星型数据仓库olap工具kylin介绍和简单使用示例
本文转载自:https://www.cnblogs.com/hsydj/p/4515057.html
星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍
数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每个大公司都花费数百万每年的资金进行数据仓库的运维.
本文介绍一个基于hadoop的数据仓库, 它基于hadoop(HIVE, HBASE)水平扩展的特性, 客服传统olap受限于关系型数据库数据容量的问题. Kylin是ebay推出的olap星型数据仓库的开源实现.
首先请安装Kylin, 和它的运行环境(Hadoop, yarn, hive, hbase). 如果安装成功, 登陆(http://<KYLIN_HOST>:7070/), 用户名:ADMIN, 密码(KYLIN). 安装过程请参考(http://kylin.incubator.apache.org/download/, 注意下载编译后的二进制包, 免去很多编译烦恼).
在创建数据仓库前, 我们先聊一下, 什么是数据仓库.
从业务过程的角度考虑, 信息系统可以划分为两个主要类别, 一类用于支持业务过程的执行, 代表作品是mysql; 另一类用于支持业务过程的分析, 代表作品是hive, 还有就是今天的主角kylin.
首先, 数据仓库的设计
下图展示了一个简单的基于订单流程中事实和维度的星型模型.

这是一个典型的星型结构, 订单的事实表有3个度量值(messures)(订单数量, 订单金额, 和订单成本); 另外有4个度量维度(dimession), 分别是时间, 产品, 销售员, 客户. 这里时间以天为单位, 这里注意day_key必须是(YYYY-MM-DD)格式(这是kylin的规定).
其次, 根据数据仓库的设计创建hive表
1. 创建事实表并插入数据
DROP TABLE IF EXISTS DEFAULT.fact_order ;
create table DEFAULT.fact_order (
time_key string,
product_key string,
salesperson_key string,
custom_key string,
quantity_ordered bigint,
order_dollars bigint,
cost_dollars bigint
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'fact_order.csv' overwrite into table DEFAULT.fact_order;
fact_order.csv
2015-05-01,pd001,sp001,ct001,100,101,51 2015-05-01,pd001,sp002,ct002,100,101,51 2015-05-01,pd001,sp003,ct002,100,101,51 2015-05-01,pd002,sp001,ct001,100,101,51 2015-05-01,pd003,sp001,ct001,100,101,51 2015-05-01,pd004,sp001,ct001,100,101,51 2015-05-02,pd001,sp001,ct001,100,101,51 2015-05-02,pd001,sp002,ct002,100,101,51 2015-05-02,pd001,sp003,ct002,100,101,51 2015-05-02,pd002,sp001,ct001,100,101,51 2015-05-02,pd003,sp001,ct001,100,101,51 2015-05-02,pd004,sp001,ct001,100,101,51
2. 创建天维度表day_dim
DROP TABLE IF EXISTS DEFAULT.dim_day ;
create table DEFAULT.dim_day (
day_key string,
full_day string,
month_name string,
quarter string,
year string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_day.csv' overwrite into table DEFAULT.dim_day;
dim_day.csv
2015-05-01,2015-05-01,201505,2015q2,2015 2015-05-02,2015-05-02,201505,2015q2,2015 2015-05-03,2015-05-03,201505,2015q2,2015 2015-05-04,2015-05-04,201505,2015q2,2015 2015-05-05,2015-05-05,201505,2015q2,2015
3. 创建售卖员的维度表salesperson_dim
DROP TABLE IF EXISTS DEFAULT.dim_salesperson ;
create table DEFAULT.dim_salesperson (
salesperson_key string,
salesperson string,
salesperson_id string,
region string,
region_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_salesperson.csv' overwrite into table DEFAULT.dim_salesperson;
dim_salesperson.csv
sp001,hongbin,sp001,beijing,10086 sp002,hongming,sp002,beijing,10086 sp003,hongmei,sp003,beijing,10086
4. 创建客户维度 custom_dim
DROP TABLE IF EXISTS DEFAULT.dim_custom ;
create table DEFAULT.dim_custom (
custom_key string,
custom_name string,
custorm_id string,
headquarter_states string,
billing_address string,
billing_city string,
billing_state string,
industry_name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_custom.csv' overwrite into table DEFAULT.dim_custom;
dim_custom.csv
ct001,custom_john,ct001,beijing,zgx-beijing,beijing,beijing,internet ct002,custom_herry,ct002,henan,shlinjie,shangdang,henan,internet
5. 创建产品维度表并插入数据
DROP TABLE IF EXISTS DEFAULT.dim_product ;
create table DEFAULT.dim_product (
product_key string,
product_name string,
product_id string,
product_desc string,
sku string,
brand string,
brand_code string,
brand_manager string,
category string,
category_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'dim_product.csv' overwrite into table DEFAULT.dim_product;
dim_product.csv
pd001,Box-Large,pd001,Box-Large-des,large1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd002,Box-Medium,pd001,Box-Medium-des,medium1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd003,Box-small,pd001,Box-small-des,small1.0,brand001,brandcode001,brandmanager001,Packing,cate001 pd004,Evelope,pd001,Evelope_des,large3.0,brand001,brandcode001,brandmanager001,Pens,cate002
这样一个星型的结构表在hive中创建完毕, 实际上一个离线的数据仓库已经完成, 它包含一个主题, 即商品订单.
关于商品订单的统计需求可以使用hive命令产生. 比如:
1. 统计20150501到20150502所有的订单数.
Hive> select dday.full_day, sum(quantity_ordered) from fact_order as fact inner join dim_day as dday on fact.time_key == dday.day_key and dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02" group by dday.full_day order by dday.full_day;
2015-05-01 600
2015-05-02 600
2. 统计20150501到20150502各个销售员的销售订单数
select dday.full_day, dsp.salesperson_key, sum(quantity_ordered) from fact_order as fact
inner join dim_day as dday on fact.time_key == dday.day_key
inner join dim_salesperson as dsp on fact.salesperson_key == dsp.salesperson_key
where dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02"
group by dday.full_day, dsp.salesperson_key
order by dday.full_day;
2015-05-01 sp003 100
2015-05-01 sp002 100
2015-05-01 sp001 400
2015-05-02 sp003 100
2015-05-02 sp002 100
2015-05-02 sp001 400
然后,导入kylin数据仓库中
kylin在hive的基础上仓库olap数据cube, 完成实时数据仓库服务的任务. kylin在hive的基础上完成:
1. 将星型数据库部署在hbase上实现实时的查询服务
2. 提供restful查询接口
3. 集成BI
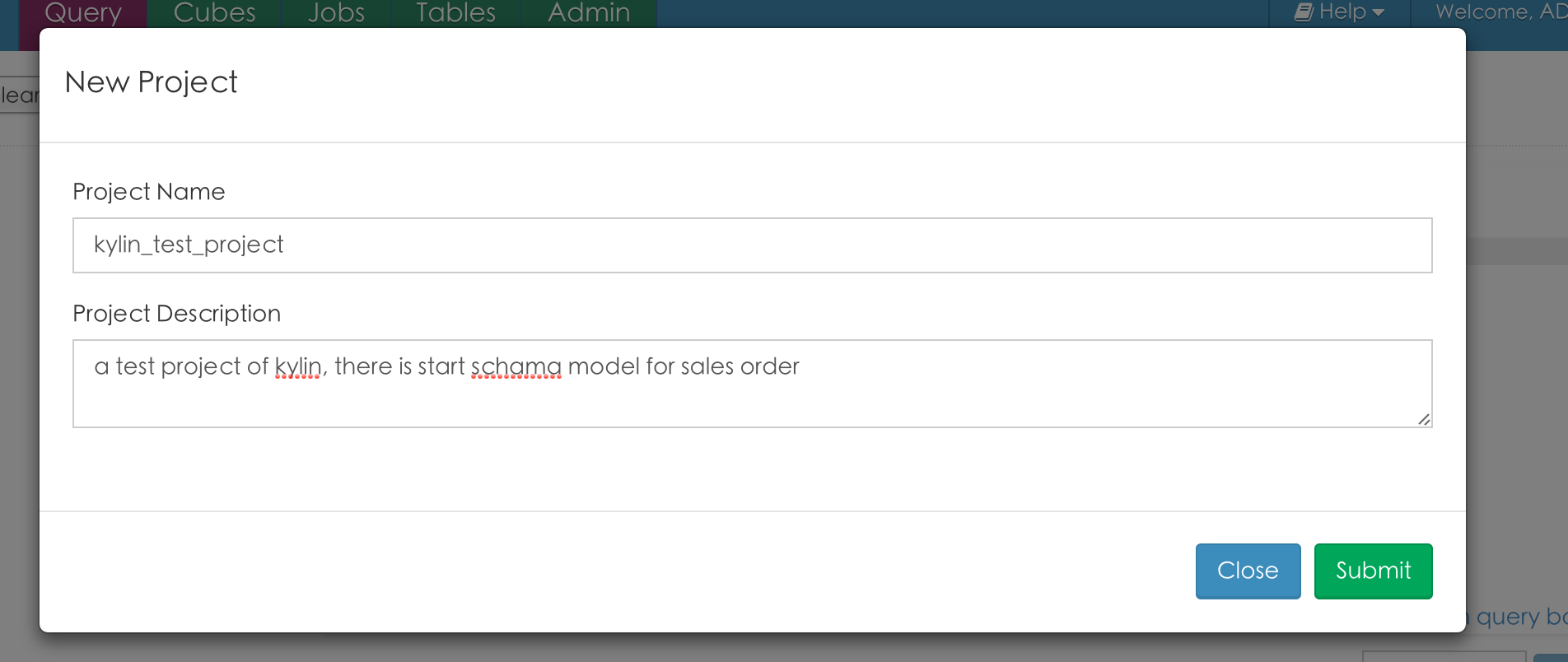
首先, 创建一个数据仓库工程(kylin_test_project)
其次, 点击tables标签,点击"load hive table"按钮, 同步上述的所有hive表

完成hive表和kylin的同步.
接着, 简历kylin的数据cube
点击cube 和新增cube按钮.
1. 命名cube order_cube
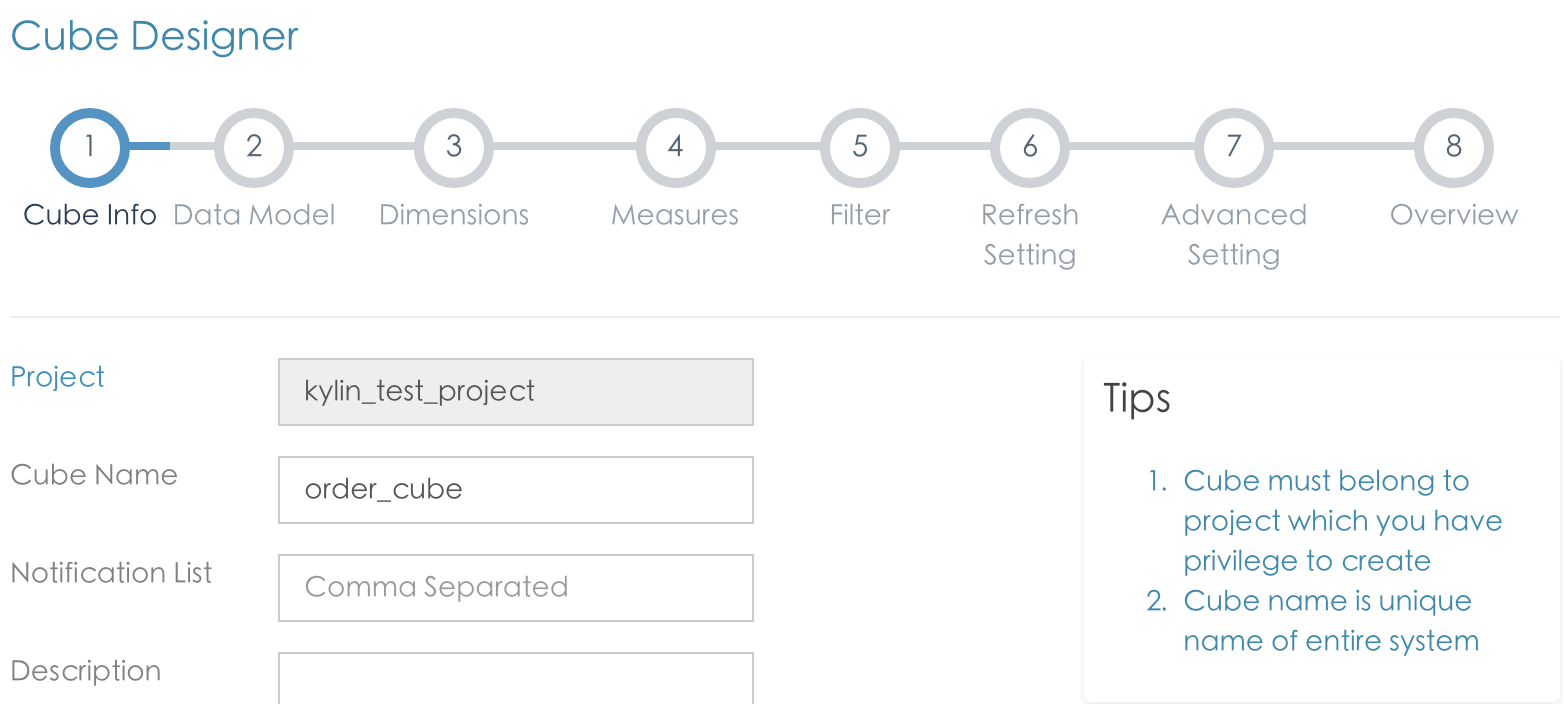
2. 增加fact 和 dim 表

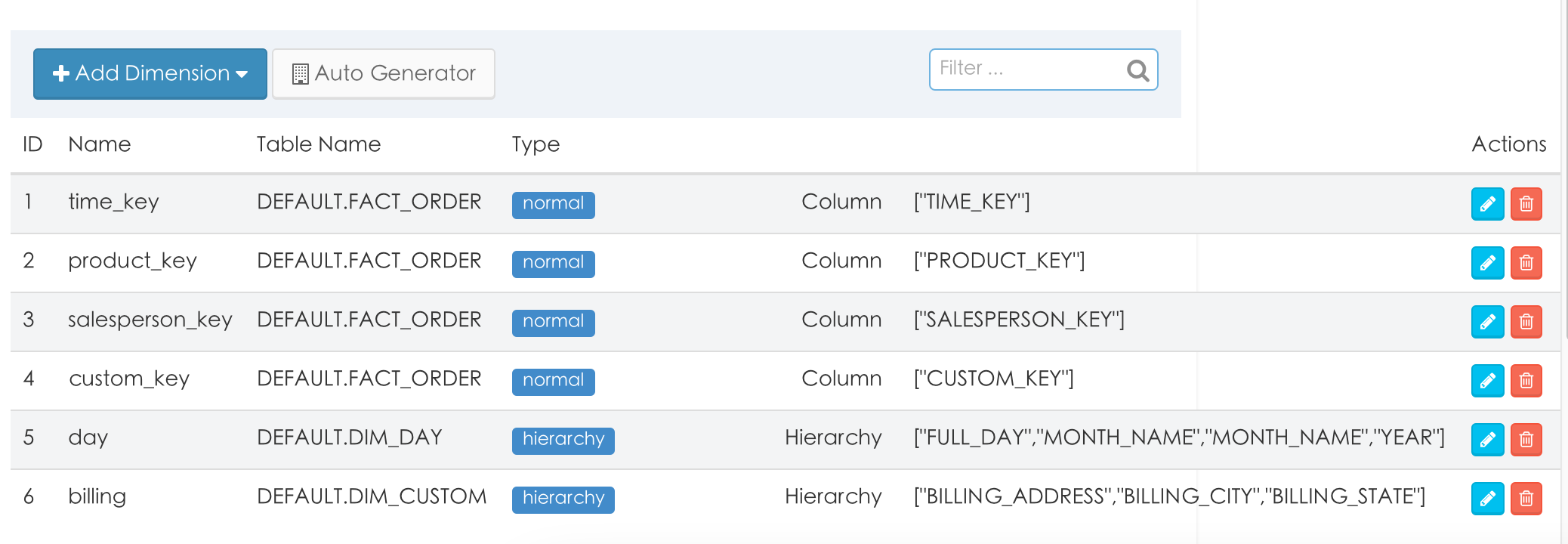
3. 增加维度
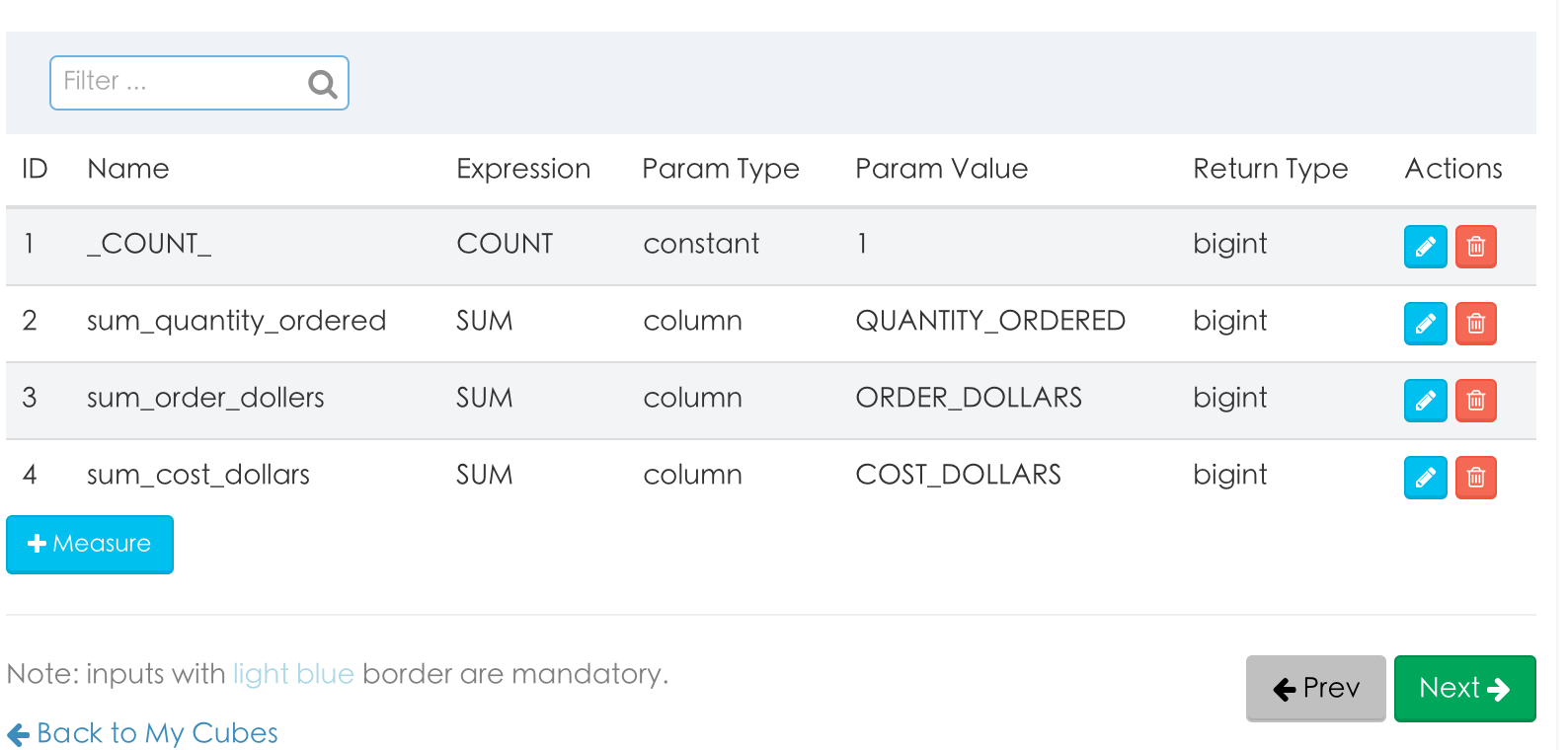
4. 增加mesure值
5. 不用选filter条件
6. 选择开始开始时间
7. 完成
然后, build cube
可以在jobs中查看build状态. build过程实际上是把cube存到hbase中, 方便快速检索.
星型数据仓库olap工具kylin介绍和简单使用示例的更多相关文章
- 星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍 数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每 ...
- OLAP引擎——Kylin介绍(很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- 转: OLAP引擎——Kylin介绍
本文转自:http://blog.csdn.net/yu616568/article/details/48103415 ,如有侵犯,立刻删除. Kylin是ebay开发的一套OLAP系统,与Mond ...
- Java:Apache Commons 工具类介绍及简单使用
Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动.下面是我这几年做开发过程中自己用过的工具类做简单介绍. Commons简介 组件 功能介绍 commo ...
- Apache Commons 工具类介绍及简单使用
转自:http://www.cnblogs.com/younggun/p/3247261.html Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动.下 ...
- Apache Commons 工具类介绍及简单使用(转载)
原文链接 http://www.cnblogs.com/younggun/p/3247261.html Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动 ...
- 浅淡数据仓库(二)星型模式与OLAP多维数据库
在关系数据库管理系统中实现的维度模型称为星型模型模式,因为其结构类似星型结构.在多为数据库环境中实现的维度模型通常称为联机分析处理(OLAP)多维数据库
- Kylin 新定位:分析型数据仓库
亲爱的各位社区朋友: Apache Kylin 在 2014 年 10 月开源并加入 Apache 软件基金会的孵化器,一年后从孵化器毕业成为 Apache 顶级项目.从第一天起,Kylin 的标语是 ...
- 《BI那点儿事》数据仓库建模:星型模式、雪片模式
数据仓库建模 — 星型模式Example of Star Schema 数据仓库建模 — 雪片模式Example of Snowflake Schema 节省存储空间 一定程度上的范式 星形 vs.雪 ...
随机推荐
- Android多种格式的异步解压/压缩解决方案
前言 最近由于项目需要,需要我谅解一下关于在移动平台的解压功能,在移动平台解压,我个人感觉是没有太大必要的,毕竟手机的性能有限.但是,不口否认,移动端的解压功能又是必备的,因为如果对于一些资源管理器类 ...
- Oracle集群(RAC)时间同步(ntp和CTSS)
Oracle集群(RAC)时间同步(ntp和CTSS) http://blog.itpub.net/26736162/viewspace-2157130/ crsctl stat res -t -in ...
- BackboneJS 源码注释
Backbone 作者在源码中做了很好的注释,这里只是锦上添花,补充一些个人的理解而已. // Backbone.js 1.2.3 // (c) 2010-2015 Jeremy Ashkenas, ...
- 114、drawable和mipmap 目录下图片的区别
android 在 API level 17 加入了 mipmap 技术,对 bitmap 图片的渲染支持 mipmap 技术,来提高渲染的速度和质量.mipmap 是一种很早就有的技术了,翻译过来就 ...
- dir 命令手册
dir 命令手册 参数 /A D 目录 R 只读文件 H 隐藏文件 A 准备存档的文件 S 系统文件 - 表示"否"的前缀 /B 使用空格式(没有标题信息或摘要) /C 在文件大小 ...
- Ubuntu下开启Mysql远程访问的方法
首先想说,JetProfiler对分析项目中MySQL问题以及优化,是个非常好的工具.但是看网上文章,中文介绍真的不多.是因为国内现在都不用MySQL了吗? 因为公司JetProfiler是共用的,安 ...
- shell for循环 多个变量
需求:需要输出以下2开头的端口号和其对应的文件 like: port and port_k8s_xxx.conf 其脚本为: #! /bash/shell #以value_name=(value1 v ...
- 进程池的回调函数callback
如下代码: from multiprocessing import Pool def func1(n): print('in func1') return n*n def func2(nn): pri ...
- 1. node.js 认识 (一)
官网: (下载安装nodejs) https://nodejs.org/en/ http://nodejs.cn/ Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环 ...
- 爬虫IP代理中的http与https
之前使用代理IP,构造的proxies一直都是http模式 proxies={"http": "http://{}".format(ip)} 但是今天遇到的网站 ...