『PyTorch』第五弹_深入理解Tensor对象_下:从内存看Tensor
Tensor存储结构如下,
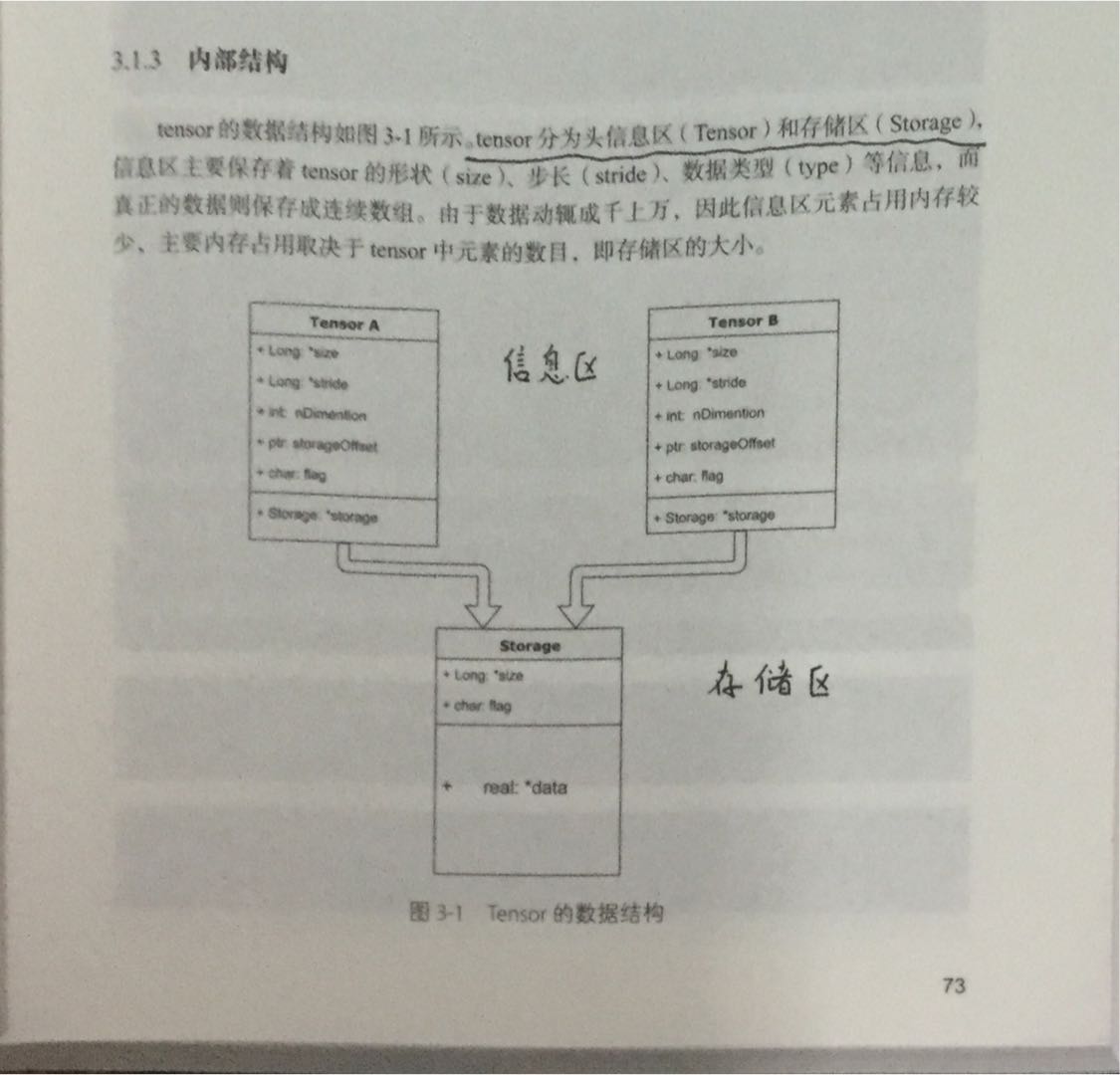
如图所示,实际上很可能多个信息区对应于同一个存储区,也就是上一节我们说到的,初始化或者普通索引时经常会有这种情况。
一、几种共享内存的情况
view
a = t.arange(0,6)
print(a.storage())
b = a.view(2,3)
print(b.storage())
print(id(a.storage())==id(b.storage()))
a[1] = 10
print(b)
上面代码,我们通过.storage()可以查询到Tensor所对应的storage地址,可以看到view虽然不是inplace的,但也仅仅是更改了对同一片内存的检索方式而已,并没有开辟新的内存:
0.0
1.0
2.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
0.0
1.0
2.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
True 0 10 2
3 4 5
[torch.FloatTensor of size 2x3]
简单索引
注意,id(a.storage())==id(c.storage()) != id(a[2])==id(a[0])==id(c[0]),id(a)!=id(c)
c = a[2:]
print(c.storage()) # c所属的storage也在这里
print(id(a[2]), id(a[0]),id(c[0])) # 指向了同一处
print(id(a),id(c))
print(id(a.storage()),id(c.storage()))
0.0
10.0
2.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
2443616787576 2443616787576 2443616787576
2443617946696 2443591634888
2443617823496 2443617823496
通过Tensor初始化Tensor
d = t.Tensor(c.storage())
d[0] = 20
print(a)
print(id(a.storage())==id(b.storage())==id(c.storage())==id(d.storage()))
20
10
2
3
4
5
[torch.FloatTensor of size 6] True
二、内存检索方式查看
storage_offset():偏移量
stride():步长,注意下面的代码,步长比我们通常理解的步长稍微麻烦一点,是有层次结构的步长
print(a.storage_offset(),b.storage_offset(),c.storage_offset(),d.storage_offset())
e = b[::2,::2]
print(id(b.storage())==id(e.storage()))
print(b.stride(),e.stride())
print(e.is_contiguous())
f = e.contiguous() # 对于内存不连续的张量,复制数据到新的连续内存中
print(id(f.storage())==id(e.storage()))
print(e.is_contiguous())
print(f.is_contiguous())
g = f.contiguous() # 对于内存连续的张量,这个操作什么都没做
print(id(f.storage())==id(g.storage()))
高级检索一般不共享stroage,这就是因为普通索引可以通过修改offset、stride、size实现,二高级检索出的结果坐标更加混乱,不方便这样修改,需要开辟新的内存进行存储。
三、其他有关Tensor
持久化
t.save和t.load,由于torch的为单独Tensor指定设备的特性,实际保存时会保存设备信息,但是load是通过特定参数可以加载到其他设备,详情help(torch.load),其他的同numpy类似
向量化计算
Tensor天生支持广播和矩阵运算,包含numpy等其他库在内,其矩阵计算效率远高于python内置的for循环,能少用for就少用,换句话说python的for循环实现的效率很低。
辅助功能
设置展示位数:t.set_printoptions(precision=n)
In [13]: a = t.randn(2,3)
In [14]: a
Out[14]:1.1564 0.5561 -0.2968
-1.0205 0.8023 0.1582
[torch.FloatTensor of size 2x3]In [15]: t.set_printoptions(precision=10)
In [16]: a
Out[16]:1.1564352512 0.5561078787 -0.2968128324
-1.0205242634 0.8023245335 0.1582107395
[torch.FloatTensor of size 2x3]
out参数:
很多torch函数有out参数,这主要是因为torch没有tf.cast()这类的类型转换函数,也少有dtype参数指定输出类型,所以需要事先建立一个输出Tensor为LongTensor、IntTensor等等,再由out导入,如下:
In [3]: a = t.arange(0, 20000000)
In [4]: print(a[-1],a[-2])
16777216.0 16777216.0
可以看到溢出了数字,如果这样处理,
In [5]: b = t.LongTensor()
In [6]: b = t.arange(0,20000000)
In [7]: b[-2]
Out[7]: 16777216.0
还是不行,只能这样,
In [9]: b = t.LongTensor()
In [10]: t.arange(0,20000000,out=b)
Out[10]:0.0000e+00
1.0000e+00
2.0000e+00
⋮
2.0000e+07
2.0000e+07
2.0000e+07
[torch.LongTensor of size 20000000]In [11]: b[-2]
Out[11]: 19999998In [12]: b[-1]
Out[12]: 19999999
『PyTorch』第五弹_深入理解Tensor对象_下:从内存看Tensor的更多相关文章
- 『PyTorch』第五弹_深入理解autograd_下:函数扩展&高阶导数
一.封装新的PyTorch函数 继承Function类 forward:输入Variable->中间计算Tensor->输出Variable backward:均使用Variable 线性 ...
- 『PyTorch』第五弹_深入理解autograd_上:Variable属性方法
在PyTorch中计算图的特点可总结如下: autograd根据用户对variable的操作构建其计算图.对变量的操作抽象为Function. 对于那些不是任何函数(Function)的输出,由用户创 ...
- 『PyTorch』第五弹_深入理解autograd_中:Variable梯度探究
查看非叶节点梯度的两种方法 在反向传播过程中非叶子节点的导数计算完之后即被清空.若想查看这些变量的梯度,有两种方法: 使用autograd.grad函数 使用hook autograd.grad和ho ...
- 『PyTorch』第五弹_深入理解Tensor对象_中下:数学计算以及numpy比较_&_广播原理简介
一.简单数学操作 1.逐元素操作 t.clamp(a,min=2,max=4)近似于tf.clip_by_value(A, min, max),修剪值域. a = t.arange(0,6).view ...
- 『PyTorch』第五弹_深入理解Tensor对象_中上:索引
一.普通索引 示例 a = t.Tensor(4,5) print(a) print(a[0:1,:2]) print(a[0,:2]) # 注意和前一种索引出来的值相同,shape不同 print( ...
- 『PyTorch』第五弹_深入理解Tensor对象_上:初始化以及尺寸调整
一.创建Tensor 特殊方法: t.arange(1,6,2)t.linspace(1,10,3)t.randn(2,3) # 标准分布,*size t.randperm(5) # 随机排序,从0到 ...
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 # Author : Hellcat # Time : 2018/2/11 import torch as t import t ...
- 『PyTorch』第三弹重置_Variable对象
『PyTorch』第三弹_自动求导 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Varibale包含三个属性: data ...
- 『PyTorch』第十弹_循环神经网络
RNN基础: 『cs231n』作业3问题1选讲_通过代码理解RNN&图像标注训练 TensorFlow RNN: 『TensotFlow』基础RNN网络分类问题 『TensotFlow』基础R ...
随机推荐
- python_打包成exe
1. 安装pyinstaller pip install pyinstaller 或通过国内镜像下载(较快): pip install pyinstaller -i http://pypi.douba ...
- Apache ab并发负载压力测试(python+django+mysql+apache)
如标题,大家都知道秒杀中存在高并发使库存骤然为0,但在我们个人PC或小区域内是模拟不出这样的情景 现在利用 Apache ab并发负载压力测试 1,数据库建入库存字段并映射模型 2,view编写脚本 ...
- python进阶之 线程编程
1.进程回顾 之前已经了解了操作系统中进程的概念,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别就在于:程序是指令的集合,它是进程 ...
- https://github.com/tensorflow/models/blob/master/research/slim/datasets/preprocess_imagenet_validation_data.py 改编版
#!/usr/bin/env python # Copyright 2016 Google Inc. All Rights Reserved. # # Licensed under the Apach ...
- 经验分享 | 如何拿到自己满意的offer?
本文阅读时间约16分钟 最近两年,人工智能(AI)就像一个点石成金的神器,所有的行业,创业公司,或是求职,只要沾着这个词,多少有点脚踩五彩祥云的感觉,故事来了,融资来了,高薪来了. 于是,越来越多的人 ...
- Python 操作 MySQL 的5种方式(转)
Python 操作 MySQL 的5种方式 不管你是做数据分析,还是网络爬虫,Web 开发.亦或是机器学习,你都离不开要和数据库打交道,而 MySQL 又是最流行的一种数据库,这篇文章介绍 Pytho ...
- JavaScript知识精简
JS单线程,同步,一次执行某一段代码,等到前一个程序执行完毕再执行.,阻塞,安全. 多线程,异步,不用等到前一个程序执行完毕就执行. 数据类型 JavaScript 是 弱类型 语言,但并不是没有 ...
- 深入FM和FFM原理与实践
FM和FFM模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,仍然能够得到优秀的性能和效果的特性,屡次在各大公司举办的CTR预估比赛中获得不错的战绩.美团点评技术团队在搭建DSP的过 ...
- 生成树协议stp
生成树协议应用的原因是从逻辑上阻塞交换机在物理上形成的环路.大家都知道交换机工作在二层,也就是数据链路层,根据mac地址识别主机,对三层网络无法识别,因此交换机不能隔离广播.但是在日常的工作中,为了达 ...
- 国服最强JWT生成Token做登录校验讲解,看完保证你学会!
转载于:https://blog.csdn.net/u011277123/article/details/78918390 Free码农 2017-12-28 00:08:02 JWT简介 JWT(j ...