解密prompt系列53. 再谈大模型Memory
上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm
Titan
- Titans: Learning to Memorize at Test Time
Titan的出发点有两个
- 传统Transformer的局限性:虽然Transformer在序列建模中表现优异,但其注意力机制是平方级的复杂度,因此限制了输入的上文的长度。
- 改良线性Transformer的不足:虽然线性Transformer通过核函数近似注意力,降低了复杂度,但对历史记忆的处理是把记忆压缩成固定的向量矩阵,本质还是上一章我们闲聊提到的线性表达,没有更深层次的压缩和抽象。
所以Titan主要探索了基于多层MLP的记忆存储模块和当前模型的融合。核心目标就似乎构建动态、可学习的记忆系统,结合短期(注意力)和长期记忆(神经记忆),模拟人脑的多层次记忆机制。
这里我们重点看下记忆模块的实现,分成3个部分,记忆存储结构、记忆更新方式和记忆检索。
核心
首先是记忆存储结构,论文没有在这个部分做深入的探索,只考虑了简单的多层MLP,更多对于存储网络结构的探索留给后人完成。这里多层MLP本身结构足够简单,同时对比矩阵又提供了多层压缩和抽象的能力。类似之前人们发现Transformer的FFN层中知识是按键值对方式进行存储,这里Titan也使用键值对来存储记忆,Key,Val分别使用多层MLP映射得到,而映射的MLP通过以下记忆更新进行持续学习。

其次是记忆更新方式,这里论文采用在线学习来对记忆模块的参数进行持续更新,损失函数就是存储记忆的Key,Value之间的空间距离,而梯度更新时,Titan同时考虑到了动态遗忘机制和动量机制,其中
- \(\theta_t\)后面的部分是序列当前输入的梯度大小,Titan认为这里的梯度大小反映了信息的重要程度,梯度越大对记忆的更新幅度也就越大
- \(\alpha_t\)是类似RNN的遗忘门,支持在输入超长上文时动态选择对历史信息进行遗忘
- \(\eta_t\)类似momentun,保证记忆更新的方向对持续性,同时也可以理解为历史记忆的时间衰减参数
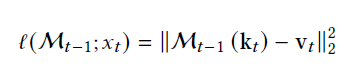
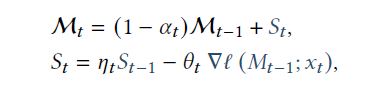
再就是记忆获取方式,既然存储是KV所以信息获取也是一样,也就是直接冻结参数,把输入喂进MLP得到的就是该信息相关的记忆存储了\(M(q_t)\)
如何使用记忆模块
Titans给出了三种不同的记忆模块的使用方案
- MAC(Memory as Context)
- 长期记忆的输出作为上下文与当前输入拼接 ,显式引入历史记忆作为全局上下文。 也就是把超长上文分段,使用最后一个chunk作为query,其余为历史记忆,使用query去获取历史记忆,并和当前chunk拼接作为上文。
- 公式:\(\hat{x}_t = \text{Concat}(h_t, p, x_t)\),其中\(h_t = \mathcal{M}^*(x_t)\)
- 适合需要全局检索例如如多文档问答,以及依赖全局高度一致性的任务例如长文本写作任务像小说写作。
- MAG(Memory as Gate)
- 输入通过滑动窗口处理短期信息,同时从记忆模块提取长期偏好,通过门控机制动态融合注意力输出(短期依赖)与记忆输出(长期偏好)
- 公式:\(o_t = \sigma(W_g) \odot \text{Attn}(x_t) + (1-\sigma(W_g)) \odot \mathcal{M}(x_t)\)。
- MAL(Memory as Layer)
- 将记忆模块作为独立层,与注意力模块串联(如
Memory → Attention或Attention → Memory),有点类似Mamba等hybrid模型。 - 公式:\(y_t = \text{Attn}(\mathcal{M}(x_t))\) 或 \(y_t = \mathcal{M}(\text{Attn}(x_t))\)。
- 将记忆模块作为独立层,与注意力模块串联(如
Kbalm
- KBLAM: KNOWLEDGE BASE AUGMENTED LANGUAGE MODEL
kbalm则是从知识压缩入手,上一章我们提到当前RAG的一个问题在于,检索回来的内容因为是平铺拼接的因此上文很长,但信息量却不高,虽然当前的大模型已经能支持越来越长的上文输入,但是越长的上文确实带来更差的推理效果,更慢的首Token延时,更高的内存占用等等问题。而解决这个问题的一个思路就是对输入上文进行压缩,如果能和大模型训练一样把知识压缩成向量表达,就能显著提升单位长度的信息密度,在有限的长度内,给模型更多的上文输入信息。Kbalm围绕知识图谱,其实主要是KV结构的知识类型,初步探索了这类方案的可行性。
整个实现方案分成3个部分:首先是对KV型知识进行压缩得到知识的向量表征,其次是依赖适配器把外挂知识的向量表征和大模型参数空间进行对齐,最后就是在推理时通过拼接外挂知识向量和修改后的注意力机制引入上下文进行推理。 下面我们展开说下
知识表征
这里论文选择了最基础的<实体、属性、值>的方式来表征知识,例如<爱因斯坦、职业、科学家>,这种知识表征的好处在于不同知识之间相互独立,如果是对段落进行表征,如果对段落进行chunking后做表征,则还需要考虑到段落之间的关联关系。
论文直接使用向量模型(OpenAI ada2)对知识进行编码,分成了
- key:实体+属性的向量
- value:值的向量
如果是直接对段落的话,其实key和value感觉是可以共享同一个embedding的。但这里现实使用中能想到的一个最大的问题就是向量化后知识肯定是有损压缩的,这个损失比率究竟是多少,当前在向量模型之前的研究中似乎很少分析过这个问题。
适配器训练
有了知识表征,其次就是如何把向量模型的空间和大模型的参数空间进行对齐,毕竟两套模型一定学到的是不一样的空间表征。这里论文选择使用简单的线性Adapter对以上的KV向量进行映射。这里论文没有选择在输入层插入外挂知识的向量,而是和Prompt-Tuning的设计方式类似,选择在LLM的每一层都拼接上外挂向量,因此K和V的适配器的维度是LDP(L是层数,D是LLM KV的向量维度,P是embedding模型维度)。
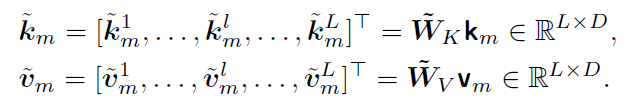
而这里适配器的训练,论文使用了SFT进行适配器的训练。论文基于KB构建了QA问答对,然后在冻结LLM参数的同时,使用最大似然来训练Adapter的参数,训练目标就是拼接外挂向量后模型正确回答QA问题的概率。这里论文总共构建了20K的指令样本。
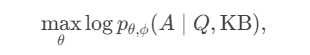
其实这一步已经有些类似我们在上一章提到的,大模型的能力能否做到分块存储,语言能力、世界知识、和推理能力分开,知识的更新在短期应该是只更新知识模块,在长期经过反思可能会影响到推理能力和语言能力。
推理
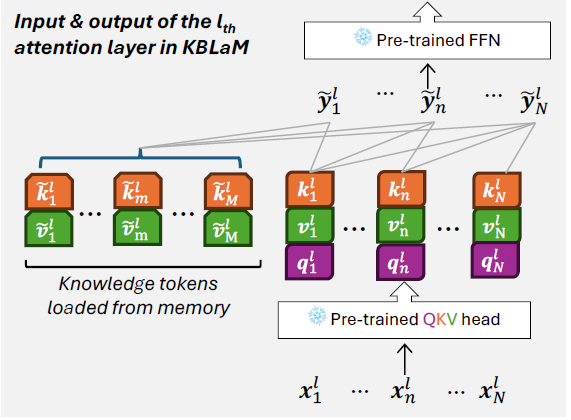
最后就是如何在推理过程中,使用以上知识外挂。这里论文的设计有个强假设,既这里是知识三元组的设计,不同知识之间独立无关。因此KB向量之间不需要cross-attention,只有输入query去和所有KB向量
进行Attention,以及常规GPT的self-attention,如下图。

同时因为KB向量是预计算好直接拼接进模型的,因此不论使用多少知识三元组,都不会影响首Token延时,和KV Cache是类似的原理。因此这里没有像RAG一样的检索召回模块,论文直接选择把所有知识库的向量全部拼接到模型上,完全依赖Attention针对不同问题进行知识获取和选择。
整体上Kbalm尝试了通过向量对知识进行压缩表征,并通过适配器把知识向量与模型向量进行对齐的方案。如果对齐部分能保证在更大场景上更好的泛化性的话,不失为一种知识持续更新的方案。
想看更全的大模型论文·微调预训练数据·开源框架·AIGC应用 >> DecryPrompt
解密prompt系列53. 再谈大模型Memory的更多相关文章
- 解密Prompt系列6. lora指令微调扣细节-请冷静,1个小时真不够~
上一章介绍了如何基于APE+SELF自动化构建指令微调样本.这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节 标题这样写 ...
- 再谈多线程模型之生产者消费者(总结)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(多生产者和多消费者 )(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(多生产者和单一消费者 )(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(单一生产者和多消费者 )(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现)[本文] 再谈多线程模型之生 ...
- 再谈多线程模型之生产者消费者(基础概念)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现)[本文] 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生 ...
- 解密prompt系列5. APE+SELF=自动化指令集构建代码实现
上一章我们介绍了不同的指令微调方案, 这一章我们介绍如何降低指令数据集的人工标注成本!这样每个人都可以构建自己的专属指令集, 哈哈当然我也在造数据集进行时~ 介绍两种方案SELF Instruct和A ...
- 解密Prompt系列2. 冻结Prompt微调LM: T5 & PET & LM-BFF
这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调.以下按时间顺序介绍,支持任意NLP任务的T5,针 ...
- 解密Prompt系列4. 升级Instruction Tuning:Flan/T0/InstructGPT/TKInstruct
这一章我们聊聊指令微调,指令微调和前3章介绍的prompt有什么关系呢?哈哈只要你细品,你就会发现大家对prompt和instruction的定义存在些出入,部分认为instruction是promp ...
随机推荐
- 在SOUI4中使用非客户区自绘
前段时间用sdl嵌入SOUI做视频播放器,由于SOUI习惯屏蔽系统默认的非客户区,而在窗口自己的客户区分出一块来模拟非客户区,导致窗口在拉伸的时候,SOUI窗口会出现比较严重的闪烁(不光是SOUI这样 ...
- API网关-APISIX简介
本文分享自天翼云开发者社区<API网关-APISIX简介>,作者:w****n Apache APISIX 是一个动态.实时.高性能的云原生 API 网关,提供了负载均衡.动态上游.灰度发 ...
- TortoiseGit拉取出现“Could not open repository. libgit2 returned: repository path……”错误的解决办法
TortoiseGit拉取出现"Could not open repository. libgit2 returned: repository path--"错误的解决办法 1.问 ...
- NSSM:简化Windows服务配置,提升系统维护效率
NSSM:简化Windows服务配置,提升系统维护效率 在Windows系统环境中,服务的配置与管理是一项复杂而重要的任务.传统的服务管理方式往往涉及繁琐的步骤,不仅效率低下,还容易出错.然而,随着N ...
- linux监控系统行为
1.验证电脑是否存在,一般都有 which script /usr/bin/script 2.配置profile文件,在末尾添加如下内容: vim /etc/profile ============= ...
- DeepSeek + 在线Excel , 打造智能表格新纪元
微信搜一搜[葡萄城社区]关注,了解更多动态 SpreadJS 已经接入 DeepSeek 啦! 相信这段时间,大家都被[DeepSeek]刷屏了.DeepSeek 以其强大的技术能力和创新的解决方案, ...
- 【COM3D2Mod 制作教程(7)】实战!制作衣服部分(上)
[COM3D2Mod 制作教程(7)]实战!制作衣服部分(上) 教程介绍 隔了 N 个月终于迎来了第二期的 Mod 教程部分,这一期我们将开始制作人物的衣服部分. 因为体型适配的原因,衣服部分要比身体 ...
- git上传大文件!git push 报错 ! [remote rejected] main -> main (pre-receive hook declined) error_ failed to push some refs to 'xxx
前言 今天在用git push项目的时候,出现了一个报错,记录一下解决方案,以后报同样的错误可以回来看. 错误信息 下面是git push的详细报错信息: 20866@DESKTOP-7R0VL04 ...
- 从文件到块: 提高 Hugging Face 存储效率
Hugging Face 在 Git LFS 仓库 中存储了超过 30 PB 的模型.数据集和 Spaces.由于 Git 在文件级别进行存储和版本控制,任何文件的修改都需要重新上传整个文件.这在 H ...
- linux shell用expect实现在scp时自动输入密码
文章目录 linux shell用expect自动输入密码 按行读取文件 expect 其他 linux shell用expect自动输入密码 最近有东西需要部署到很多服务器上去,一个服务器一个服务器 ...