星型数据仓库olap工具kylin介绍和简单使用示例
本文转载自:https://www.cnblogs.com/hsydj/p/4515057.html
星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍
数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每个大公司都花费数百万每年的资金进行数据仓库的运维.
本文介绍一个基于hadoop的数据仓库, 它基于hadoop(HIVE, HBASE)水平扩展的特性, 客服传统olap受限于关系型数据库数据容量的问题. Kylin是ebay推出的olap星型数据仓库的开源实现.
首先请安装Kylin, 和它的运行环境(Hadoop, yarn, hive, hbase). 如果安装成功, 登陆(http://<KYLIN_HOST>:7070/), 用户名:ADMIN, 密码(KYLIN). 安装过程请参考(http://kylin.incubator.apache.org/download/, 注意下载编译后的二进制包, 免去很多编译烦恼).
在创建数据仓库前, 我们先聊一下, 什么是数据仓库.
从业务过程的角度考虑, 信息系统可以划分为两个主要类别, 一类用于支持业务过程的执行, 代表作品是mysql; 另一类用于支持业务过程的分析, 代表作品是hive, 还有就是今天的主角kylin.
首先, 数据仓库的设计
下图展示了一个简单的基于订单流程中事实和维度的星型模型.

这是一个典型的星型结构, 订单的事实表有3个度量值(messures)(订单数量, 订单金额, 和订单成本); 另外有4个度量维度(dimession), 分别是时间, 产品, 销售员, 客户. 这里时间以天为单位, 这里注意day_key必须是(YYYY-MM-DD)格式(这是kylin的规定).
其次, 根据数据仓库的设计创建hive表
1. 创建事实表并插入数据
DROP TABLE IF EXISTS DEFAULT.fact_order ;
create table DEFAULT.fact_order (
time_key string,
product_key string,
salesperson_key string,
custom_key string,
quantity_ordered bigint,
order_dollars bigint,
cost_dollars bigint
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'fact_order.csv' overwrite into table DEFAULT.fact_order;
fact_order.csv
2015-05-01,pd001,sp001,ct001,100,101,51 2015-05-01,pd001,sp002,ct002,100,101,51 2015-05-01,pd001,sp003,ct002,100,101,51 2015-05-01,pd002,sp001,ct001,100,101,51 2015-05-01,pd003,sp001,ct001,100,101,51 2015-05-01,pd004,sp001,ct001,100,101,51 2015-05-02,pd001,sp001,ct001,100,101,51 2015-05-02,pd001,sp002,ct002,100,101,51 2015-05-02,pd001,sp003,ct002,100,101,51 2015-05-02,pd002,sp001,ct001,100,101,51 2015-05-02,pd003,sp001,ct001,100,101,51 2015-05-02,pd004,sp001,ct001,100,101,51
2. 创建天维度表day_dim
DROP TABLE IF EXISTS DEFAULT.dim_day ;
create table DEFAULT.dim_day (
day_key string,
full_day string,
month_name string,
quarter string,
year string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_day.csv' overwrite into table DEFAULT.dim_day;
dim_day.csv
2015-05-01,2015-05-01,201505,2015q2,2015 2015-05-02,2015-05-02,201505,2015q2,2015 2015-05-03,2015-05-03,201505,2015q2,2015 2015-05-04,2015-05-04,201505,2015q2,2015 2015-05-05,2015-05-05,201505,2015q2,2015
3. 创建售卖员的维度表salesperson_dim
DROP TABLE IF EXISTS DEFAULT.dim_salesperson ;
create table DEFAULT.dim_salesperson (
salesperson_key string,
salesperson string,
salesperson_id string,
region string,
region_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_salesperson.csv' overwrite into table DEFAULT.dim_salesperson;
dim_salesperson.csv
sp001,hongbin,sp001,beijing,10086 sp002,hongming,sp002,beijing,10086 sp003,hongmei,sp003,beijing,10086
4. 创建客户维度 custom_dim
DROP TABLE IF EXISTS DEFAULT.dim_custom ;
create table DEFAULT.dim_custom (
custom_key string,
custom_name string,
custorm_id string,
headquarter_states string,
billing_address string,
billing_city string,
billing_state string,
industry_name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_custom.csv' overwrite into table DEFAULT.dim_custom;
dim_custom.csv
ct001,custom_john,ct001,beijing,zgx-beijing,beijing,beijing,internet ct002,custom_herry,ct002,henan,shlinjie,shangdang,henan,internet
5. 创建产品维度表并插入数据
DROP TABLE IF EXISTS DEFAULT.dim_product ;
create table DEFAULT.dim_product (
product_key string,
product_name string,
product_id string,
product_desc string,
sku string,
brand string,
brand_code string,
brand_manager string,
category string,
category_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_product.csv' overwrite into table DEFAULT.dim_product;
dim_product.csv
pd001,Box-Large,pd001,Box-Large-des,large1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd002,Box-Medium,pd001,Box-Medium-des,medium1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd003,Box-small,pd001,Box-small-des,small1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd004,Evelope,pd001,Evelope_des,large3.0,brand001,brandcode001,brandmanager001,Pens,cate002
这样一个星型的结构表在hive中创建完毕, 实际上一个离线的数据仓库已经完成, 它包含一个主题, 即商品订单.
关于商品订单的统计需求可以使用hive命令产生. 比如:
1. 统计20150501到20150502所有的订单数.
Hive> select dday.full_day, sum(quantity_ordered) from fact_order as fact inner join dim_day as dday on fact.time_key == dday.day_key and dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02" group by dday.full_day order by dday.full_day;
2015-05-01 600
2015-05-02 600
2. 统计20150501到20150502各个销售员的销售订单数
select dday.full_day, dsp.salesperson_key, sum(quantity_ordered) from fact_order as fact
inner join dim_day as dday on fact.time_key == dday.day_key
inner join dim_salesperson as dsp on fact.salesperson_key == dsp.salesperson_key
where dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02"
group by dday.full_day, dsp.salesperson_key
order by dday.full_day;
2015-05-01 sp003 100
2015-05-01 sp002 100
2015-05-01 sp001 400
2015-05-02 sp003 100
2015-05-02 sp002 100
2015-05-02 sp001 400
然后,导入kylin数据仓库中
kylin在hive的基础上仓库olap数据cube, 完成实时数据仓库服务的任务. kylin在hive的基础上完成:
1. 将星型数据库部署在hbase上实现实时的查询服务
2. 提供restful查询接口
3. 集成BI
首先, 创建一个数据仓库工程(kylin_test_project)
其次, 点击tables标签,点击"load hive table"按钮, 同步上述的所有hive表

完成hive表和kylin的同步.
接着, 简历kylin的数据cube
点击cube 和新增cube按钮.
1. 命名cube order_cube
2. 增加fact 和 dim 表

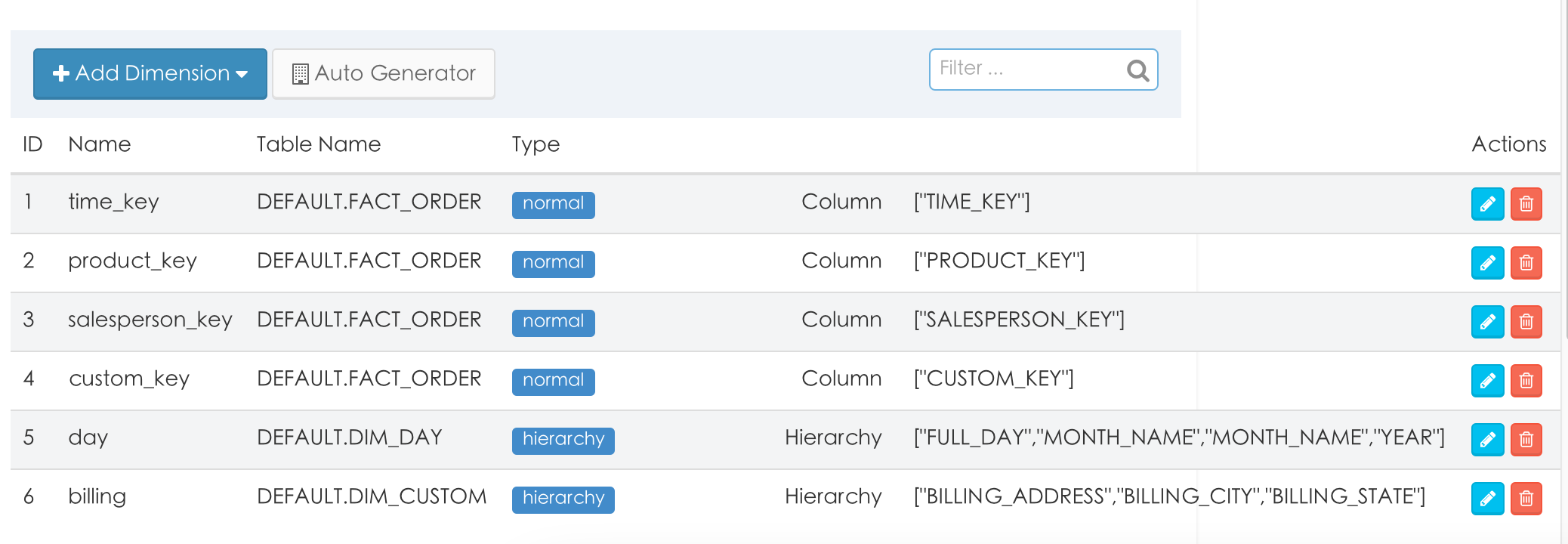
3. 增加维度
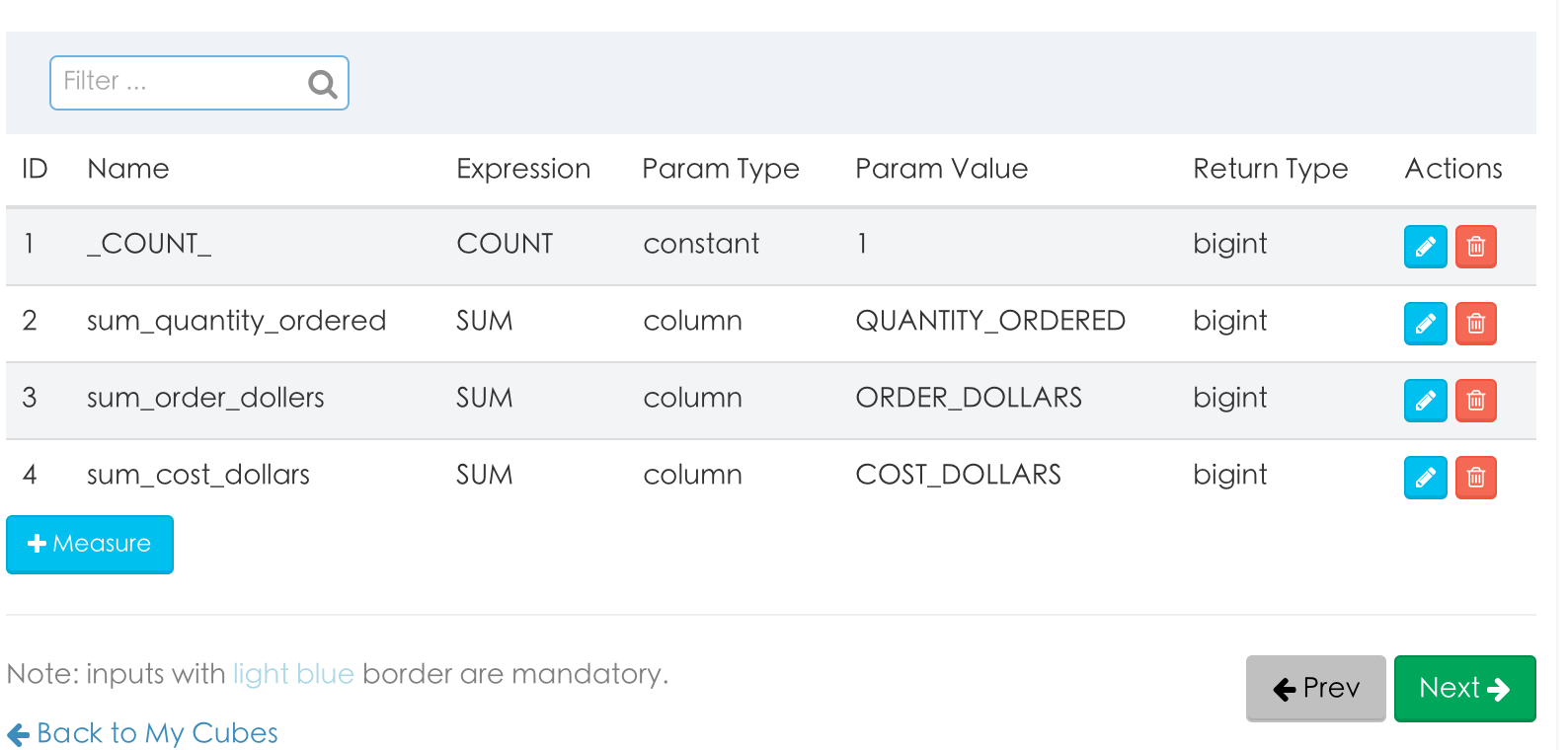
4. 增加mesure值
5. 不用选filter条件
6. 选择开始开始时间
7. 完成
然后, build cube
可以在jobs中查看build状态. build过程实际上是把cube存到hbase中, 方便快速检索.
星型数据仓库olap工具kylin介绍和简单使用示例的更多相关文章
- 星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍 数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每 ...
- OLAP引擎——Kylin介绍(很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- 转: OLAP引擎——Kylin介绍
本文转自:http://blog.csdn.net/yu616568/article/details/48103415 ,如有侵犯,立刻删除. Kylin是ebay开发的一套OLAP系统,与Mond ...
- Java:Apache Commons 工具类介绍及简单使用
Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动.下面是我这几年做开发过程中自己用过的工具类做简单介绍. Commons简介 组件 功能介绍 commo ...
- Apache Commons 工具类介绍及简单使用
转自:http://www.cnblogs.com/younggun/p/3247261.html Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动.下 ...
- Apache Commons 工具类介绍及简单使用(转载)
原文链接 http://www.cnblogs.com/younggun/p/3247261.html Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动 ...
- 浅淡数据仓库(二)星型模式与OLAP多维数据库
在关系数据库管理系统中实现的维度模型称为星型模型模式,因为其结构类似星型结构.在多为数据库环境中实现的维度模型通常称为联机分析处理(OLAP)多维数据库
- Kylin 新定位:分析型数据仓库
亲爱的各位社区朋友: Apache Kylin 在 2014 年 10 月开源并加入 Apache 软件基金会的孵化器,一年后从孵化器毕业成为 Apache 顶级项目.从第一天起,Kylin 的标语是 ...
- 《BI那点儿事》数据仓库建模:星型模式、雪片模式
数据仓库建模 — 星型模式Example of Star Schema 数据仓库建模 — 雪片模式Example of Snowflake Schema 节省存储空间 一定程度上的范式 星形 vs.雪 ...
随机推荐
- javassist实例
我们常用到的动态特性主要是反射,在运行时查找对象属性.方法,修改作用域,通过方法名称调用方法等.在线的应用不会频繁使用反射,因为反射的性能开销较大.其实还有一种和反射一样强大的特性,但是开销却很低,它 ...
- eclipse 查看变量或方法在什么地方被调用的快捷键和快速显示方法入参提示信息
为了用eclipse写代码的时候,不用方向键移动光标,可以设置如下快捷键, Line Up:Alt+i 光标向上 Line Down:Alt+k 光标向下 Line Start:Alt+u 移到 ...
- CocoaPods 添加WebP失败解决办法
pod 'sdwebimage/webp' 下载libwebp 超时 [!] Error installing libwebp [!] /usr/bin/git clone https://chrom ...
- 第四天,通过windows来执行第一个python文件步骤
该看 第 38部分的啦
- canvas霓虹雨
在codepen上看到一个Canvas做的下雨效果动画,感觉蛮有意思的.就研究了下,这里来分享下,实现技巧.效果可以见下面的链接. 霓虹雨: http://codepen.io/natewiley/f ...
- php项目,别人无法访问自己(windows 系统)上Apache服务器原因(转载)
别人无法访问自己电脑上的Apache服务器,其中最大的原因是因为Windows防火墙的因素. 1.有安装防火墙的,把防火墙关闭 2.windows默认带防火墙的,进入 控制面板-系统和安全-Windo ...
- Tcp/IP 的四层模型
维基:https://zh.wikipedia.org/wiki/TCP/IP%E5%8D%8F%E8%AE%AE%E6%97%8F 因特网协议组 LITA 因特网协议组 Link 网络接口层 以太 ...
- SQL语句精简版
select US.QQ,US.tel,US.username,SC.EnglishScore,SC.MathScorefrom Userinfor US right join Score SC on ...
- 目前常用的加密算法有DES(Data Encryption Standard)和IDEA(International Data Encryption Algorithm)国际数据加密算法等,请用工厂方法实现加密算法系统。提交该系统的代码,该系统务必是一个可以能够直接使用的系统,查阅资料完成相应加密算法的实现;
1.加密算法的类图结构 2.源代码 2.1代码运行截图 2.2代码的目录结构 2.3具体代码 MethodFactory.java package jiami; public interface Me ...
- MySQL数据库导出
因为业务需要,把MySQL查询的数据导出成csv文件,操作在Navicat中完成. 首选用SELECT语句查询数据,然后Navicat的导出,然后选csv,选路径,再加上首栏就可以了