Flume NG部署
本次配置单节点的Flume NG
1、下载flume安装包
下载地址:(http://flume.apache.org/download.html)

apache-flume-1.6.0-bin.tar.gz安装包上传解压到集群上的/usr/hadoop/目录下。
[hadoop@centpy hadoop]$ pwd
usr/hadoop
[hadoop@centpy hadoop]$ ls
hadoop-2.6. zookeeper-3.4. hbase-0.98. jdk1..0_60
[hadoop@centpy hadoop]$ rz [hadoop@centpy hadoop]$ ls
apache-flume-1.8.0-bin.tar.gz jdk1..0_60 hbase-0.98. zookeeper-3.4.6 hadoop-2.6.
[hadoop@centpy hadoop]$ tar -zxf apache-flume-1.8.0-bin.tar.gz
[hadoop@centpy hadoop]$ ls
apache-flume-1.8.0-bin hadoop-2.6.
apache-flume-1.8.-bin.tar.gz jdk1..0_60hbase-0.98.19 zookeeper-3.4.
[hadoop@centpy hadoop]$ rm -f apache-flume-1.8.0-bin.tar.gz
[hadoop@centpy hadoop]$ mv apache-flume-1.8.0-bin/ flume-1.8.0
[hadoop@centpy hadoop]$ ls
jdk1..0_60 flume-1.8.0 hbase-0.98. zookeeper-3.4.6 hadoop-2.6.0
2、配置flume
[hadoop@centpy hadoop]$ cd flume-1.8.0/conf/
[hadoop@centpy conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
[hadoop@centpy conf]$ cp flume-conf.properties.template flume-conf.properties //需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件
[hadoop@centpy conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties [hadoop@centpy conf]$ vi flume-conf.properties #Define sources, channels, sinks
agent1.sources = spool-source1
agent1.channels = ch1
agent1.sinks = hdfs-sink1 #Define and configure an Spool directory source
agent1.sources.spool-source1.channels = ch1
agent1.sources.spool-source1.type = spooldir
agent1.sources.spool-source1.spoolDir = /home/hadoop/test
agent1.sources.spool-source1.ignorePattern = event(_\d{}\-\d{}-\d{}_\d{}_\d{})?\.log(\.COMPLETED)?
agent1.sources.spool-source1.deserializer.maxLineLength = #Configure channels
agent1.sources.ch1.type = file
agent1.sources.ch1.checkpointDir = /home/hadoop/app/flume/checkpointDir
agent1.sources.ch1.dataDirs = /home/hadoop/app/flume/dataDirs #Define and configure a hdfs sink
agent1.sinks.hdfs-sink1.channels = ch1
agent1.sinks.hdfs-sink1.type = hdfs
agent1.sinks.hdfs-sink1.hdfs.path = hdfs://centpy:9000/flume/%Y%m%d
agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true
agent1.sinks.hdfs-sink1.hdfs.rollInterval =
agent1.sinks.hdfs-sink1.hdfs.rollSize =
agent1.sinks.hdfs-sink1.hdfs.rollCount =
#agent1.sinks.hdfs-sink1.hdfs.codeC = snappy
修改集群上的flume-conf.properties配置文件,这里收集日志文件到收集端。配置参数的详细说明可以参考官方文档(https://cwiki.apache.org/confluence/display/FLUME/Getting+Started)。
3、启动并测试Flume
1)首先启动Hadoop集群
[hadoop@centpy hadoop]$ cd hadoop-2.6.0
[hadoop@centpy hadoop-2.6.]$ sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [centpy]
centpy: starting namenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-namenode-centpy.out
centpy: starting datanode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-datanode-centpy.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-secondarynamenode-centpy.out
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-resourcemanager-centpy.out
centpy: starting nodemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-nodemanager-centpy.out
[hadoop@centpy hadoop-2.6.]$ jps
ResourceManager
SecondaryNameNode
NameNode
NodeManager
DataNode
Jps
2)启动Flume
[hadoop@centpy hadoop-2.6.]$ cd ../flume/
[hadoop@centpy flume]$ bin/flume-ng agent -n agent1 -f conf/flume-conf.properties
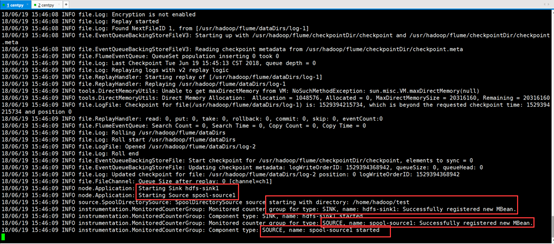
如上图,我们已经成功启动Flume。
3)测试Flume
先上传一个测试文件到我们配置的测试目录中(/home/hadoop/test)
[hadoop@centpy conf]$ cd /home/hadoop/test/
[hadoop@centpy test]$ ls
[hadoop@centpy test]$ rz [hadoop@centpy test]$ ls
template.log
此时Flume会收集日志信息如下:
// :: INFO hdfs.BucketWriter: Creating hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp
(此处会先在数据收集过程中先生成一个.tmp文件用于记录,等到30秒过后数据收集完成则会生成最终文件FlumeData.1529394914599)
// :: INFO file.EventQueueBackingStoreFile: Start checkpoint for /usr/hadoop/flume/checkpointDir/checkpoint, elements to sync =
// :: INFO file.EventQueueBackingStoreFile: Updating checkpoint metadata: logWriteOrderID: , queueSize: , queueHead:
// :: INFO file.Log: Updated checkpoint for file: /usr/hadoop/flume/dataDirs/log- position: logWriteOrderID:
// :: INFO hdfs.BucketWriter: Closing hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp
// :: INFO hdfs.BucketWriter: Renaming hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp to hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599
// :: INFO hdfs.HDFSEventSink: Writer callback called.
我们也可以在Web浏览器查看文件信息

4、Flume 案例分析
下面我们看一下flume的实际应用场景,其示例图如下所示。
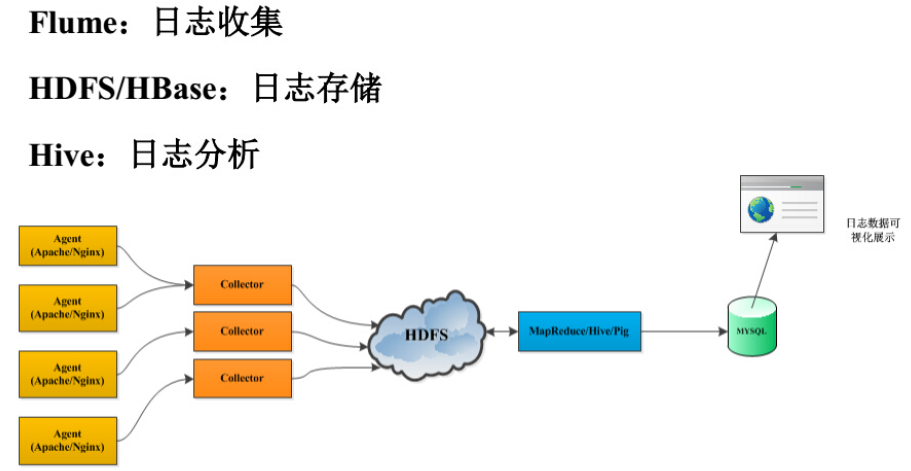
在上面的应用场景中,主要可以分为以下几个步骤。
1、首先采用flume进行日志收集。
2、采用HDFS进行日志的存储。
3、采用MapReduce/Hive进行日志分析。
4、将分析后的格式化日志存储到Mysql数据库中。
5、最后前端查询,实现数据可视化展示。
flume的实际应用场景,相信大家有了一个初步的认识,大家可以根据复杂的业务需求,实现flume来收集数据。这里就不一一讲述,希望大家在以后的学习过程中,学会学习、学会解决实际的问题。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Flume NG部署的更多相关文章
- Flume NG安装部署及数据采集测试
转载请注明出处:http://www.cnblogs.com/xiaodf/ Flume作为日志收集工具,监控一个文件目录或者一个文件,当有新数据加入时,采集新数据发送给消息队列等. 1 安装部署Fl ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
- Flume NG简介及配置
Flume下载地址:http://apache.fayea.com/flume/ 常用的分布式日志收集系统: Apache Flume. Facebook Scribe. Apache Chukwa ...
- Flume NG 简介及配置实战
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用.Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 clo ...
- Flume环境部署和配置详解及案例大全
flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本.HDF ...
- 【Flume NG用户指南】(1)设置
作者:周邦涛(Timen) Email:zhoubangtao@gmail.com 转载请注明出处: http://blog.csdn.net/zhoubangtao/article/details ...
- Flume NG 配置详解(转)
原文链接:[转]Flume NG 配置详解 (说明,名词对应解释 源-Source,接收器-Sink,通道-Channel) 配置 设置代理 Flume代理配置存储在本地配置文件.这是一个文本文件格式 ...
- Flume NG初次使用
一.什么是Flume NG Flume是一个分布式.可靠.和高可用性的海量日志采集.聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据:同时Flume提供对数据的简单处理,并写到各种数 ...
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
随机推荐
- 创建Azure Blob Snapshot的脚本
在前面的文章中介绍了如何创建Azure Blob Snapshot.那篇文章中创建的脚本思路是:遍历所有Storage Account,找到所有vhd文件,进行Snapshot的创建. 但这种方式不够 ...
- C++输入输出知识
1.strtok将字符串中的单词用' '分割出来 #include<iostream> #include<cstdio> #include<cstdlib> #in ...
- ssh配置免登 Ubuntu环境
配置之前,可能需要修改下每台机器的hostname,修改方法 1.直接修改hostname文件:sudo vi /etc/hostname 2.重启服务器:shutdown -r now Ubuntu ...
- 你做电商死法TOP10:你中了几枪?
有相关报道说淘宝目前只有3%的店铺能够盈利,其余97%的店铺基本上都成了炮灰.这是一个非常可怕的数字,都说不赚钱的电商是犯罪,那么,是什么原因导致了会有如此庞大的电商群体一如既往的走在这千军万马的不归 ...
- UI面试题(1)
1.请创建一个数组对象[@“ad”,@“bc”,@“sdf”,@“yu”],并且对该数组对象进行排序(使用冒泡排序); NSMutableArray *array = [NSMutableArraya ...
- position应用之相对父元素的定位
分别添加以下style即可: 父元素position:relative; 子元素position:absolute; right:0px; bottom:0px;
- LEADTOOLS V19: 世界领先的图像处理开发工具包强势来袭
投递人 itwriter 发布于 2014-12-22 16:04 评论(0) 有214人阅读 原文链接 [收藏] « » LEAD 科技于 2014 年 12 月 11 日发布 LEA ...
- window 删除文件提示指定的文件名无效或太长
方法0: 使用 chkdsk 磁盘修复工具 .单击“开始”,点击“运行”,输入cmd并回车打开命令提示符窗口: .在此窗口输入以下命令: 例如:检查并修复D分区 chkdsk D: /f 回车,输入 ...
- 存储引擎InnoDB
InnoDB是MySQL的默认存储引擎, InnoDB支持的最大存储限制是64TB,支持事务安全,支持行锁,支持B树索引,不支持哈希索引和全文索引,支持集群索引,支持数据缓存,支持索引缓存,不支持数据 ...
- hdu1065
#include <stdio.h> int main() { int t; double x, y; scanf("%d", &t); for; i < ...