Spark Web UI 监控详解
Spark集群环境配置
我们有2个节点,每个节点是一个worker,每个worker上启动一个Executor,其中Driver也跑在master上。每个Executor可使用的核数为2,可用的内存为2g,集群中所有Executor最大可用核数为4。
conf/spark-defaults.conf 部分参数配置如下:
spark.master spark://Master:7077
spark.executor.memory 2g
spark.executor.cores 2
spark.cores.max 4
在提交jar包的时,按照需求分配executor的核数和memory数给不同的应用,若某个应用占用了所有的核和内存,剩下的应用只能等待这个程序执行完毕释放资源后才可执行。
conf/spark-env.sh 部分参数配置如下:
export SPARK_WORKER_CORES=2
export SPARK_WORDER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
执行节点负载均衡问题
比如启动四个节点,但是在处理数据的时候负载不均衡,只有两个节点的使用率很高。可以推测与分区数有关,测试数据集为267MB,hdfs中默认的数据分片大小为128MB,约有两个分区。推测只有两个分区能拿到数据进行计算,所以将hdfs的数据分片大小改为64MB,这样约有4个分区,与集群中的Executor数目相符。经测试证明,负载不均衡的问题得到解决。
修改配置文件hdfs-site.xml,将block size设置为64MB
<property>
<name>dfs.block.size</name>
<value>67108864</value> 说明:64M=64*1024*1024
</property>
8080
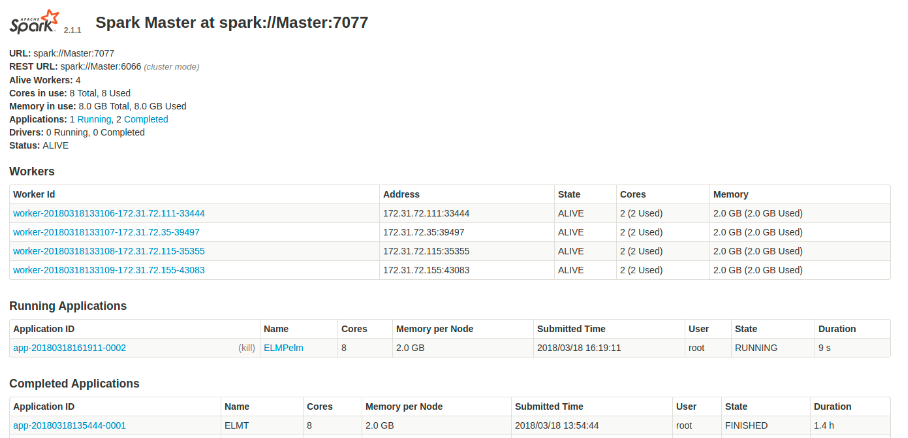
如上图所示,此页面自上而下包括:
spark版本信息,
spark master 的URL(worker用来连接此master的URL)
worker的数量:4
所有worker节点中可用和在用的core(查看资源的使用情况,参考是否适合再启动一个应用等)
所有worker节点中可用和在用的memory(如上)
正在运行和已经完成的应用数量
master当前状态
workers部分
- 展示集群中每个worker的位置,到当前状态,内核使用情况,内存使用情况
(通过查看内核和内存的用量情况确定是否足够运行一个新的应用)
- 点击workerID进入worker的detail页面会显示与该worker更详细的信息
(理想情况下,所有worker节点使用的内核数和内存应该是相同的,如果出现使用率不同的情况,说明集群资源未平均分配,应用未最佳化运行,需停止所有应用重新启动集群)
Running/Completed Application部分
- 分别展示在运行和已经运行完的应用信息,包括名称,获得的资源,开始时间,所有者,已运行时间,目前状态(RUNNING/FINISHED/结束原因)
(若state显示WAITING,则说明Spark对于应用没有足够的内存或内核,将保持等待直到有足够资源可用,有几种情况,一是直到已经在运行的一个应用完成运行,二是增加分配给spark worker的资源,三是将少应用的请求资源)
- 点击ApplicationID进入detail页面会显示看到关于该应用运行时的详细信息,包括参与的worker/使用的资源数/日志等
(如果一个任务失败或抛出了异常,可以查看stderr文件来调试问题)
4040
localhost:4040(当应用在运行中的时候可以访问,一旦应用执行结束该端口关闭不可访问)
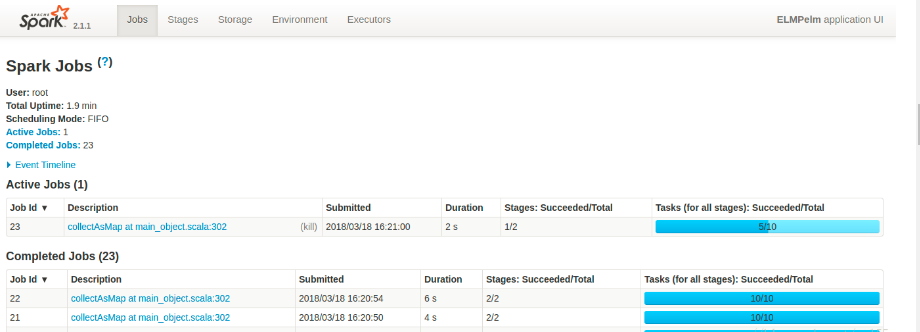
如下图,显示基本的运行时间,调度模式(FIFO为先进先出),不状态中作业的统计量,并显示正在运行/已经完成/运行失败的spark作业较为详细的信息列表,例如,Job的提交时间/运行时间/目前为止每个Job完成的Stage和Task数量等
(从运行时间项可以观察到,若某一个Job花费时间异常,可以把问题缩小到该Job下的Stage或者Task)
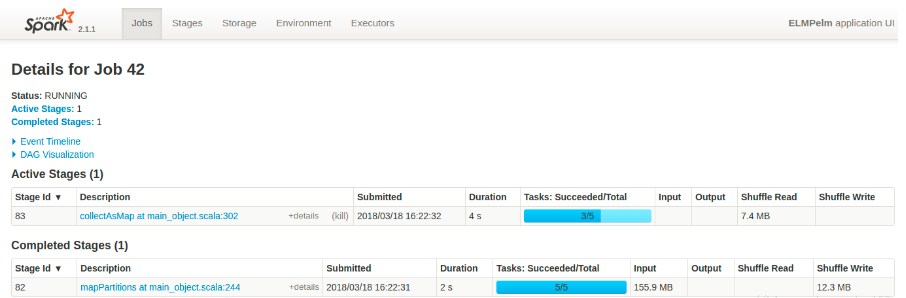
点击某JobID,进入detail页面显示如下信息:
该Job当前状态
活跃/延迟/已完成的Stage数量
该Job的事件时间线
[spark为该Job生成的DAG的可视化呈现]
表格部分的信息有助于定位性能问题,检查Duration列是否存在运行时间异常的Stage,Tasks表明一个Stage内的并行量(根据集群大小,太少或太多可能导致性能问题)。数据Shuffle会对应用性能造成负面影响,所以要最小化Shuffle Read和Write数量。
DGA可视化

Stage
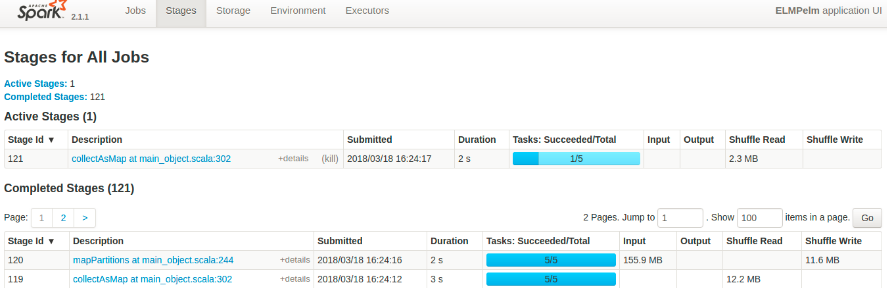
点击某Stage,进入detail页面显示如下信息。
Summary 部分:
若任务持续时间在任一个四分位处过高,则说明有问题。可能是分开太大,也可能是数据Shuffle的负面效应。也可以检查GC活动是否影响性能。
Executor的聚合信息部分:
可以有效找出处理缓慢的任务,检查GC时间
Locality Level(数据的区域级别):
标明任务所处理的数据是缓存在内存中的(PROCESS_LOCAL),还是本地读取(NODE_LOCAL),还是来自于集群中的任意节点(ANY)。以PROCESS_LOCAL级别处理数据是极快的。
事件时间线监控,显示了每个worker节点上并行运行了多少个任务,已经增加任务完成所需的总时间
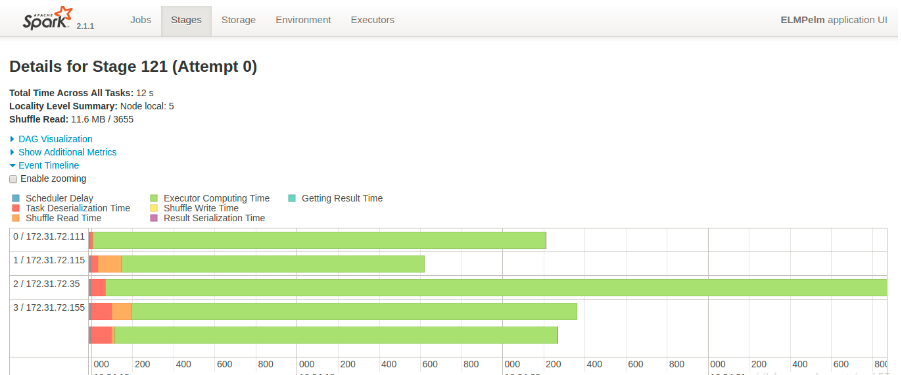
Storage页显示Spark应用缓存在内存或硬盘中的数据量,提供每一个持久化RDD的信息。(可以是以Hive表格或者是RDD的形式缓存在内存中)
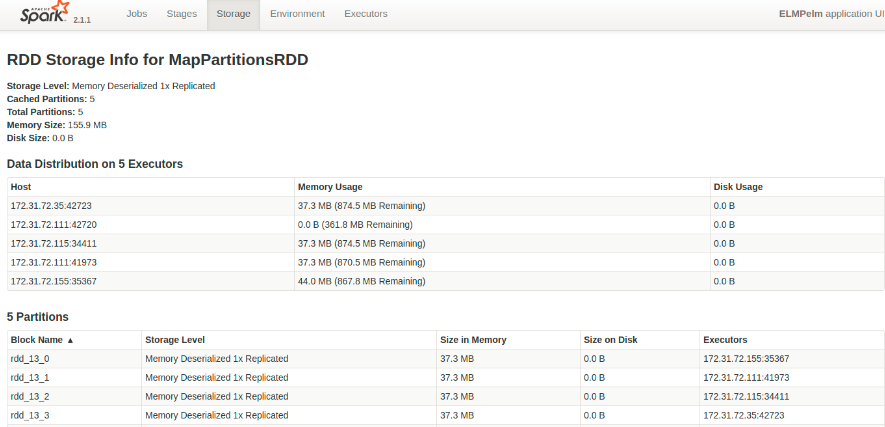
Storage Level展示数据集如何缓存,以及所缓存数据的副本数量。
点击具体的RDDID,进入detail页。包括:
缓存RDD的概要信息
在不同EXecutor上的分布(每个Executor上需要的内存)
分块信息,如存储级别/位置/每个缓存RDD分块大小
Enviroment页面显示不同环境和配置变量的值:

Executor显示Spark为该应用创建的执行者的概要信息:
Storage Memory表示缓存数据所预留的和所使用的内存量(若内存小于正在尝试缓存的数据,则会出现性能问题)
Shuffle的读写都是昂贵的,如果这两个值过大,应该重构应用代码或者调整Spark参数减少Shuffling

18080
localhost:18080(spark的历史管理中心,包含所有已经运行完成的Application及其详细信息)
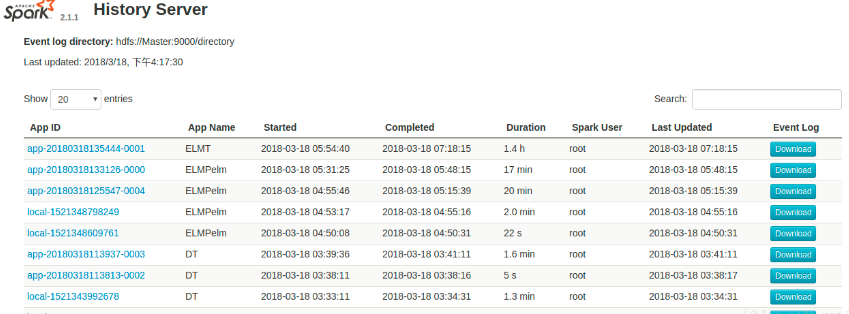
点击具体的APP ID 展现的页面结构与4040相同
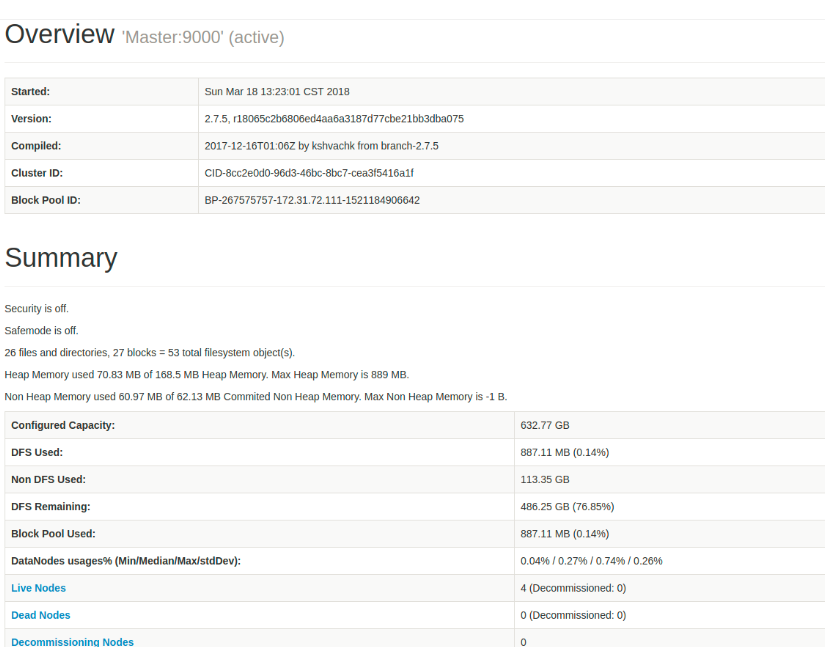
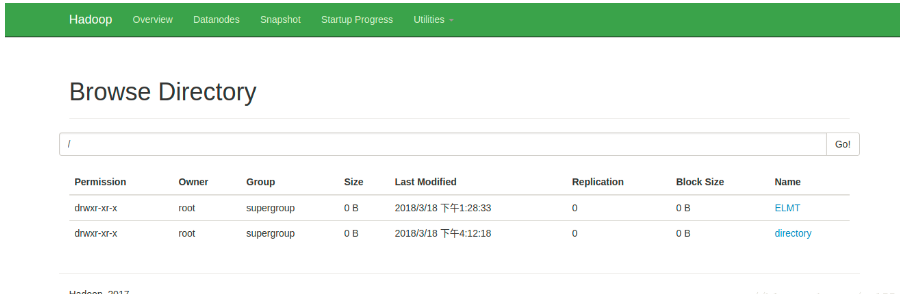
50070
- master:50070 访问namenode的hdfs web UI监控页面
(理想情况下,Summary下的表格右边是有正常数据的而不是0)
- 查看已经启动的datanode信息

- 查看文件目录
总结
本文主要介绍spark webui相关的监控页面指标信息。在我们排查问题,做性能优化时,了解spark监控项可以帮我们快速定位问题的症结,因而需要我们对相关监控页面的地址以及里面的监控项要非常了解。
Spark Web UI 监控详解的更多相关文章
- yarn web ui 参数详解
我们经常使用yarn调度,但是我们是否对调度队列显示参数真正了解呢? 下面我们来一一看看这些参数都是做什么用的,代表什么意思 hadoop是通过队列管理集群资源,翻开集群Web UI,找到Sc ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- Java web.xml 配置详解
在项目中总会遇到一些关于加载的优先级问题,近期也同样遇到过类似的,所以自己查找资料总结了下,下面有些是转载其他人的,毕竟人家写的不错,自己也就不重复造轮子了,只是略加点了自己的修饰. 首先可以肯定的是 ...
- [深入学习Web安全](5)详解MySQL注射
[深入学习Web安全](5)详解MySQL注射 0x00 目录 0x00 目录 0x01 MySQL注射的简单介绍 0x02 对于information_schema库的研究 0x03 注射第一步—— ...
- java web.xml配置详解
1.启动一个WEB项目的时候,WEB容器会去读取它的配置文件web.xml,读取<listener>和<context-param>两个结点. 2.紧急着,容创建一个Servl ...
- web.xml文件详解
web.xml文件详解 Table of Contents 1 listener. filter.servlet 加载顺序 2 web.xml文件详解 3 相应元素配置 1 listener. f ...
- java web.xml配置详解(转)
源出处:java web.xml配置详解 1.常规配置:每一个站的WEB-INF下都有一个web.xml的设定文件,它提供了我们站台的配置设定. web.xml定义: .站台的名称和说明 .针对环境参 ...
- javaweb web.xml文件详解
web.xml文件详解 前言:一般的web工程中都会用到web.xml,web.xml主要用来配置,可以方便的开发web工程.web.xml主要用来配置Filter.Listener.Servlet等 ...
- Asp.net中web.config配置文件详解(一)
本文摘自Asp.net中web.config配置文件详解 web.config是一个XML文件,用来储存Asp.NET Web应用程序的配置信息,包括数据库连接字符.身份安全验证等,可以出现在Asp. ...
随机推荐
- Java 开发者必备:一文解决 AES 加密中的“非法密钥大小”异常
彻底告别 java.security.InvalidKeyException,轻松应对不同 JDK 版本 引言 在 Java 开发过程中,我们经常会遇到各种各样的安全相关的问题.其中一个常见的问题是当 ...
- Linux input 子系统详解
1. 模块概述 1.1.相关资料和代码研究 drivers/input/ include/uapi/linux/input-event-codes.h 2. 模块功能 linux核心的输入框架 3. ...
- Visual Studio C++ 安装以及使用教程
官网下载网址 https://visualstudio.microsoft.com/zh-hans/ Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (micr ...
- JuiceFS 在多云架构中加速大模型推理
在大模型的开发与应用中,数据预处理.模型开发.训练和推理构成四个关键环节.本文将重点探讨推理环节.在之前的博客中,社区用户 BentoML 和贝壳的案例提到了使用 JuiceFS 社区版来提高模型加载 ...
- IDEA 2023.2 最新安装使用教程(附激活码,亲测好用)
申明:本教程 IDEA 补丁.补丁均收集于网络,请勿商用,仅供个人学习使用,如有侵权,请联系作者删除.若条件允许,希望大家购买正版 ! idea激活码使用教程 Step1 第一步下载IDEA软件 ID ...
- 一个Java类在运行时候,变量是怎么在JVM中分布的呢?
JVM学习第三篇思考:一个Java类在Jvm内存中是怎么存在的 又名:Java虚拟机的内存模型(JMM)是什么样的. 通过前面两篇文章的学习,我们知道了一个Java类的生命周期及类加载器.我们可以得到 ...
- python 接口传递字符串,特殊字符url编码
from urllib.parse import quote aaa = "+xxxx" quote(aaa)
- LoRA大模型微调的利器
LoRA模型是小型的Stable Diffusion模型,它们对checkpoint模型进行微小的调整.它们的体积通常是检查点模型的10到100分之一.因为体积小,效果好,所以lora模型的使用程度比 ...
- 【YashanDB数据库】yasql登录有特殊字符@导致无法登录
问题备机 Linux bash shell环境下,使用yasql登录数据库没有使用转义导致登录失败.报错信息如下 问题分析 linux特殊字符转义问题,多加几层转义可以解决问题. 解决办法 su - ...
- 从Workload中优雅隔离Pod
线上集群中,业务跑着跑着,突然发现有个Pod上出现大量错误日志,其他的Pod是正常的,该如何处理呢? 直接删除Pod? 这样不便于保留现场,可能会影响判断问题的根因 让业务方忍一会,先排查下问题? 会 ...