MACD、RSI、Boll以及分型指标的实现与回测
对指标的实现
分为两部分:
- 信号的计算
实现信号算法
检测历史信号
保存到数据库
- 信号使用
提供查询接口
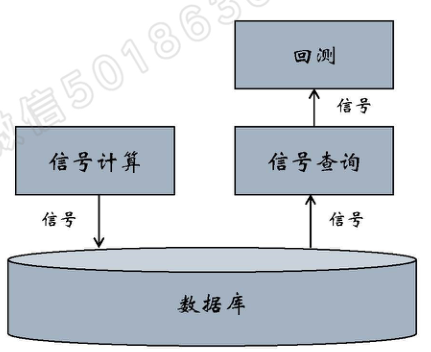
我们将信号的计算与回测分离开,将计算后的信号结果保存到数据库中,供回测时调用,模式图如下:
指标
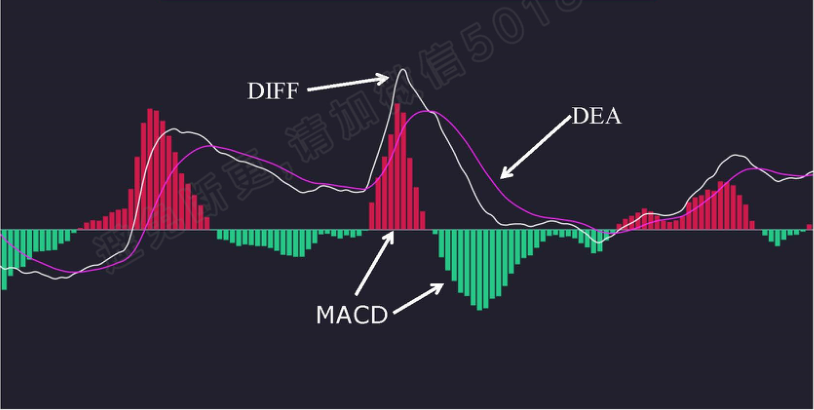
MACD(金叉和死叉)
走势展示:
\]
\]
\]
具体的计算方法:
\(EMA_i\)
\]
\]
短时EMA
\]
长时EMA
\]
DIFF
\]
DEA
\]
通常将短时EMA中参数short设为12,长时EMA中参数long设为26,m=9
早期国内股市一周是6个交易日,short=12相当于两周,一个月就26个交易日,
金叉与死叉
死叉
- DIFF下穿DEA
- \(DIFF_{i-1}>=DEA_{i-1}\) && \(DIFF_{i}<DEA_{i}\)
金叉
- DIFF上传DEA
- \(DIFF_{i-1}<=DEA_{i-1}\) && \(DIFF_{i}>DEA_{i}\)
金叉、死叉直观展示

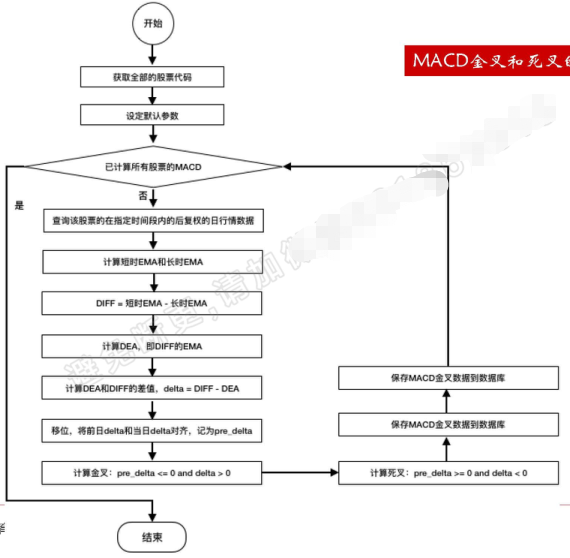
流程图
EMA的计算流程

MACD金叉和死叉的计算流程
代码实现
信号的计算
from stock_util import get_all_codes
from database import DB_CONN
from pymongo import ASCENDING,UpdateOne
import pandas as pd
import traceback
def compute_macd(begin_date,end_date):
"""
计算给定周期内的MACD金叉和死叉信号,把结果保存在数据库中
:param begin_date:开始日期
:param end_date:结束日期
"""
#参数设定,这几个参数是计算MACD时需要的,取值都是常用值,也可以根据需要进行调整
#短时
short=12
#长时
long=26
#计算DIFF的M值
m = 9
#获取股票列表
codes = get_all_codes()
#循环检测所有股票的MACD金叉和死叉信号
for code in codes:
try:
#获取后复权的价格,使用后复权的价格计算MACD
daily_cursor = DB_CONN['daily_hfq'].find(
{'code':code,'date':{'$gte':begin_date,'$lte':end_date},'index':False},
sort=[('date',ASCENDING)],
projection={'date':True,'close':True,'_id':False})
#将数据存入DataFrame格式
df_daily = pd.DataFrame([daily for daily in daily_cursor])
#将date设为index索引
df_daily.set_index(['date'],1,inplace = True)
#计算EMA
#alpha = 2/(N+1)
#EMA(i) = (1-alpha)*EMA[i-1]+alpha*CLOSE[i]
# = alpha*(CLOSE[i]-EMA[i-1]) + EMA[i-1]
index = 0
#短时EMA列表
EMA1=[]
#长时EMA列表
EMA2 =[]
#每天计算短时EMA和长时EMA
for date in df_daily.index:
if index == 0:
#第一天EMA就是当日的close,也就是收盘价
EMA1.append(df_daily.loc[date]['close'])
EMA2.append(df_daily.loc[date]['close'])
else:
#短时EMA和长时EMA
EMA1.append(2/(short+1)*(df_daily.loc[date]['close']-EMA1[index-1])+EMA1[index-1])
EMA2.append(2/(long+1) * (df_daily.loc[date]['close'] - EMA2[index-1]) + EMA2[index-1])
index+=1
#将短时EMA和长时EMA作为DataFrame的数据列
df_daily['EMA1'] = EMA1
df_daily['EMA2'] = EMA2
#计算DIFF,短时EMA - 长时EMA
df_daily['DIFF'] = df_daily['EMA1'] - df_daily['EMA2']
#计算DEA,DIFF的EMA,计算公式为:EMA(DIFF,M)
index = 0
DEA = []
for date in df_daily.index:
if index ==0 :
DEA.append(df_daily.loc[date]['DIFF'])
else:
#M = 9;DEA = EMA(DIFF,9)
DEA.append(2/(m+1)*(df_daily.loc[date]['DIFF']-DEA[index-1]) + DEA[index-1])
index +=1
df_daily['DEA'] = DEA
#计算DIFF与DEA的差值
df_daily['delta'] = df_daily['DIFF'] - df_daily['DEA']
#将delta的移一位,那么前一天的delta就变成了今天的pre_delta,将数据整体向下移动
df_daily['pre_delta'] = df_daily['delta'].shift(1)
#金叉,DIFF上穿DEA,前一日DIFF在DEA下面,当日DIFF在DEA下面
df_daily_gold = df_daily[(df_daily['pre_delta']<=0) & (df_daily['delta']>0)]
#死叉,DIFF下穿DEA,前一日DIFF在DEA上面,当日DIFF在DEA下面
df_daily_dead = df_daily[(df_daily['pre_delta'] >= 0)&(df_daily['delta']<0)]
#保存结果到数据库中
update_requests = []
for date in df_daily_gold.index:
#保存时以code和date为查询条件,做更新或新建,所以对code和date建立索引,通过signal字段表示金叉还是死叉,gold表示金叉
update_requests.append(UpdateOne(
{'code':code,'date':date},
{'$set':{'code':code,'date':date,'signal':'gold'}},
upsert=True))
for date in df_daily_dead.index:
#保存时以code和date为查询条件,做更新或新建,所以对code和date建立索引,通过signal字段表示金叉还是死叉,dead表示死叉
update_requests.append(UpdateOne(
{'code':code,'date':date},
{'$set':{'code':code,'date':date,'signal':'dead'}},
upsert=True))
if len(update_requests)>0:
update_result = DB_CONN['macd'].bulk_write(update_requests,ordered=False)
print('Save MACD ,股票代码:%s,插入:%4d,更新:%4d' %(code,update_result.upserted_count,update_result.modified_count),flush=True)
except:
print('错误发生: %s' % code, flush=True)
traceback.print_exc()
if __name__ == "__main__":
compute_macd('2019-01-01','2019-12-31')
提供外部接口,供回测
def is_macd_gold(code,date):
"""
判断某只股票在某个交易日是否出现MACD金交信号
:param code:股票代码
:param date:日期
:return :True -有金叉信号,False-无金叉信号
"""
count = DB_CONN['macd'].count({'code':code,'date':date,'signal':'gold'})
return count == 1
def is_macd_dead(code, date):
"""
判断某只股票在某个交易日是否出现MACD死叉信号
:param code: 股票代码
:param date: 日期
:return: True - 有死叉信号,False - 无死叉信号
"""
count = DB_CONN['macd'].count({'code': code, 'date': date, 'signal': 'dead'})
return count == 1
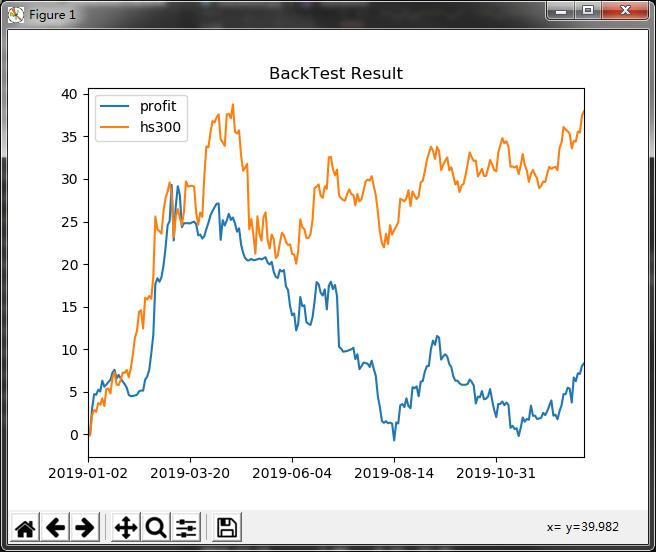
回测结果展示

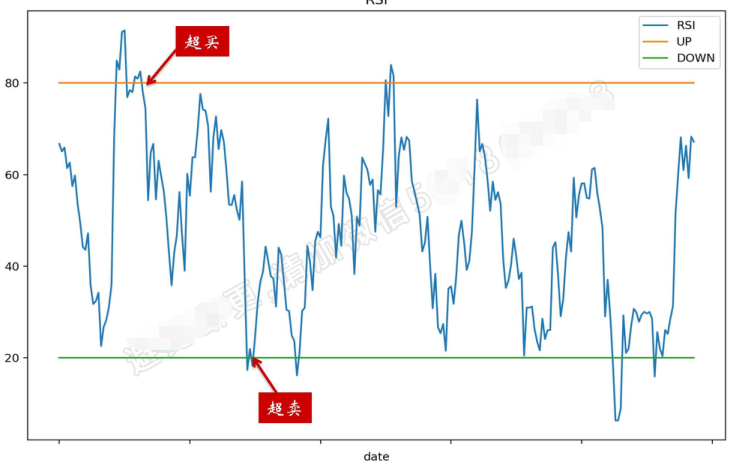
RSI(相对强弱指数)
定义
指的是一定时间窗口内,上涨幅度之和占整体涨跌幅度绝对值之和的比例
表现的是买入意愿相对于总体成交的强弱。当买方意愿达到超买区,意味着有可能会跌了,发出卖出预警,当卖方意愿达到超卖区,意味着有可能涨了,发出买入信号。这都蕴含着盛极而衰、否极泰来的意思。
超买区、超卖区
超卖区:RSI < 20
超买区:RSI > 80
强弱信号
超买:RSI上穿80
超卖:RSI下穿20
计算公式
\]
\]
\]
RSI超买超卖直观展示
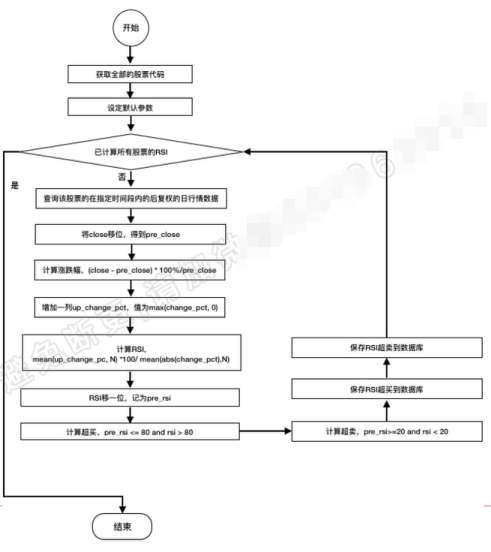
流程图
代码实现
信号计算
from stock_util import get_all_codes,DB_CONN
import pandas as pd
import matplotlib.pyplot as plt
from pymongo import UpdateOne,ASCENDING
import traceback
def compute_rsi(begin_date,end_date):
"""
计算指定时间段内的RSI信号,并保存到数据库中
:param begin_date:开始日期
:param end_date:结束日期
"""
#获取所有股票代码
codes = get_all_codes()
#codes = ['002468']
#计算RSI
N = 12
#计算所有股票的RSI信号
for code in codes:
try:
#获取后复权价格,使用后复权的价格计算RSI
daily_cursor = DB_CONN['daily_hfq'].find(
{'code':code,'date':{'$gte':begin_date,'$lte':end_date},'index':False},
sort=[('date',ASCENDING)],
projection={'date':True,'close':True,'_id':False})
df_daily = pd.DataFrame([daily for daily in daily_cursor])
#如果查询出来的行情数据不足以计算N天的平均值,则不参与计算
# if len(df_daily) < N:
if df_daily.index.size < N:
print('数据量不足:%s' %code,flush= True)
continue
#将日期设置为索引
df_daily.set_index(['date'],drop=True,inplace=True)
#将close移一位作为当日的pre_close
df_daily['pre_close'] = df_daily['close'].shift(1)
#计算当日的涨跌幅:(close- pre_close) * 100/pre_close
df_daily['change_pct'] = (df_daily['close'] - df_daily['pre_close'])*100 / df_daily['pre_close']
#只保留上涨的日期的涨幅
df_daily['up_pct'] = pd.DataFrame({'up_pct':df_daily['change_pct'],'zero':0}).max(1)
#计算RSI
df_daily['RSI'] = df_daily['up_pct'].rolling(N).mean() / abs(df_daily['change_pct']).rolling(N).mean()*100
#移位,记作prev_rsi
df_daily['PREV_RSI'] = df_daily['RSI'].shift(1)
print(df_daily,flush=True)
#超买,RSI下穿80,作为卖出信号
df_daily_over_bough = df_daily[(df_daily['RSI']<80) & (df_daily['PREV_RSI'] >=80)]
#超卖,RSI上穿20,作为买入信号
df_daily_over_sold = df_daily[(df_daily['RSI'] >20) & (df_daily['PREV_RSI'] <=20)]
#保存到数据库,要以code和date创建索引,db.rsi.createIndex({'index':1,'date':1})
update_requests = []
#超买数据,以code和date为key更新数据,signal为over_bought
for date in df_daily_over_bough.index:
update_requests.append(UpdateOne(
{'code':code,'date':date},
{'$set':{'code':code,'date':date,'signal':'over_bought'}},
upsert = True))
#超卖数据,以code和date为key更新数据,signal为over_sold
for date in df_daily_over_sold.index:
update_requests.append(UpdateOne(
{'code':code,'date':date},
{'$set':{'code':code,'date':date,'signal':'over_sold'}},
upsert=True))
if len(update_requests)>0:
update_result = DB_CONN['rsi'].bulk_write(update_requests,ordered=False)
print('Save RSI, 股票代码:%s, 插入:%4d, 更新:%4d' %
(code, update_result.upserted_count, update_result.modified_count), flush=True)
except:
print('错误发生:%s'%code,flush=True)
traceback.print_exc()
if __name__ == "__main__":
compute_rsi('2019-01-01','2019-12-31')
提供外部接口,供回测
def is_rsi_over_sold(code, date):
"""
判断某只股票在某个交易日是出现了超卖信号
:param code: 股票代码
:param date: 日期
:return: True - 出现了超卖信号,False - 没有出现超卖信号
"""
count = DB_CONN['rsi'].count({'code': code, 'date': date, 'signal': 'over_sold'})
return count == 1
def is_rsi_over_bought(code,date):
"""
判断某只股票在某个交易日是出现了超买信号
:param code: 股票代码
:param date: 日期
:return: True - 出现了超买信号,False - 没有出现超买信号
"""
count = count = DB_CONN['rsi'].count({'code':code,'date':date,'signal':'over_bought'})
return count ==1
回测结果展示


注:时间窗口长度、超买、超卖区间的阈值可根据实际情况自行调整
Boll(突破上轨与突破下轨)
定义
Boll是基于统计学的标准差原理
包含三条轨道:
- 上轨:压力线
- 中轨:价格平均线
- 下轨:支撑线
计算公式(N = 20,k =2 )
价格均值
\]
标准差
\]
中轨(盘中实时计算,当日收盘价不稳定,所以计算的是前一天的均价)
\]
上轨
\]
下轨
\]
Boll直观展示

流程图
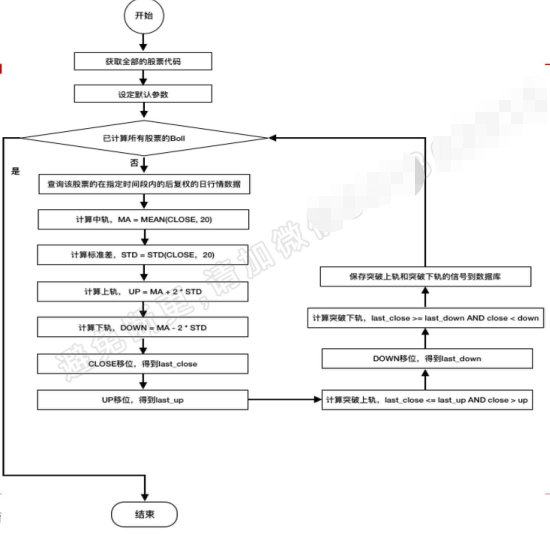
代码实现
信号计算
from stock_util import get_all_codes
from database import DB_CONN
import pandas as pd
from pymongo import ASCENDING,UpdateOne
import traceback
def compute_boll(begin_date,end_date):
"""
计算指定日期内的boll突破上轨和突破下轨信号,并保存到数据库中,方便查询调用
:param begin_date:开始日期
:param end_date:结束日期
"""
#获取所有股票列表
codes = get_all_codes()
#计算每只股票的Boll值
for code in codes:
try:
#获取后复权的价格,使用后复权的价格计算BOLL
daily_cursor = DB_CONN['daily_hfq'].find(
{'code':code,'date':{'$gte':begin_date,'$lte':end_date},'index':False},
sort=[('date',ASCENDING)],
projection={'date':True,'close':True,'_id':False})
df_daily = pd.DataFrame([daily for daily in daily_cursor])
#计算中轨;计算MB,盘后计算,这里用当日的close
df_daily['MB'] = df_daily['close'].rolling(20).mean()
#计算标准差,计算STD20,即20日的标准差
df_daily['std'] = df_daily['close'].rolling(20).std()
print(df_daily,flush=True)
#计算上轨up
df_daily['UP'] = df_daily['MB'] + 2 * df_daily['std']
#计算下轨down
df_daily['DOWN'] = df_daily['MB'] - 2 * df_daily['std']
print(df_daily,flush=True)
#将日期作为索引
df_daily.set_index(['date'],inplace=True)
#将close移动一位,变成当前索引位置的前收
last_close = df_daily['close'].shift(1)
#将上轨移动一位,实现前一日的上轨和前一日的收盘价都在当日了
shifted_up = df_daily['UP'].shift(1)
#计算突破上轨,是向上突破,条件是前一日的收盘价小于前一日上轨,当日收盘价大于当日上轨
df_daily['up_mask'] = (last_close <= shifted_up) & (df_daily['close'] > shifted_up)
#将下轨移动一位,前一日的下轨和前一日的收盘就就都在当日了
shifted_down = df_daily['DOWN'].shift(1)
#突破下轨,向下突破,条件是前一日收盘价大于前一日下轨,当日收盘价小于当日下轨
df_daily['down_mask'] = (last_close >= shifted_down) & (df_daily['close'] < shifted_down)
#对结果进行过滤,只保留向上突破或者向下突破的数据
df_daily = df_daily[df_daily['up_mask'] | df_daily['down_mask']]
#从DataFrame中扔掉不用的数据
df_daily.drop(['close','std','MB','UP','DOWN'],1,inplace=True)
#将信号保存到数据库中
update_requsts = []
#DataFrame的索引为日期
for date in df_daily.index:
#保存数据包括股票代码、日期和信号类型,结合数据集的名字,就表示某只股票在某日
doc = {
'code':code,
'date':date,
#方向,向上突破,UP,向下突破,DOWN
'direction':'up' if df_daily.loc[date]['up_mask'] else 'down'
}
update_requsts.append(UpdateOne(doc,{'$set':doc},upsert=True))
#如有信号数据,将保存到数据库中
if len(update_requsts)>0:
update_result = DB_CONN['boll'].bulk_write(update_requsts,ordered=False)
print('%s ,upserted:%4d,modified:%4d'%(code,update_result.upserted_count,update_result.modified_count),flush=True)
except :
traceback.print_exc()
if __name__ == "__main__":
compute_boll('2019-01-01','2019-12-31')
提供外部接口,供回测
def is_boll_break_down(code,date):
"""
查询某只股票是否在某日出现了突破下轨信号
:param code: 股票代码
:param date: 日期
:return: True - 出现了突破下轨信号,False - 没有出现突破下轨信号
"""
count = DB_CONN['boll'].count({'code':code,'date':date,'direction':'down'})
return count==1
def is_boll_break_up(code,date):
"""
查询某只股票是否在某日出现了突破上轨信号
:param code: 股票代码
:param date: 日期
:return: True - 出现了突破上轨信号,False - 没有出现突破上轨信号
"""
count = DB_CONN['boll'].count({'code':code,'date':date,'direction':'up'})
return count == 1
回测结果展示


获取数据的周期,可以是日、周、月甚至是分钟;上述代码中有N和k两个可变参数
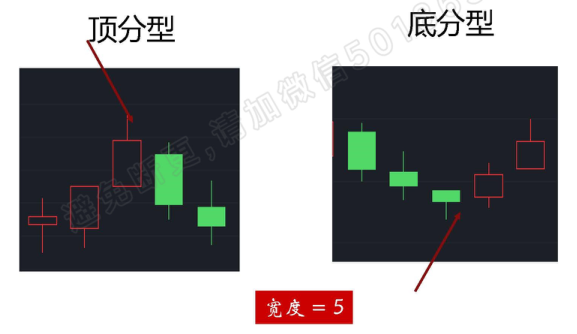
分型(顶分型与底分型)
分型直观展示
#####流程图
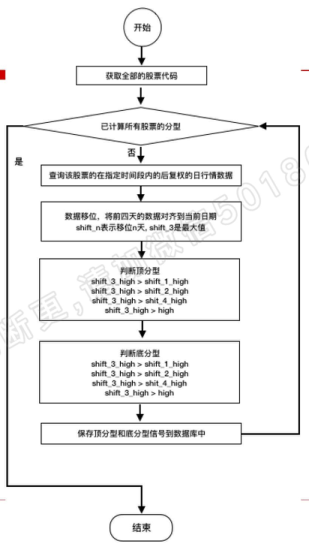
代码实现
信号计算
import pandas as pd
import traceback
from pymongo import ASCENDING,UpdateOne
from stock_util import get_all_codes
from database import DB_CONN
def compute_fractal(begin_date,end_date):
"""
计算给定周期内的分型信号,把结果保存在数据库中
:param begin_date:开始日期
:param end_date:结束日期
"""
#获取所有股票代码
codes = get_all_codes()
#计算每只股票的信号
for code in codes:
try:
#获取后复权的价格,使用后复权价格计算分型信号
daily_cursor = DB_CONN['daily_hfq'].find(
{'code':code,'date':{'$gte':begin_date,'$lte':end_date},'index':False},
sort=[('date',ASCENDING)],
projection={'date':True,'high':True,'low':True,'_id':False})
df_daily = pd.DataFrame([daily for daily in daily_cursor])
#将日期设置为索引
df_daily.set_index(['date'],1,inplace=True)
#通过移位将前两天和后两天对齐到中间一天
df_daily_shift_1 = df_daily.shift(1)
df_daily_shift_2 = df_daily.shift(2)
df_daily_shift_3 = df_daily.shift(3)
df_daily_shift_4 = df_daily.shift(4)
#顶分型,中间日的最高价既大于前两天的价格,又大于后两天的价格
df_daily['up'] = (df_daily_shift_3['high'] > df_daily_shift_1['high']) & \
(df_daily_shift_3['high'] > df_daily_shift_2['high']) & \
(df_daily_shift_3['high'] > df_daily_shift_4['high']) & \
(df_daily_shift_3['high'] > df_daily['high'])
#底分型,中间日的最低价既低于前两天的最低价,又低于后两天的最低价
df_daily['down'] = (df_daily_shift_3['low'] < df_daily_shift_1['low']) &\
(df_daily_shift_3['low'] < df_daily_shift_2['low']) &\
(df_daily_shift_3['low'] < df_daily_shift_4['low']) &\
(df_daily_shift_3['low'] < df_daily['low'])
#只保留出现顶分型和低分型的日期
df_daily = df_daily[(df_daily['up'] | df_daily['down'])]
#抛掉不用的数据
df_daily.drop(['high','low'],1,inplace = True)
print(df_daily)
#将信号保存在数据库中
update_requests = []
for date in df_daily.index:
doc = {
'code':code,
'date':date,
#up:顶分型,down:低分型
'direction':'up' if df_daily.loc[date]['up'] else 'down'
}
#保存时以code、date和direction做条件,那么就需要在这三个字段上建立索引
#db.fractal_signal.createIndex({'code':1,'date':1,'direction':1})
update_requests.append(
UpdateOne(doc,{'$set':doc},upsert=True))
if len(update_requests)>0:
update_result = DB_CONN['fractal_signal'].bulk_write(update_requests,ordered=False)
print('%s ,upserted:%4d,modified:%4d' %(code,update_result.upserted_count,update_result.modified_count),flush=True)
except :
print('错误发生:%s'%code,flush=True)
traceback.print_exc()
if __name__ == "__main__":
compute_fractal('2019-01-01','2019-12-31')
提供外部接口,供回测
#提供外部接口
def is_fractal_up(code,date):
count = DB_CONN['fractal_signal'].count({'code':code,'date':date,'direction':'up'})
return count == 1
"""
查询某只股票在某个日期是否出现顶分型信号
:param code: 股票代码
:param date: 日期
:return: True - 出现顶分型信号,False - 没有出现顶分型信号
"""
def is_fractal_down(code,date):
"""
查询某只股票在某个日期是否出现底分型信号
:param code: 股票代码
:param date: 日期
:return: True - 出现底分型信号,False - 没有出现底分型信号
"""
count = DB_CONN['fractal-signal'].count({'code':code,'date':date,'direction':'down'})
return count == 1
回测结果展示
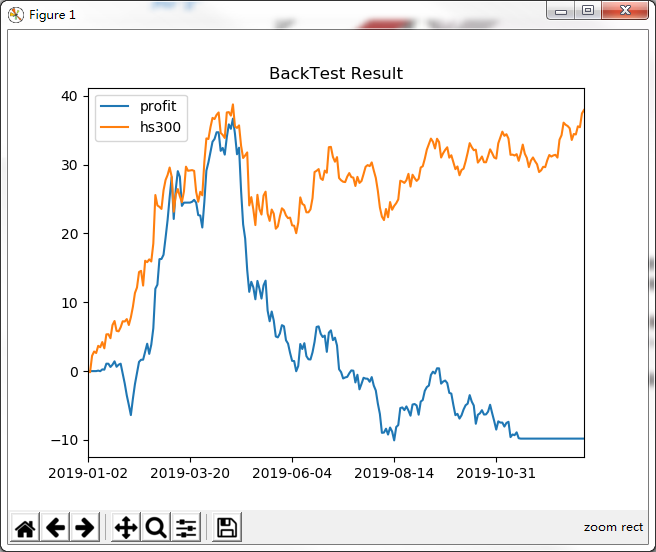

检测宽度:N \(\in (3,5,7,9···)\);符合对称性
就目前的数据利用这四种信号得到回测结果都不尽人意,不排除本地获取、处理数据的问题,但对股票的选股、信号的计算、简单的回测、简单的持仓管理都有了简单的了解。
MACD、RSI、Boll以及分型指标的实现与回测的更多相关文章
- 趋势型指标——MACD
1.简要介绍▪ 计算方法▪ DIFF▪ DEA▪ MACD▪ 构造原理▪ 缺点2.实战技巧3.运用技巧▪ 应用原理▪ 经典用法▪ 实战战法▪ 捕捉卖点▪ 买卖策略▪ 短线实战4.组合指标运用5.一般研 ...
- All I know about A/B Test (1) : 均值型指标与比值(率)型指标的计算区别
因为最近在找实习,所以打算把自己之前学过的关数据分析的知识总结(复习)一下.在总结A/B test时,我发现中文互联网中关于A/B test的总结已经很多了,但是对于均值型指标和比值(率)型指标在设计 ...
- 实战ELK(4)Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- 细菌多位点序列分型(Multilocus sequence typing,MLST)的原理及分型方法
摘 要: 多位点序列分型(MLST)是一种基于核酸序列测定的细菌分型方法,通过PCR扩增多个管家基因内部片段,测定其序列,分析菌株的变异,从而进行分型.MLST被广泛应用于病原菌.环境菌和真核生物中. ...
- Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- MACD、BOLL、KDJ 三大组合精准把握趋势与买卖!
先看示意图,下图是布林线的3个轨道,其他都是股价走势 图1 股价,在布林线上轨.下轨之间运作.准确说,这话是不符合逻辑的,不是先有的轨道,然后股价再按照轨道运动.因为轨道是跟股价同时变化的.但是,股价 ...
- Efficient algorithms for polyploid haplotype phasing 多倍体单体型分型的有效算法
背景:单倍型的推断,或沿着相同染色体的等位基因序列,是遗传学中的基本问题,并且是许多分析的关键组分,包括混合物图谱,通过下降和插补识别身份区域. 基于测序读数的单倍型定相引起了很多关注. 已经广泛研究 ...
- z = z*z + c的分型图如何画
使用python的图形库. 环境:conda+jupyter notebook 代码如下: import numpy as np from PIL import Image from numba im ...
- PAT (Advanced Level) Practice 1019 General Palindromic Number (20 分) (进制转换,回文数)
A number that will be the same when it is written forwards or backwards is known as a Palindromic Nu ...
- LinkedIn的即时消息:在一台机器上支持几十万条长连接
最近我们介绍了LinkedIn的即时通信,最后提到了分型指标和读回复.为了实现这些功能,我们需要有办法通过长连接来把数据从服务器端推送到手机或网页客户端,而不是许多当代应用所采取的标准的请求-响应模式 ...
随机推荐
- 1 前端知识学习-初始Web和Web标准
0️⃣ 初始Web和Web标准 Web Web(World Wide Web) 即全球广域网.也成为万维网.我们常说的Web端就是网页端. 网页 网页是构成网站的基本元素.网页主要由文字.图像 ...
- Javascript 方法有多个参数有默认值,但是只想为其中某个参数赋值
例子: function log(a, b = 2, c = 3, d = 4) { console.log(a, b, c, d) } log(1); // output: 1 2 3 4 log( ...
- SpringBoot - [00] 注解大全
原文链接:https://mp.weixin.qq.com/s/DgNhohtJyEq4vMGEzqrP8A @SpringBootApplication 这个注解用于标识一个SpringBoot应用 ...
- 基于Maxmspjitter的基础【pixel shader】绘制模板Patcher
间断性接触Maxmspjitter已经有6个年头了,是时候总结一些常用的.基础的知识以及它的应用,不过笔者自认为还是处于初学者阶段,望高人多多指教. 开始 这一次就以jitter模块中通用处理图像节点 ...
- 详解vue-router基本使用
来源:https://m.jb51.net/article/111499.htm 本篇文章主要介绍了详解vue-router基本使用,详细的介绍了vue-router的概念和用法,有兴趣的可以了解 ...
- FastAPI 查询参数完全指南:从基础到高级用法 🚀
title: FastAPI 查询参数完全指南:从基础到高级用法 date: 2025/3/6 updated: 2025/3/6 author: cmdragon excerpt: 探讨 FastA ...
- 【Python】一键提取inp文件结构的脚本
inp=input("输入文件路径:") # print(type(inp)) ex_txt=inp+'-Struct.inp' inp=inp+'.inp' import re ...
- 使用 vscode-jest 插件
vscode-jest [error] Abort jest session: Not able to auto detect a valid jest command: multiple candi ...
- [源码系列:手写spring] IOC第二节:BeanDefinition和BeanDefinitionRegistry
主要内容 BeanDefinition:顾名思义,就是类定义信息,包含类的class类型.属性值.方法等信息. BeanDefinitionRegistry:添加BeanDefinitionRegis ...
- Url base64加密
class UrlEncryption { /** * base64编码 * * @param string * @return string */ public static function en ...