefox. Chrome.Safari.O ...
- sizzle分析记录:getAttribute和getAttributeNode
部分IE游览器下无法通过getAttribute取值? <form name="aaron"> <input type="text" name ...
- sizzle分析记录:属性选择器
源码部分 通过Sizzle.attr匹配出值 然后通过表达式刷选计算 "ATTR": function( name, operator, check ) { return func ...
- sizzle分析记录: 自定义伪类选择器
可见性 :hidden :visible 隐藏对象没有宽高,前提是用display:none处理的 jQuery.expr.filters.hidden = function( elem ) { // ...
- Fine报表权限流程分析记录
Fine报表权限流程分析记录 URL访问三种类型的报表:第一个:BI报表 例如: http://192.25.103.250:37799/WebReport/ReportServer?op=fr_bi ...
- Okhttp源码分析--基本使用流程分析
Okhttp源码分析--基本使用流程分析 一. 使用 同步请求 OkHttpClient okHttpClient=new OkHttpClient(); Request request=new Re ...
- Atitit 分区后的查询 mysql分区记录的流程与原理
Atitit 分区后的查询 mysql分区记录的流程与原理 1.1.1. ibd是MySQL数据文件.索引文件1 1.2. 已经又数据了,如何分区? 给已有的表加上分区 ]1 1.3. 分成4个区, ...
- 转:[gevent源码分析] 深度分析gevent运行流程
[gevent源码分析] 深度分析gevent运行流程 http://blog.csdn.net/yueguanghaidao/article/details/24281751 一直对gevent运行 ...
随机推荐
- java并发J.U.C AtomicReference VS Volatile
SpinLock实现,摘自并发编程网 package com.juc.simple; import java.util.concurrent.atomic.AtomicReference; /** * ...
- 【原】iOS学习之tableView的常见BUG
1.TableView头视图不随视图移动,头视图出现错位 错误原因:tableView的 UITableViewStyle 没有明确的声明 解决方法:在tableView声明的时候明确为 UITabl ...
- Unity中的Matrix4x4类
物体平移旋转一般变换底层都是用矩阵来表示的,一般不会用到这个类.有时候需要一些世界坐标与局部坐标转换的时候,可能就要用到了. //创建平移 旋转 缩放矩阵 可以理解为一个坐标系(不知道对不对..) M ...
- tornado 学习笔记16 HTTP1Connection
HTTP/1.x协议的具体实现.实现HTTPConnection接口. 16.1 构造函数 定义: def __init__(self, stream, is_client, params=None, ...
- Jsonp原理就是这么简单
原理就是:包裹数据的js数据文件,自动执行,找到目标函数,通过传参,把数据注入进去. 当你打开本篇博文,证明你已经大体知道了Jsonp的作用了. 但如果需要我介绍一下,我也可以简单介绍: 简单说,就是 ...
- Flask 重新认识
总是觉的学习东西有点猴子掰玉米的感觉.今天就重新再掰一次吧. Installation: 安装之前建议先安装virtualenv,这个东东是帮助你在多个python版本之间保持同步,不至于python ...
- dns解析慢 修改的参数
情况: ping域名时反应速度慢,ping ip却很正常 方法一:禁用ipv6 /etc/hosts中注释ipv6相关的 vim /etc/sysconfig/networks NETWORKING_ ...
- oracle10g冷备份和恢复过程记录
一.冷备份: 1.操作系统无法进入,需要利用启动盘进入winpe系统进行操作. 2.进入PE系统后,搜索所有盘符确认没有其它被作为oracle数据文件存放的目录,也就是说所有oracle有关的文件都存 ...
- '-[__NSCFString stringFromMD5]: unrecognized selector sent to instance 0x14d89a50'
类型:ios 问题描述: 导入百度地图 然后在模拟器运行可以,真机测试不行: 报错: '-[__NSCFString stringFromMD5]: unrecognized selector sen ...
- 为首次部署MongoDB做好准备:容量计划和监控
如果你已经完成了自己新的MongoDB应用程序的开发,并且现在正准备将它部署进产品中,那么你和你的运营团队需要讨论一些关键的问题: 最佳部署实践是什么? 为了确保应用程序满足它所必须的服务层次我们需要 ...