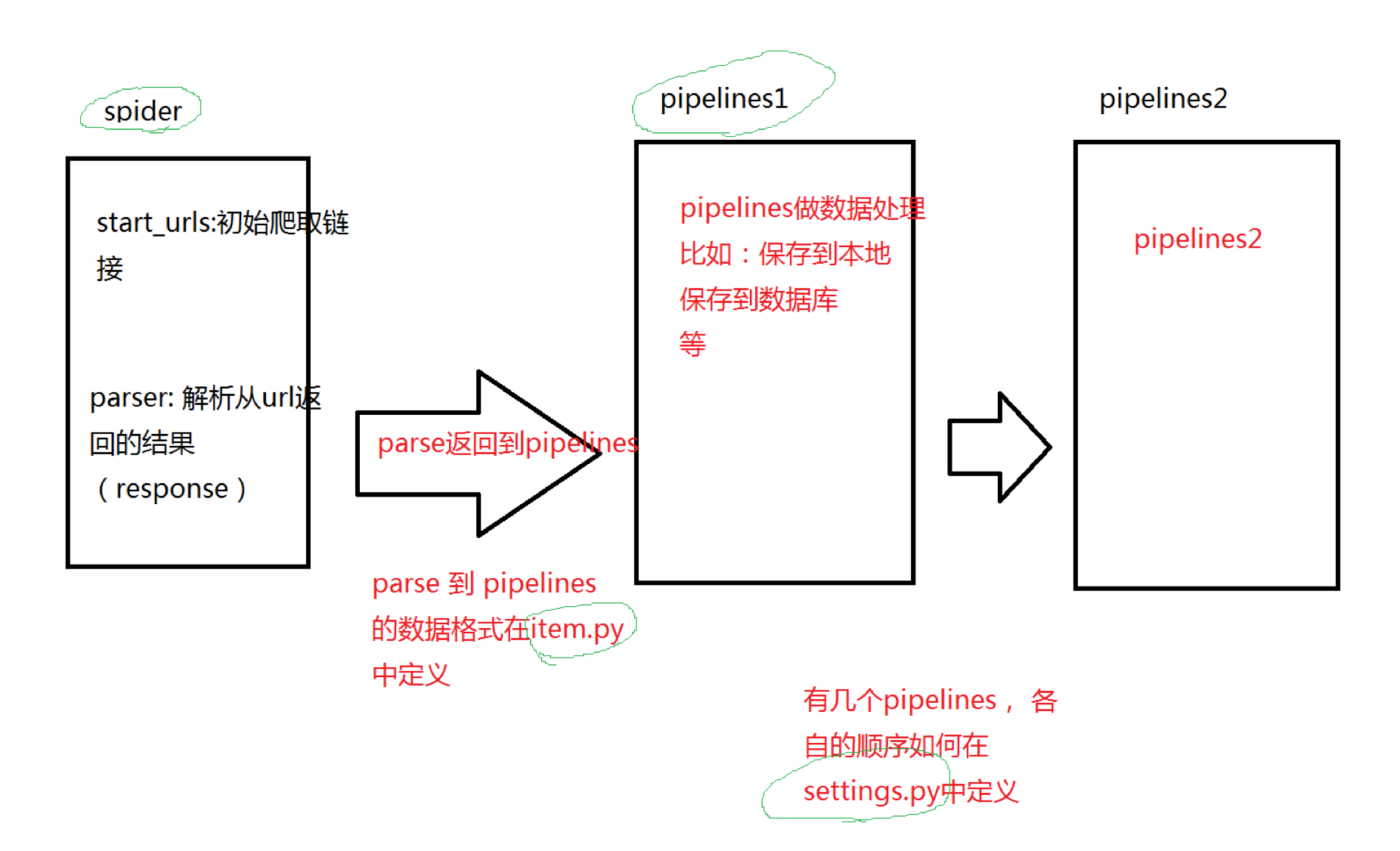
python scrapy爬虫框架概念介绍(个人理解总结为一张图)
首先开始一个scrapy项目
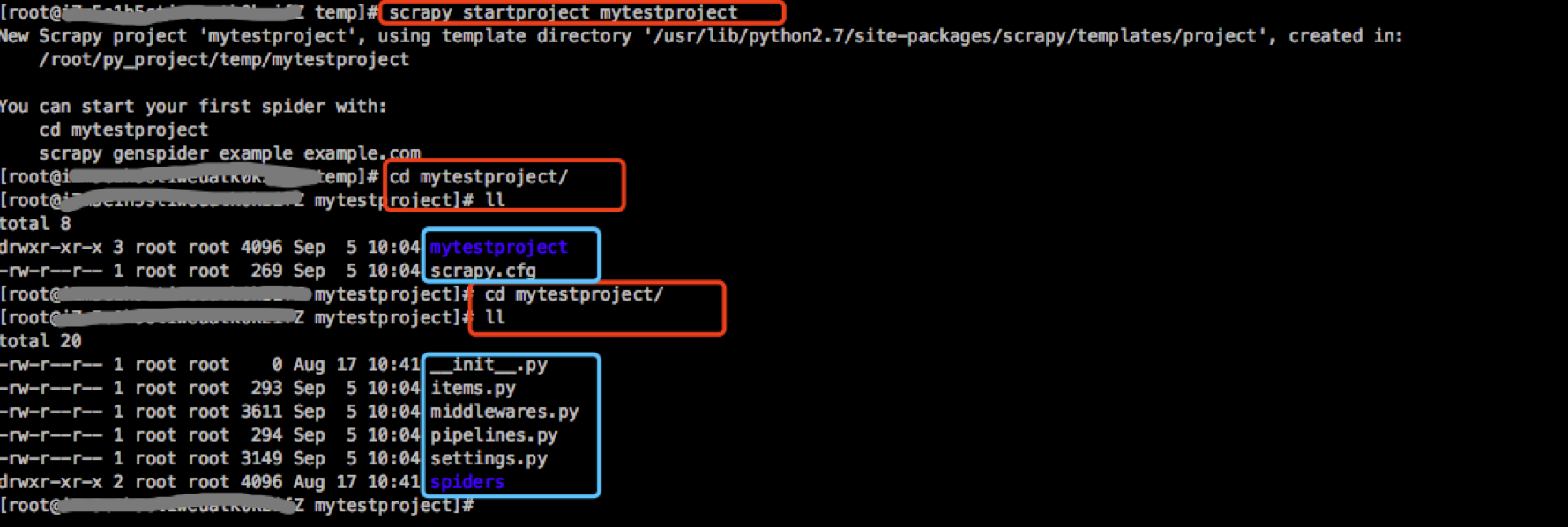
其中各个最常用文件的用处:
python scrapy爬虫框架概念介绍(个人理解总结为一张图)的更多相关文章
- Python Scrapy 爬虫框架实例(一)
之前有介绍 scrapy 的相关知识,但是没有介绍相关实例,在这里做个小例,供大家参考学习. 注:后续不强调python 版本,默认即为python3.x. 爬取目标 这里简单找一个图片网站,获取图片 ...
- Python Scrapy 爬虫框架实例
之前有介绍 scrapy 的相关知识,但是没有介绍相关实例,在这里做个小例,供大家参考学习. 注:后续不强调python 版本,默认即为python3.x. 爬取目标 这里简单找一个图片网站,获取图片 ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- Python Scrapy爬虫框架之初次使用
此篇博客为本人对小甲鱼的课程的总结. 关于Scrapy的安装网上都有方法,这里便不再叙述. 使用Scrapy抓取一个网站一共需要四个步骤: 0.创建一个Scrapy项目: 1.定义Item容器: 2. ...
- python - scrapy 爬虫框架(创建, 持久化, 去重, 深度, cookie)
## scrapy 依赖 twisted - twisted 是一个基于事件循环的 异步非阻塞 框架/模块 ## 项目的创建 1. 创建 project scrapy startproject ...
- python - scrapy 爬虫框架 ( 起始url的实现,深度和优先级,下载中间件 )
1. start_urls -- 起始URL 的内部实现(将迭代器转换为生成器) class QSpider(scrapy.Spider): name = 'q' allowed_domains ...
- (1)python Scrapy爬虫框架
部署 1.安装python3.6 64bit 2.下载pywin32 https://sourceforge.net/projects/pywin32/files/pywin32/ 双击安装 3.下 ...
- python scrapy爬虫框架
http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html scrapy 提取html的标签内容 from scrapy.selec ...
- python - scrapy 爬虫框架 ( redis去重 )
1. 使用内置,并加以修改 ( 自定义 redis 存储的 keys ) settings 配置 # ############### scrapy redis连接 ################# ...
随机推荐
- rabbitMQ和对应的erlang版本匹配
来源自https://www.rabbitmq.com/which-erlang.html erlang安装包下载地址 https://packages.erlang-solutions.com/er ...
- netty源码解解析(4.0)-9 ChannelPipleline的默认实现-链表管理
io.netty.channel.DefaultChannelPipeline implements ChannelPipleline DefaultChannelPiple给出了ChannelP ...
- ASP.NET MVC5 + EF6 + LayUI实战教程,通用后台管理系统框架(3)
前言 本节将我们自己的CSS样式替换系统自带的 开始搭建 将脚本文件夹删掉,将内容文件夹里的内容删掉,将我们自己的CSS样式文件,全部复制到内容里边 新建家庭控制器 给家庭控制器添加索引视图 指数代码 ...
- MongoDB设计系列
原创文章,如果转载请标明出处.作者. https://www.cnblogs.com/alunchen/p/9762233.html 1 前言 MongoDB作为现今流行的非关系型文档数据库,已经有很 ...
- 打印小票,使用的是BarcodeLib
打印 private void Control_Click(object s,EventArgs e) { if (((Control)s).Name == "button1") ...
- 无法从其“Checked”属性的字符串表示形式“checked”创建“System.Boolean”类型
如果你要在后台进行设置的话...在<input type="radio" id="dd" name="dd" runat=" ...
- Python知识梳理
这是个人学习笔记,非教程,内容会有些混乱 极简教程 数据类型 我们可以使用type()函数类获取对象的类型,Python3中内置数据类型包括:None,int,float,complex,st ...
- SQL Server 基本INSERT语句
1.基本INSERT语句,单行插入 如果没有列出列,则使一一对应. 2.多行插入 3.INSERT INTO ... SELECT 语句 要插入的语句是从其他表中查询出来的. 注意:数据类型得相同或者 ...
- HDU6191(01字典树启发式合并)
Query on A Tree Time Limit: 20000/10000 MS (Java/Others) Memory Limit: 132768/132768 K (Java/Othe ...
- css3火焰文字样式代码
css样式: <style type="text/css"> body{background:#000;} *{margin:0;padding:0;transitio ...