Open-RAG:将开源LLM模型集成为高效RAG模型 | ENMLP'24
本文是对公开论文的核心提炼,旨在进行学术交流。如有任何侵权问题,请及时联系号主以便删除。
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models

创新性
\({\tt Open-RAG}\) 具备以下特点:
- 将任意稠密的
LLM转变为参数高效的稀疏专家混合(sparse mixture of experts,MoE)模型,能够处理复杂的推理任务,包括单步和多步查询。 - 特别地训练模型应对看似相关但实际上具有误导性的挑战性干扰,同时仅在适配器中扩展
MoE,保持模型的规模。 - 通过结合结构学习、架构转换和基于反思的生成,利用潜在嵌入学习动态选择相关专家并有效整合外部知识,以实现更准确和上下文支持的响应生成及其有效性的估计。
- 通过一种混合自适应检索方法,以确定检索的必要性,并在性能提升与推理速度之间取得平衡。
内容概述
检索增强生成(Retrieval-Augmented Generation,RAG)能够提高大型语言模型(Large Language Models,LLMs)的准确性,但现有方法往往在有效利用检索证据方面表现出有限的推理能力,尤其是在使用开源LLMs时。
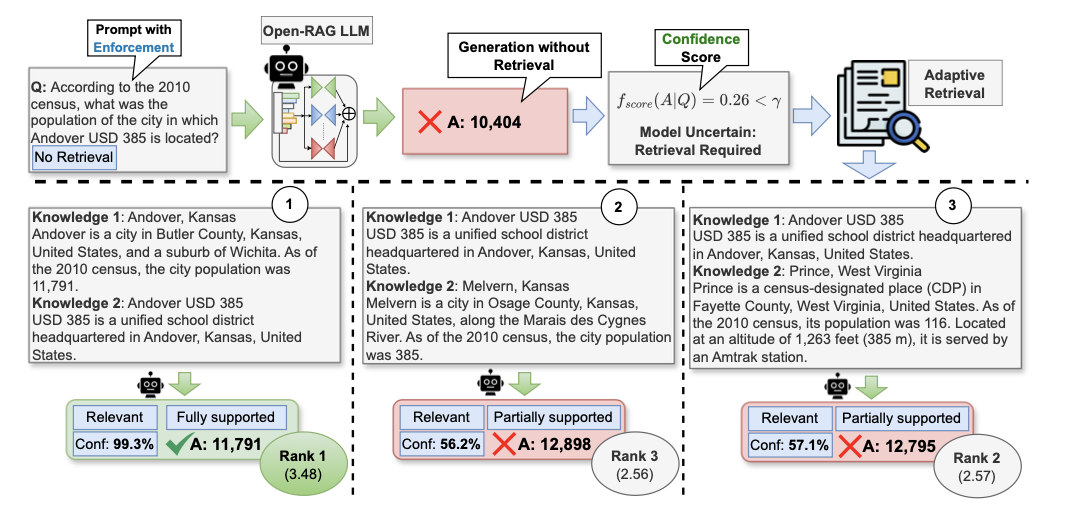
论文提出 \({\tt Open-RAG}\) ,旨在增强开源LLMs中RAG的推理能力。为了控制开源LLMs的行为,生成更具上下文支持的响应,采用来自Self-RAG的基于反思的生成方法,用四种特殊的反思标记类型增强输出词汇(对应上图中的蓝色部分):检索(Retrieval)、相关性(Relevance)、基础(Grounding)和实用(Utility)。
将 \({\tt Open-RAG}\) LLM 定义为一个模型 \(\mathcal{M}_{G}\) ,该模型在给定输入查询 \(q\) 的情况下,目标生成一个包含 \(m\) 个标记的输出序列 \(o = [o_1, o_2, ..., o_m]\) ,其处理过程如下:
在训练过程中,模型学习生成指示是否需要检索以回答 \(q\) 的检索标记([
RT]/[NoRT])。在推理过程中,则采用混合自适应检索方案,综合检索标记和模型置信度判断是否需要检索。如果不需要检索, \(\mathcal{M}_{G}\) 仅使用
LLM的参数知识生成响应(即将 \(o\) 作为 \(y_{pred}\) 返回)。如果需要检索,对于来自外部知识源 \(D = \{d_i\}_{i=1}^{N_d}\) 的单步或多步,使用用户定义的冻结检索器 \(R\) 来检索前 \(k\) 个文档 \(S = \{s_t\}_{t=1}^{k}\) ,其中每个 \(s_t\) 由 \(\{r_j\}_{j=1}^{N_H}\) 组成, \(r_j \in D\) , \(N_H\) 表示步数。
对于每个检索到的内容 \(s_t\) , \(\mathcal{M}_{G}\) 生成一个相关性标记、输出响应 \(y_t\) 、一个基础标记和一个实用标记。
相关性标记([
Relevant/Irrelevant])指示 \(s_t\) 是否与 \(q\) 相关。基础标记([
Fully Supported/Partially Supported/No Support])指示 \(y_t\) 是否得到 \(s_t\) 的支持。实用标记([U:
1]-[U:5])定义 \(y_t\) 对 \(q\) 的有用程度。
并行处理每个 \(s_t\) 并通过对它们(即所有 \(y_t\) )进行排名来生成最终答案 \(y_{pred}\) ,排名依据是对应预测的相关性、基础和实用标记的归一化置信度的加权和。
Open-RAG
数据收集
为了使 \({\tt Open-RAG}\) 能够处理无检索查询,以及需要检索的单步和多步查询,使用各种类型的任务和数据集构建训练数据。给定原始数据集中的输入输出数据对 ( \(q\) , \(y\) ),通过利用真实标签注释或LLM \(C\) 生成标记来增强数据,从而创建监督数据。
如果 \(C\) 添加的相应检索标记是 [RT],则会进一步增强数据,根据以下方式创建三种不同的新标记。
- 使用 \(R\) 检索前 \(k\) 个文档 \(S\) 。对于每个检索到的文档 \(s_t\) , \(C\) 评估 \(s_t\) 是否相关,并返回相关性标记。为了解决单步和多步查询的问题,为数据管道配备了一个步数统一启发式:如果至少有一个段落 \(\{r_j\} \in s_t\) 是相关的,则将相关性标记添加为 [
Relevant],否则使用 [Irrelevant]。 - 当预测为 [
Relevant] 时,为了使 \(\mathcal{M}_{G}\) 能够在 \(s_t\) 中更细致地区分有用和干扰上下文,设计了一个数据对比启发式:(i)对于单步RAG数据集,直接使用 \(C\) 来标记基础标记;(ii)对于多步RAG数据集,如果所有段落 \(\{r_j\} \in s_t\) 被单独预测为 [RT],那么将 [Fully Supported] 添加为基础标记;否则,使用 [Partially Supported]。 - 无论相关性标记的预测如何,都使用 \(C\) 为 \(y\) 提供相对于 \(q\) 的实用分数。
参数高效的MoE微调
RAG任务本质上是复杂的,由单一(单步)或多个(多步)段落的查询等各种组件组成。根据这些复杂性选择性地利用模型的不同部分,可以促进对多样化输入上下文的更自适应和更细致的推理能力。
因此,论文采用稀疏升级(sparse upcycling)将 \(\mathcal{M}_{G}\) 转换为MoE架构,并根据需要动态学习为每个具有多样化复杂性的查询(例如,单步/多步)选择性激活最合适的专家。这种选择性激活是通过前面量身定制的训练数据进行学习(微调)的,确保模型能够区分有用信息和误导信息。
稀疏MoE \({\tt Open-RAG}\) 模型通过一个参数高效的MoE转换块增强了密集主干LLM的FFN层,该转换块由一组专家层 \(\mathbf{E} = \{\mathcal{E}_e\}_{e=1}^{N_E}\) 以及有效的路由机制组成。
每个专家层包含一个复制的原始共享FFN层权重,通过具有参数 \(\theta_e\) 的适配器模块 \(\mathcal{A}_{e}\) 进行了适配。为了确保参数高效性,在每个专家中保持FFN层不变,仅训练适配器模块 \(\mathcal{A}_{e}\) 。通过这种方式,只需存储一个FFN副本,保持模型大小不变,除了适配器和路由模块中参数的增加。其余层,例如Norm和Attention,则从密集模型中复制。
\mathcal{A}_{e}(x) = \sigma(x W_{e}^{down}){W_{e}^{up}} + x.
\end{equation}
\]
对于给定输入 \(x\) ,路由模块 \(\mathcal{R}\) 根据注意力层的归一化输出 \(x_{in}\) 从 \(N_E\) 个专家中激活 \(\texttt{Top-}k\) 个专家。考虑 \(W_{|\cdot|}\) 表示相应专家模块的权重,将路由模块定义如下:
\mathcal{R}(x_{in}) = \text{Softmax}(\texttt{Top-}k(W_{\mathcal{R}} \cdot x_{in}))
\end{equation}
\]
\({\tt Open-RAG}\) 模型的高效性源于以下设置: \(|\theta_e| = |W_{e}^{down}| + |W_{e}^{up}| \ll |\phi_o|\) ,其中在微调过程中保持密集LLM的 \(\phi_o\) 不变。
最后,将参数高效的专家模块的输出 \(y\) 表达为:
y = \sum_{e=1}^{N_E} \mathcal{R}(x)_e \mathcal{A}_e (\mathcal{E}_e(x)).
\end{equation}
\]
混合自适应检索
由于LLM具有不同的参数知识,论文提出了一种混合自适应检索方法,该方法基于模型信心提供两种阈值选择,按需检索并平衡性能和速度。
在训练过程中, \(\mathcal{M}_{G}\) 学习生成检索反映标记([RT] 和 [NoRT])。在推理时,通过将 [NoRT] 添加到输入中,测量基于强制不检索设置的输出序列 \(o\) 的信心,从而得出 \(\hat{q} = q \oplus \texttt{[NoRT]}\) 。设计了两种不同的信心分数 \(f_{|\cdot|}\) : (i) \(f_{minp}\) ,即单个标记概率的最小值,以及 (ii) \(f_{meanp}\) ,即生成序列中单个标记概率的几何平均值。
\label{eq:meanpscore}
f_{minp}(o | \hat{q}) &= \min_{i=1}^{m} p(o_i|\hat{q}, o_{<i}) \\
f_{meanp}(o| \hat{q}) &= \sqrt[m]{\prod_{i=1}^{m} p(o_i|\hat{q}, o_{<i})}
\end{align}
\]
通过可调阈值 \(\gamma\) 控制检索频率,当 \(f_{|\cdot|}<\gamma\) 时进行检索。
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

Open-RAG:将开源LLM模型集成为高效RAG模型 | ENMLP'24的更多相关文章
- C#开发BIMFACE系列40 服务端API之模型集成
BIMFACE二次开发系列目录 [已更新最新开发文章,点击查看详细] 随着建筑信息化模型技术的发展,越来越多的人选择在云端浏览建筑模型.现阶段的云端模型浏览大多是基于文件级别,一次只可以浏览一 ...
- 模型验证与模型集成(Ensemble)
作者:吴晓军 原文:https://zhuanlan.zhihu.com/p/27424282 模型验证(Validation) 在Test Data的标签未知的情况下,我们需要自己构造测试数据来验证 ...
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- CMMI能力成熟度模型集成的过程域
什么是CMMI CMMI全称是Capability Maturity Model Integration, 即能力成熟度模型集成,是由美国国防部(Office of the Secretary of ...
- CMMI 能力成熟度模型集成
关于CMMI的过程域,请参考 CMMI能力成熟度模型集成的过程区域 1.CMMI/SPCA概述 CMM是“能力成熟度模型(Capability Maturity Model)”的英文简写,该模型由美国 ...
- SAP开源的持续集成-持续交付的解决方案
SAP开源的持续集成/持续交付的解决方案: (1) 一个叫做piper的github项目,包含一个针对Jenkins的共享库和一个方便大家快速搭建CI/CD环境的Docker镜像: (2) 一套SAP ...
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
- 【实践】如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)
如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统) 一.环境配置 1. Python3.7.x(注:我用的是3.7.3.安 ...
- 初识TMMi——测试成熟度模型集成
利用零碎的时间,粗略了解了一下TMMi V1.2,整理一下学习笔记跟大家分享一下. 本文分为四个部分,分别为TMMi概述.TMMi结构.成熟度级别和过程域.TMMi实施周期,希望能够帮助大家更好的理解 ...
- 腾讯 angel 3.0:高效处理模型
腾讯 angel 3.0:高效处理模型 紧跟华为宣布新的 AI 框架开源的消息,腾讯又带来了全新的全栈机器学习平台 angel3.0.新版本功能特性覆盖了机器学习的各个阶段,包括:特征工程.模型训练. ...
随机推荐
- Ubuntu 设置中文
首先安装中文语言包: sudo apt install -y language-pack-zh-hans 接下来在 ~/.zshrc 或 ~/.bashrc 中添加如下内容: export \ LAN ...
- 基于PaddleOCR + NLP实现证件识别
基于PaddleOCR + NLP实现证件识别 PaddleOCR识别 paddleOCR安装 安装 anconda虚拟环境(可参考yolov5的安装教程) paddleOCR识别 PaddleNLP ...
- P7706 「Wdsr-2.7」文文的摄影布置
题意 给定长度为 \(n\) 的数组 \(a\) 和 \(b\),支持单点修改,\(q\) 次区间查询 \(\max_{l\le i<k\le r} \{a_i + a_k - \min_{i& ...
- A4纸尺寸
A4纸尺寸 A4纸尺寸:210×297: A3纸尺寸:297×420: A2纸尺寸:420×594: A1纸尺寸:594×841: A0纸尺寸:841×1189: 备注:长(mm)×宽(mm) 单位: ...
- [33](CSP 集训)CSP-S 模拟 4
A 商品 对于任意一组相邻的数 \((l,r)\ (l\le r)\),可以发现,不管怎么压缩,都会有 \(l\le r\),也就是说,相邻两个数的大小关系是不变的 那么我们就可以把 \(\sum(| ...
- 冒泡排序和一点优化(php)
function maopao($arr){ $len = count($arr);//获取数组的长度 //有多少个数组元素就最多就要排n-1次 for ($j=0;$j<$len-1;$j++ ...
- Linux系统启动速度优化工具systemd-analyze
systemd-analyze简介 systemd-analyze是Linux自带的分析系统启动性能的工具. systemd-analyze可使用的命令: systemd-analyze [OPTIO ...
- USB 端点和管道的区别
在USB体系架构中,经常会混用USB端点和USB管道的概念,包括本人也经常混用.但严格来说它们是两个不同的概念,具体表现在: 端点是USB设备端的概念,是真实的特理设备上的概念,其特性是通过端点描述符 ...
- 推荐一款轻量级 eBPF 前端工具 ply
1 Overview ply 是 eBPF 的 front-end 前端工具之一,专为 embedded Linux systems 开发,采用 C 语言编写,只需 libc 和内核支持 BPF 就可 ...
- 来参与Oracle VS openGauss 在线研讨,与盖国强老师、李国良教授面对面!
11月11日下午14点,墨天轮社区邀请到两位数据库领域的巅峰人物:Oracle ACED 盖国强老师,和来自清华大学计算机与技术系的李国良教授,他们将进行一场"巅峰对话". 墨天轮 ...