深入分析HashMap
本文基于jdk1.8
HashMap特点:
HashMap具体方法分析:
put方法分析:
执行流程图:
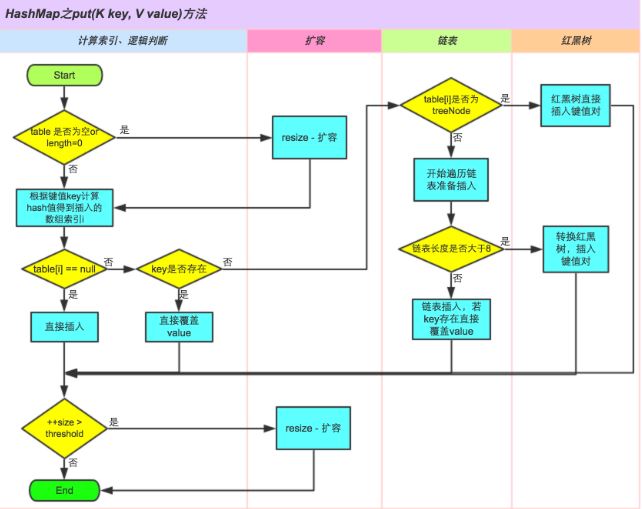
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果链表数组为空或者长度为0,则扩容·
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据hash值找到要插入元素的位置i,若tab[i]为空,则直接插入元素
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果tab[i]链表第一个元素与要插入的元素相等,则直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果tab[i]链表第一个元素与要插入的元素不相等,且第一个元素为树节点,则把要插入的节点插入到红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果不是上两种情况,则依次与链表剩下的元素进行比较,若找到key值相同的元素则覆盖,否则在链表尾部插入新节点
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果链表长度大于8,则将链表转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//将记录修改HashMap的modCount加1
//如果加入元素后size>threshold,则进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//如果链表数组tab不为空,且长度不为0,且根据hash值所确定的tab[i]链表不为空,则进行判断
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果tab[i]链表的第一个元素就是要取的元素则返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//如果要查找的元素不是链表的第一个元素,且第一个元素是树节点,则进入树中进行查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//如果不是上两种情况,则在剩下的链表结点进行查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
// matchValue 作用:区别remove(Key key)与remove(Key key,Value value) 如果matchValue为false,remove(Key key)则删除与key值相等的节点,否则不删除
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//这几组语句在于查找要删除的节点,与get方法类似
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//metchValue的作用,删除操作
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;//将记录修改HashMap的值加1
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
hash()算法分析:
源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
一个较好的hash算法就是让所有的对象中的值都体现用处,hashCode()已经满足了这点,而我们在hashCode()的基础上设置新的hash算法时也要体现这一点,如何体现这一点,就是充分利用hashCode()的结果的所有位。
HashMap中的hash()方法中,hash值为,key的hashCode值与将其无符号右移16位后进行异或运算。作用:key的hashCode所有位都参与了运算,降低了节点碰撞率。
而用hash值与链表数组的长度-1进行相与获得节点的索引值,这样得到的结果与用hash值除以链表数组长度(取模运算)所得到的结果是一样的,并且与运算性能更高,前提是数组的长度必须是2的n次方。只有在这种情况下,取模运算才能转化位为与运算。
更新:看过别的博主对hash算法的分析,他们都是从验证,从举例的角度来论述hash算法的优劣。在《算法4》中,确定哈希表中各节点的位置,用的是取模运算。对于取模运算,各个节点落到各个桶的位置是等概率的(当然前提是各个节点的取值也是随机的,等概率的),HashMap中实现的hash算法(与数组的长度-1进行与运算,)本质上也是取模运算。
例子:对于长度为16的数组,数组长度减一的二进制序列为0000 0000 0000 0000 0000 0000 0000 1111,用它和一个数值进行与运算作用和取模运算是异曲同工,唯一不同的是1,取模运算时用的是key的hashCode值,进行与运算时先将keyCode值的高低16位进行异或运算,用其结果进行进行与运算,这样key的hashCode的所有位的信息又得到了运用。符合优秀哈希算法的规则。
HashMap与Hashtable的比较:
HashMap的使用场景:
深入分析HashMap的更多相关文章
- 深入分析 JDK8 中 HashMap 的原理、实现和优化
HashMap 可以说是使用频率最高的处理键值映射的数据结构,它不保证插入顺序,允许插入 null 的键和值.本文采用 JDK8 中的源码,深入分析 HashMap 的原理.实现和优化.首发于微信公众 ...
- Java8中的HashMap分析
本篇文章是网上多篇文章的精华的总结,结合自己看源代码的一些感悟,其中线程安全性和性能测试部分并未做实践测试,直接是“拿来”网上的博客的. 哈希表概述 哈希表本质上一个数组,数组中每一个元素称为一个箱子 ...
- 面试必问之 ConcurrentHashMap 线程安全的具体实现方式
作者:炸鸡可乐 原文出处:www.pzblog.cn 一.摘要 在之前的集合文章中,我们了解到 HashMap 在多线程环境下操作可能会导致程序死循环的线上故障! 既然在多线程环境下不能使用 Hash ...
- HashMap深入分析及使用要点
本文内容来自深入理解HashMap.从数据结构谈HashMap.HashMap深度分析 先说使用要点. 1.不要在并发场景中使用HashMap HashMap是线程不安全的,如果被多个线程共享的操作, ...
- JAVA提高十二:HashMap深入分析
首先想说的是关于HashMap源码的分析园子里面应该有很多,并且都是分析得很不错的文章,但是我还是想写出自己的学习总结,以便加深自己的理解,因此就有了此文,另外因为小孩过来了,因此更新速度可能放缓了, ...
- HashMap 深入分析
/** *@author annegu *@date 2009-12-02 */ Hashmap是一种非常常用的.应用广泛的数据类型,最近研究到相关的内容,就正好复习一下.网上 ...
- HashMap、HashTable、TreeMap 深入分析及源代码解析
在Java的集合中Map接口的实现实例中用的比較多的就是HashMap.今天我们一起来学学HashMap,顺便学学和他有关联的HashTable.TreeMap 在写文章的时候各种问题搞得我有点迷糊尤 ...
- JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析
因为最近工作太忙了,连续的晚上支撑和上班,因此没有精力来写下这篇博客,今天上午正好有一点空,因此来复习一下不太常用的集合体系大家族中的几个类:WeakHashMap&EnumMap&L ...
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
随机推荐
- 小学四则运算APP 第一阶段冲刺
需求分析 1.相关系统分析员向用户初步了解需求,然后用word列出要开发的系统的大功能模块,每个大功能模块有哪些小功能模块,对于有些需求比较明确相关的界面时,在这一步里面可以初步定义好少量的界面.[1 ...
- Neo4j初探
neo4j-desktop-win64 exe https://neo4j.com/download-thanks-desktop/?edition=desktop&flavour=winst ...
- 批处理-For详解
大纲 一 前言 二 for语句的基本用法 三 for /f (delims.tokens.skip.eol.userbackq.变量延迟) 四 for /r (递归遍历) 五 for /d (遍历目录 ...
- [CB]IPv6 在中国 - 大规模部署进行中 进展明显
IPv6 在中国 - 大规模部署进行中 进展明显 2019年02月04日 08:21 3078 次阅读 稿源:solidot 0 条评论 中国有着世界上最大的网民人口,但它的 IPv6 普及度却处于世 ...
- Win10删除微软拼音输入法的方法
1. 控制面板 2.更换输入法 选择添加语言 添加上英文输入法之后 进行上下移动 然后删除中文输入法即可 需要在英文的语言栏里面添加-选项-增加输入法 然后删除中文即可.
- Jquery 组 tbale表格隔行变色
<!DOCTYPE html><html lang="zh-cn"><head> <meta charset="utf-8&qu ...
- Java和Spring邮件的发送
方法一: java发送电子邮件:这里以发送qq邮件为例: package test; import java.util.Properties; import javax.mail.Authentica ...
- Layui_2.x_上传插件使用
一.上传类 package com.ebd.application.common.utils; import java.awt.geom.AffineTransform; import java.aw ...
- git上传到码云
touch README.md git init git add README.md git add "你的文件" git commit -m "first commit ...
- innerHTML、outerHTML、innerText、outerText的区别及兼容性问题
今天看了很多文章关于innerHTML.outerHTML.innerText.outerText的区别,都是很模糊的一个介绍,所以自己总结下这些区别以及一些重点内容.很多文章在描述这些区别的时候,都 ...