卷积的三种模式:full, same, valid
通常用外部api进行卷积的时候,会面临mode选择。
本文清晰展示三种模式的不同之处,其实这三种不同模式是对卷积核移动范围的不同限制。
设 image的大小是7x7,filter的大小是3x3
1,full mode
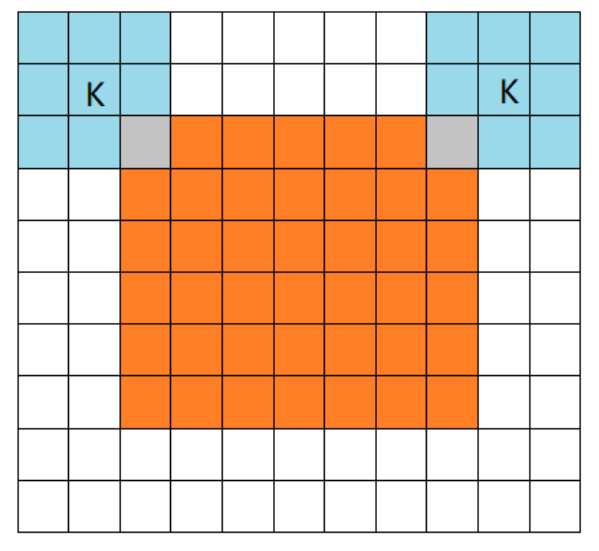
橙色部分为image, 蓝色部分为filter。full模式的意思是,从filter和image刚相交开始做卷积,白色部分为填0。filter的运动范围如图所示。
2,same mode
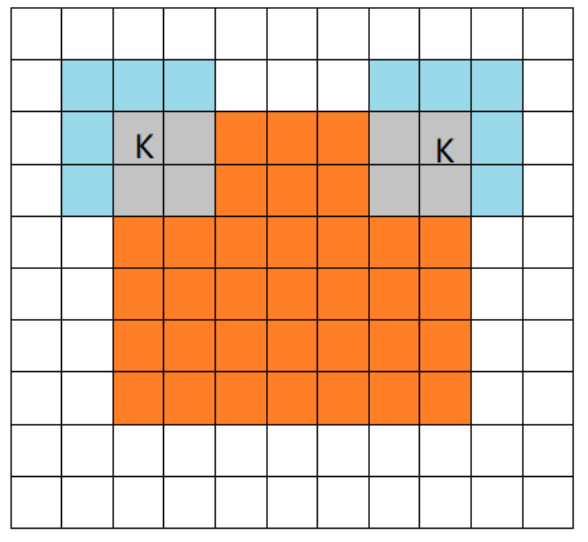
当filter的中心(K)与image的边角重合时,开始做卷积运算,可见filter的运动范围比full模式小了一圈。注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参师不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
3.valid
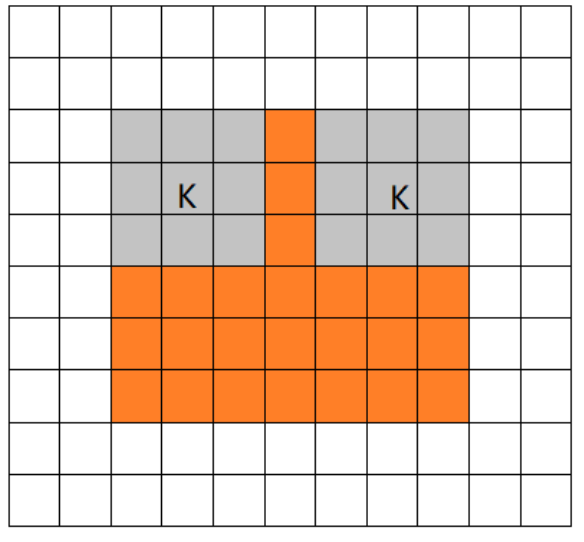
当filter全部在image里面的时候,进行卷积运算,可见filter的移动范围较same更小了。
---------------------
作者:木盏
来源:CSDN
原文:https://blog.csdn.net/leviopku/article/details/80327478
版权声明:本文为博主原创文章,转载请附上博文链接!
在深度学习的图像识别领域中,我们经常使用卷积神经网络CNN来对图像进行特征提取,当我们使用TensorFlow搭建自己的CNN时,一般会使用TensorFlow中的卷积函数和池化函数来对图像进行卷积和池化操作,而这两种函数中都存在参数padding,该参数的设置很容易引起错误,所以在此总结下。
1.为什么要使用padding
在弄懂padding规则前得先了解拥有padding参数的函数,在TensorFlow中,主要使用tf.nn.conv2d()进行(二维数据)卷积操作,tf.nn.max_pool()、tf.nn.avg_pool来分别实现最大池化和平均池化,通过查阅官方文档我们知道其需要的参数如下:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,name=None)
tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax=None, name=None)
tf.nn.max_pool(value, ksize, strides, padding, name=None)
这三个函数中都含有padding参数,我们在使用它们的时候需要传入所需的值,padding的值为字符串,可选值为'SAME' 和 'VALID' ;
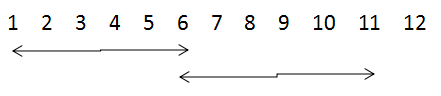
padding参数的作用是决定在进行卷积或池化操作时,是否对输入的图像矩阵边缘补0,'SAME' 为补零,'VALID' 则不补,其原因是因为在这些操作过程中过滤器可能不能将某个方向上的数据刚好处理完,如下所示:
当步长为5,卷积核尺寸为6×6时,当padding为VALID时,则可能造成数据丢失(如左图),当padding为SAME时,则对其进行补零(如右图),
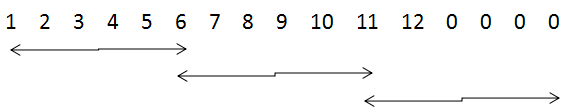
2. padding公式
首先,定义变量:
输入图片的宽和高:i_w 和 i_h
输出特征图的宽和高:o_w 和 o_h
过滤器的宽和高:f_w 和 f_h
宽和高方向的步长:s_w 和 s_h
宽和高方向总的补零个数:pad_w 和 pad_h
顶部和底部的补零个数:pad_top 和 pad_bottom
左部和右部的补零个数:pad_left 和 pad_right
1.VALID模式
输出的宽和高为
o_w = (i_w - f_w + 1)/ s_w #(结果向上取整)
o_h = (i_h - f_h + 1)/ s_h #(结果向上取整)
2. SAME模式
输出的宽和高为
o_w = i_w / s_w#(结果向上取整)
o_h = i_h / s_h#(结果向上取整)
各个方向的补零个数为:max()为取较大值,
pad_h = max(( o_h -1 ) × s_h + f_h - i_h , 0)
pad_top = pad_h / 2 # 注意此处向下取整
pad_bottom = pad_h - pad_top
pad_w = max(( o_w -1 ) × s_w + f_w - i_w , 0)
pad_left = pad_w / 2 # 注意此处向下取整
pad_right = pad_w - pad_left
3.卷积padding的实战分析
接下来我们通过在TensorFlow中使用卷积和池化函数来分析padding参数在实际中的应用,代码如下:

# -*- coding: utf-8 -*-
import tensorflow as tf # 首先,模拟输入一个图像矩阵,大小为5*5
# 输入图像矩阵的shape为[批次大小,图像的高度,图像的宽度,图像的通道数]
input = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 1])) # 定义卷积核,大小为2*2,输入和输出都是单通道
# 卷积核的shape为[卷积核的高度,卷积核的宽度,图像通道数,卷积核的个数]
filter1 = tf.Variable(tf.constant([-1.0, 0, 0, -1], shape=[2, 2, 1, 1])) # 卷积操作 strides为[批次大小,高度方向的移动步长,宽度方向的移动步长,通道数]
# SAME
op1_conv_same = tf.nn.conv2d(input, filter1, strides=[1,2,2,1],padding='SAME')
# VALID
op2_conv_valid = tf.nn.conv2d(input, filter1, strides=[1,2,2,1],padding='VALID') init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("op1_conv_same:\n", sess.run(op1_conv_same))
print("op2_conv_valid:\n", sess.run(op2_conv_valid))
VALID模式的分析:
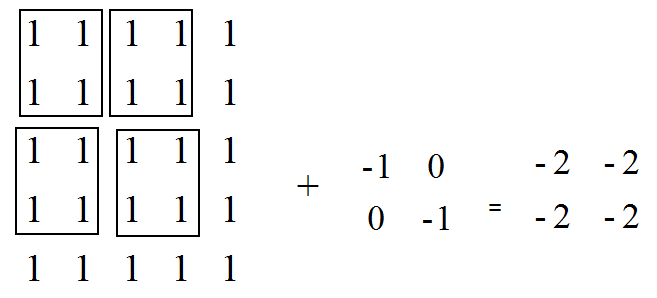
SAME模式分析:
o_w = i_w / s_w = 5/2 = 3
o_h = i_h / s_h = 5/2 = 3 pad_w = max ( (o_w - 1 ) × s_w + f_w - i_w , 0 )
= max ( (3 - 1 ) × 2 + 2 - 5 , 0 ) = 1
pad_left = 1 / 2 =0
pad_right = 1 - 0 =0
# 同理
pad_top = 0
pad_bottom = 1
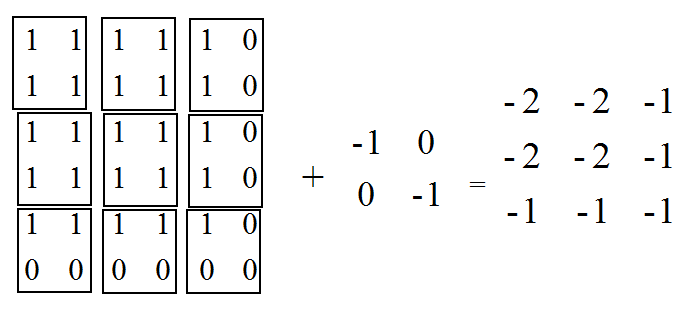
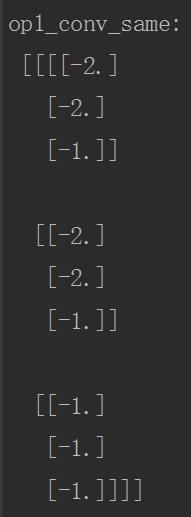
运行代码后的结果如下:
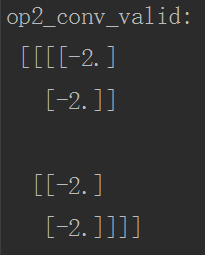
4.池化padding的实战分析
这里主要分析最大池化和平均池化两个函数,函数中padding参数设置和矩阵形状计算都与卷积一样,但需要注意的是:
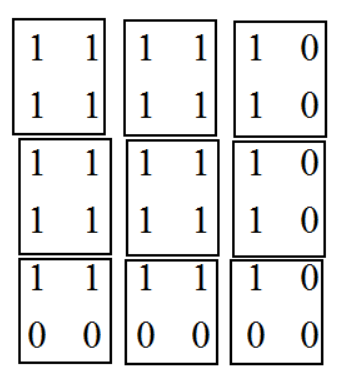
1. 当padding='SAME',计算avg_pool时,每次的计算是除以图像被filter框出的非零元素的个数,而不是filter元素的个数,如下图,第一行第三列我们计算出的结果是除以2而非4,第三行第三列计算出的结果是除以1而非4;
2. 当计算全局池化时,即与图像矩阵形状相同的过滤器进行一次池化,此情况下无padding,即在边缘没有补0,我们直接除以整个矩阵的元素个数,而不是除以非零元素个数(注意与第一点进行区分)
池化函数的代码示例如下:
# -*- coding: utf-8 -*-
import tensorflow as tf # 首先,模拟输入一个特征图,大小为5*5
# 输入图像矩阵的shape为[批次大小,图像的高度,图像的宽度,图像的通道数]
input = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 1])) # 最大池化操作 strides为[批次大小,高度方向的移动步长,宽度方向的移动步长,通道数]
# ksize为[1, 池化窗口的高,池化窗口的宽度,1]
# SAME
op1_max_pooling_same = tf.nn.max_pool(input, [1,2,2,1], strides=[1,2,2,1],padding='SAME')
# VALID
op2_max_pooling_valid = tf.nn.max_pool(input, [1,2,2,1], strides=[1,2,2,1],padding='VALID') # 平均池化
op3_avg_pooling_same = tf.nn.avg_pool(input, [1,2,2,1], strides=[1,2,2,1],padding='SAME')
# 全局池化,filter是一个与输入矩阵一样大的过滤器
op4_global_pooling_same = tf.nn.avg_pool(input, [1,5,5,1], strides=[1,5,5,1],padding='SAME') init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("op1_max_pooling_same:\n", sess.run(op1_max_pooling_same))
print("op2_max_pooling_valid:\n", sess.run(op2_max_pooling_valid))
print("op3_max_pooling_same:\n", sess.run(op3_avg_pooling_same))
print("op4_global_pooling_same:\n", sess.run(op4_global_pooling_same))
运行结果如下:
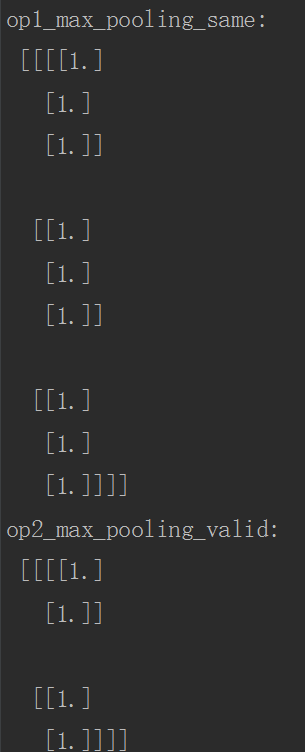
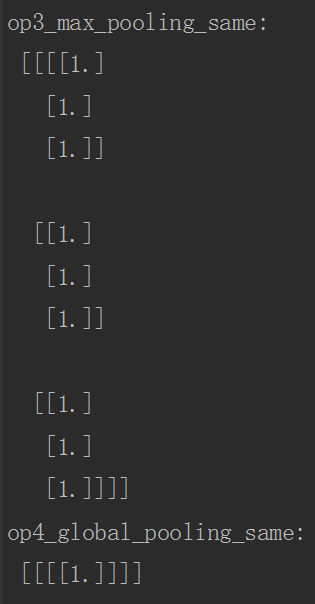
5.总结
在搭建CNN时,我们输入的图像矩阵在网络中需要经过多层卷积和池化操作,在这个过程中,feature map的形状会不断变化,如果不清楚padding参数引起的这些变化,程序在运行过程中会发生错误,当然在实际写代码时,可以将每一层feature map的形状打印出来,了解每一层Tensor的变化。
转载请注明出处:https://www.cnblogs.com/White-xzx/p/9497029.html
卷积的三种模式:full, same, valid的更多相关文章
- 卷积的三种模式:full、same、valid + 卷积输出size的计算
转自https://blog.csdn.net/u012370185/article/details/95238828 通常用外部api进行卷积的时候,会面临mode选择. 这三种mode的不同点:对 ...
- git push :推送本地更改到远程仓库的三种模式
摘要:由于在git push过程中,no-fast-forward 的push会被拒绝,如何解决git push失败的问题?这里面有三种方法,分别会形成merge形式的提交历史,线性形式的提交历史,覆 ...
- App开发三种模式
APP开发三种模式 现在App开发的模式包含以下三种: Native App 原生开发AppWeb App 网页AppHybrid App 混合原生和Web技术开发的App 详细介绍: http:// ...
- [转]VMware Workstation网络连接的三种模式
经常要使用VMWare Workstation来在本地测试不同的操作系统,以前也搞不清楚网络连接三种模式,最近看了几篇文章才算明白.现总结如下: 1. VMware Workstation的虚拟网络组 ...
- LVS三种模式配置及优点缺点比较
目录: LVS三种模式配置 LVS 三种工作模式的优缺点比较 LVS三种模式配置 LVS三种(LVS-DR,LVS-NAT,LVS-TUN)模式的简要配置 LVS是什么: http://www.lin ...
- LVS三种模式配置及优点缺点比较 转
LVS三种模式配置及优点缺点比较 作者:gzh0222,发布于2012-11-12,来源:CSDN 目录: LVS三种模式配置 LVS 三种工作模式的优缺点比较 LVS三种模式配置 LVS三种 ...
- MySQ binlog三种模式
MySQ binlog三种模式及设置方法 1.1 Row Level 行模式 日志中会记录每一行数据被修改的形式,然后在slave端再对相同的数据进行修改 优点:在row level模式下,bin- ...
- delegate,notifucation,KVO三种模式实现通信的优缺点
在开发ios应用的时候,我们会经常遇到一个常见的问题:在不过分耦合的前提下,controllers间怎么进行通信.在IOS应用不断的出现三种模式来实现这种通信: 1.委托delega ...
- 辛星跟您玩转vim第一节之vim的下载与三种模式
首先值得一提的是,我的vim教程pdf版本号已经写完了,大家能够去下载,这里是csdn的下载地址:点此下载 ,假设左边的下载地址挂掉了,也能够自行在浏览器以下输入例如以下地址进行下载:http://d ...
随机推荐
- lvs - mask标记
将两个服务绑定在一个集群服务中 如何将两种请求绑定在一个集群中通过一个director来调度, 这里需要iptable工具配合实现.首先在prerouting链上做一个标记,通过标记来调度 起两个服务 ...
- Codeforces 844F Anti-Palindromize 最小费用流
Anti-Palindromize 想到网络流就差不多了, 拆拆点, 建建边. #include<bits/stdc++.h> #define LL long long #define f ...
- 在vue-cli项目中使用bootstrap的方法示例
在一个html页面中加入bootstrap是很方便,就是一般的将css和js文件通过Link和Script标签就行. 那么在一个用vue-cli生成的前端项目中如何加入?因为框架不一样了,略微要适应一 ...
- jquery正则表达式验证(手机号、身份证号、中文名称)
这篇文章主要介绍了jquery正则表达式验证,实现手机号.身份证号.中文名称验证,感兴趣的小伙伴们可以参考一下 本文实例需要验证的内容:中文姓名.手机号.身份证和地址,验证方法分享给大家供大家参考,具 ...
- Unknown lifecycle phase "mvn"
Unknown lifecycle phase "mvn" maven执行命令错误 : 执行输入命令即可,不需要添加 mvn 此处不需要写mvn,而是执行写compile就行,否 ...
- Ubuntu16.04下的modules模块编译加载
一.首先编写对应的驱动程序的相关内容:(最简单的hello.c程序) #include<linux/init.h> #include<linux/module.h> MODUL ...
- Aladdin and the Flying Carpet(唯一分解定理)
题目大意:给两个数a,b,求满足c*d==a且c>=b且d>=b的c,d二元组对数,(c,d)和(d,c)属于同一种情况: 题目分析:根据唯一分解定理,先将a唯一分解,则a的所有正约数的个 ...
- Java字符串处理
代码: import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner s ...
- java中path和CLASSPATH的配置和意义解析
原文链接 https://blog.csdn.net/eclipse_yin/article/details/51447169 一.JDK的安装和基本配置 JDK的安装: 1) 如果想要获得JDK,那 ...
- ubantu 14.04中安装npm+node.js+react antd
今天折腾了半天,各种安装问题,最终还是装上了: 1.安装npm $ sudo apt install npm 2.升级npm $ sudo npm install npm@latest -g 输入np ...