再用RNN神经网络架构设计生成式语言模型

上一篇:《用谷歌经典ML方法方法来设计生成式人工智能语言模型》
序言:市场上所谓的开源大语言模型并不完全开源,通常只提供权重和少量工具,而架构、训练数据集、训练方法及代码等关键内容并未公开。因此,要真正掌握人工智能模型,仍需从基础出发。本篇文章将通过传统方法重新构建一个语言模型,以帮助大家理解语言模型的本质:它并不神秘,主要区别在于架构设计。目前主流架构是谷歌在论文《Attention Is All You Need》中提出的 Transformer,而本文选择采用传统的 RNN(LSTM)方法构建模型,其最大局限在于不支持高效并行化,因而难以扩展。
创建模型
现在让我们创建一个简单的模型,用来训练这些输入数据。这个模型由一个嵌入层、一个 LSTM 层和一个全连接层组成。对于嵌入层,你需要为每个单词生成一个向量,因此参数包括总单词数和嵌入的维度数。在这个例子中,单词数量不多,所以用八个维度就足够了。
你可以让 LSTM 成为双向的,步数可以是序列的长度,也就是我们的最大长度减去 1(因为我们从末尾去掉了一个 token 用作标签)。
最后,输出层将是一个全连接层,其参数为总单词数,并使用 softmax 激活。该层的每个神经元表示下一个单词匹配相应索引值单词的概率:
model = Sequential()
model.add(Embedding(total_words, 8))
model.add(Bidirectional(LSTM(max_sequence_len-1)))
model.add(Dense(total_words, activation='softmax'))
使用分类损失函数(例如分类交叉熵)和优化器(例如 Adam)编译模型。你还可以指定要捕获的指标:
python
Copy code
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
这是一个非常简单的模型,数据量也不大,因此可以训练较长时间,比如 1,500 个 epoch:
history = model.fit(xs, ys, epochs=1500, verbose=1)
经过 1,500 个 epoch 后,你会发现模型已经达到了非常高的准确率(见图 8-6)。
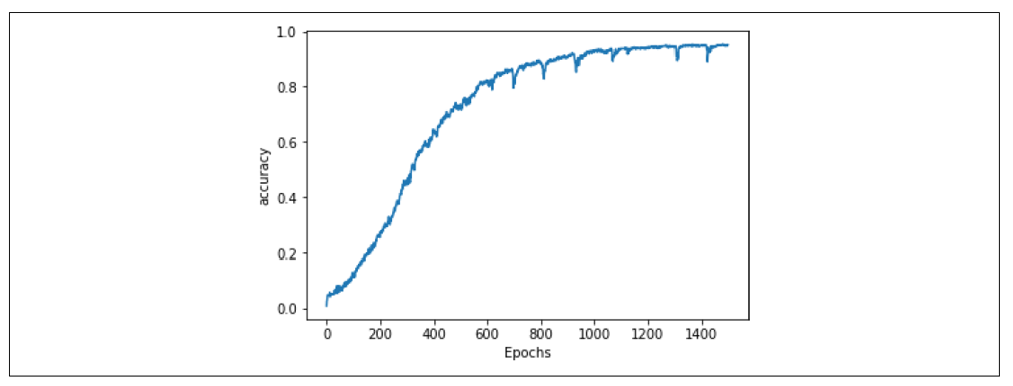
图 8-6:训练准确率
当模型的准确率达到 95% 左右时,我们可以确定,如果输入一段它已经见过的文本,它预测下一个单词的准确率约为 95%。然而请注意,当生成文本时,它会不断遇到以前没见过的单词,因此尽管准确率看起来不错,网络最终还是会迅速生成一些无意义的文本。我们将在下一节中探讨这个问题。
文本生成
现在你已经训练了一个可以预测序列中下一个单词的网络,接下来的步骤是给它一段文本序列,让它预测下一个单词。我们来看看具体怎么做。
预测下一个单词
首先,你需要创建一个称为种子文本(seed text)的短语。这是网络生成内容的基础,它会通过预测下一个单词来完成这一点。
从网络已经见过的短语开始,例如:
seed_text = "in the town of athy"
接下来,用 texts_to_sequences 对其进行标记化。即使结果只有一个值,这个方法也会返回一个数组,因此你需要取这个数组的第一个元素:
python
Copy code
token_list = tokenizer.texts_to_sequences([seed_text])[0]
然后,你需要对该序列进行填充,使其形状与用于训练的数据相同:
token_list = pad_sequences([token_list],
maxlen=max_sequence_len-1, padding='pre')
现在,你可以通过对该序列调用 model.predict 来预测下一个单词。这将返回语料库中每个单词的概率,因此需要将结果传递给 np.argmax 来获取最有可能的单词:
predicted = np.argmax(model.predict(token_list), axis=-1)
print(predicted)
这应该会输出值 68。如果查看单词索引表,你会发现这对应的单词是 “one”:
'town': 66, 'athy': 67, 'one': 68, 'jeremy': 69, 'lanigan': 70,
你可以通过代码在单词索引中搜索这个值,并将其打印出来:
for word, index in tokenizer.word_index.items():
if index == predicted:
print(word)
break
因此,从文本 “in the town of athy” 开始,网络预测下一个单词是 “one”。如果你查看训练数据,会发现这是正确的,因为这首歌的开头是:
In the town of Athy one Jeremy Lanigan
Battered away til he hadn’t a pound
现在你已经确认模型可以正常工作,可以尝试一些不同的种子文本。例如,当我使用种子文本 “sweet jeremy saw dublin” 时,模型预测的下一个单词是 “then”。(这段文本的选择是因为其中的所有单词都在语料库中。至少在开始时,如果种子文本中的单词在语料库中,你应该可以期待更准确的预测结果。)
通过递归预测生成文本
在上一节中,你已经学会了如何用模型根据种子文本预测下一个单词。现在,为了让神经网络生成新的文本,你只需重复预测的过程,每次添加新的单词即可。
例如,之前我使用短语 “sweet jeremy saw dublin”,模型预测下一个单词是 “then”。你可以在种子文本后添加 “then”,形成 “sweet jeremy saw dublin then”,然后进行下一次预测。重复这个过程,就可以生成一段由 AI 创造的文本。
以下是上一节代码的更新版,这段代码会循环执行多次,循环次数由 next_words 参数决定:
seed_text = "sweet jeremy saw dublin"
next_words = 10
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
运行这段代码后,可能会生成类似这样的字符串:
sweet jeremy saw dublin then got there as me me a call doing me
文本很快会变得无意义。为什么会这样?
训练文本量太小:文本语料库的规模非常有限,因此模型几乎没有足够的上下文来生成合理的结果。
预测依赖性:序列中下一个单词的预测高度依赖于之前的单词。如果前几个单词的匹配度较差,即使最佳的“下一个”预测单词的概率也会很低。当将这个单词添加到序列后,再预测下一个单词时,其匹配概率进一步降低,因此最终生成的单词序列看起来会像随机拼凑的结果。
例如,虽然短语 “sweet jeremy saw dublin” 中的每个单词都在语料库中,但这些单词从未以这种顺序出现过。在第一次预测时,模型选择了概率最高的单词 “then”,其概率高达 89%。当把 “then” 添加到种子文本中,形成 “sweet jeremy saw dublin then” 时,这个新短语也从未在训练数据中出现过。因此,模型将概率最高的单词 “got”(44%)作为预测结果。继续向句子中添加单词会使新短语与训练数据的匹配度越来越低,从而导致预测的准确率下降,生成的单词序列看起来越来越随机。
这就是为什么 AI 生成的内容随着时间推移会变得越来越不连贯的原因。例如,可以参考优秀的科幻短片《Sunspring》。这部短片完全由一个基于 LSTM 的网络生成,类似于你正在构建的这个模型,它的训练数据是科幻电影剧本。模型通过种子内容生成新的剧本。结果令人捧腹:尽管开头的内容尚且可以理解,但随着情节推进,生成的内容变得越来越不可理喻。
总结:本篇中,我们成功构建了一个语言模型,虽然未采用当前流行的 Transformer 架构,但这一实践让我们深刻理解了人工智能模型的多样性。即使是当下耗资巨大的 Transformer 模型,也可能很快被更新的架构取代。因此,我们的目标是紧跟技术前沿,掌握模型设计的核心理念。下一篇我们将诗歌如何通过扩展数据集来提高模型的准确度。
再用RNN神经网络架构设计生成式语言模型的更多相关文章
- 怎样设计最优的卷积神经网络架构?| NAS原理剖析
虽然,深度学习在近几年发展迅速.但是,关于如何才能设计出最优的卷积神经网络架构这个问题仍在处于探索阶段. 其中一大部分原因是因为当前那些取得成功的神经网络的架构设计原理仍然是一个黑盒.虽然我们有着关于 ...
- 微软&中科大提出新型自动神经架构设计方法NAO
近期,来自微软和中国科学技术大学的刘铁岩等人发表论文,介绍了一种新型自动神经架构设计方法 NAO,该方法由三个部分组成:编码器.预测器和解码器.实验证明,该方法所发现的架构在 CIFAR-10 上的图 ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- NVIDIA Turing Architecture架构设计(上)
NVIDIA Turing Architecture架构设计(上) 在游戏市场持续增长和对更好的 3D 图形的永不满足的需求的推动下, NVIDIA 已经将 GPU 发展成为许多计算密集型应用的世界领 ...
- 深度解读MRS IoTDB时序数据库的整体架构设计与实现
[本期推荐]华为云社区6月刊来了,新鲜出炉的Top10技术干货.重磅技术专题分享:还有毕业季闯关大挑战,华为云专家带你做好职业规划. 摘要:本文将会系统地为大家介绍MRS IoTDB的来龙去脉和功能特 ...
- MRS IoTDB时序数据库的总体架构设计与实现
MRS IoTDB时序数据库的总体架构设计与实现 MRS IoTDB是华为FusionInsight MRS大数据套件最新推出的时序数据库产品,其领先的设计理念在时序数据库领域展现出越来越强大的竞争力 ...
- 浅谈 jQuery 核心架构设计
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- 解构C#游戏框架uFrame兼谈游戏架构设计
1.概览 uFrame是提供给Unity3D开发者使用的一个框架插件,它本身模仿了MVVM这种架构模式(事实上并不包含Model部分,且多出了Controller部分).因为用于Unity3D,所以它 ...
- 一种简单的CQRS架构设计及其实现
一.为什么要实践领域驱动? 近一年时间我一直在思考一个问题:"如何设计一个松耦合.高伸缩性.易于维护的架构?".之所以有这样的想法是因为我接触的不少项目都是以数据库脚本来实现业务逻 ...
随机推荐
- MDC – Checkbox
前言 Checkbox 不是搭配 TextField 使用, 而是搭配 FormField. 所以独立一篇来写. 参考 Docs – Selection controls: checkboxes 效果 ...
- CSS & JS Effect – Tooltip
介绍 Tooltip 长这样 它用 popup 的方式来详细描述一个主体. 比如某个 icon 代表着什么. 参考 YouTube – How To Make Tooltips With Only C ...
- 月薪20k以上的软件测试工程师的必备知识点?全部拿走吧!
我们都知道作为一个软件测试工程师,入门相对比较简单,但是要达到技术精通,甚至薪资能达到20k以上的话,那绝对需要对测试开发有一个系统的了解,以及对这些系统的知识能够熟练掌握. 今天的话是我从阿里以为做 ...
- 【QT界面美化】QT界面美化效果截图QSS+QML
贴几个QT做的界面美化效果截图. 先来一张动图,有一些画面是QT Widgets + QSS实现的:另外一些画面是QT QML实现的. QT界面美化效果图QT QSS QML 补天云QT技术培训专家 ...
- .net 到底行不行!2000 人在线的客服系统真实屏录演示(附技术详解) 📹
业余时间用 .net 写了一个免费的在线客服系统:升讯威在线客服与营销系统. 时常有朋友问我性能方面的问题,正好有一个真实客户,在线的访客数量达到了 2000 人.在争得客户同意后,我录了一个视频. ...
- CTFSHOW pwn03 WrriteUp
本文来自一个初学CTF的小白,如有任何问题请大佬们指教! 题目来源 CTFShow pwn - pwn03 (ret2libc) https://ctf.show/challenges 思路 1.下载 ...
- 【Pwn】maze - writrup
1.运行函数,收集字符串 获取关键词字符串:luck 2.寻找字符串引用代码 3.生成伪代码 4.获得main函数的C语言代码 5.分析程序逻辑 check函数: main函数 int __fastc ...
- git工具:sourcetree使用中的部分问题
这段时间经常用到这个工具.就当记个笔记,记录一下我的一些问题. 问题一: 如果想要拉取远端更新: 第一步:先登陆sourcetree,点击"抓取". 第二步:在终端输入:git s ...
- Java日期时间API系列40-----中文语句中的时间语义识别(time NLP)代码实现分析
从上篇 Java日期时间API系列39-----中文语句中的时间语义识别(time NLP 输入一句话,能识别出话里的时间)原理分析 中得知解析的主要步骤分为三步: (1)加载正则文件 (2)解析中文 ...
- yarn 命令大全
npm install yarn -g npm install --global yarnyarn 中文网:https://yarn.bootcss.com/docs/install/#windows ...