scrapy爬取图片并自定义图片名字
1 前言
Scrapy使用ImagesPipeline类中函数get_media_requests下载到图片后,默认的图片命名为图片下载链接的哈希值,例如:它的下载链接是http://img.ivsky.com/img/bizhi/pre/201101/10/harry_potter5-017.jpg,哈希值为7710759a8e3444c8d28ba81a4421ed,那么最终的图片下载到指定路径后名称为7710759a8e3444c8d28ba81a4421ed.JPG。想要自定义图片名称则需要借助ImagesPipeline类中item_completed()函数来重命名。
{kind=link}
2 爬虫过程
爬虫过程就不赘述了,链接请参看:https://www.cnblogs.com/mrtop/p/10180072.html,本文章重点介绍如何自定义图片名称。爬虫运行后获得的图片如下图:
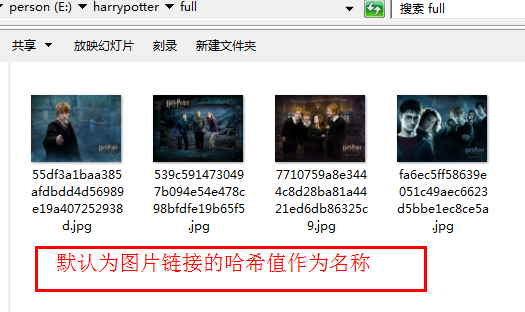
3 自定义图片名称具体方法
3.1 自定义图片名称代码
import os
from harry.settings import IMAGES_STORE as IMGS
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class HarryPipeline(object):
def process_item(self, item, spider):
return item
class HarryDownLoadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for imgurl in item['img_url']:
yield Request(imgurl)
def item_completed(self, results, item, info):
print ('******the results is********:',results)
os.rename(IMGS + '/' + results[0][1]['path'], IMGS + '/' + item['img_name'])
def __del__(self):
#完成后删除full目录
os.removedirs(IMGS + '/' + 'full')
注:对于def __del__(self)函数可要可不要,因为重命名过程是携带路径重命名,所以默认生成的full文件夹就为空,只是顺手删除空文件夹(如果里面有文件存在是删除不了的)
3.2 自定义图片名称代码详细解析
3.2.1 get_media_requests函数
get_media_requests方法的原型为:
def item_completed(self, results, item, info):
if isinstance(item, dict) or self.images_result_field in item.fields:
item[self.images_result_field] = [x for ok, x in results if ok]
return item
可以看到get_media_requests有三个参数,
第一个是self,这个不必多说;
第二个是 item,这个就是 spiders传递过来的 item
第三个是 info,看名字就知道这是用来保存信息的,至于是什么信息,info其实是一个用来保存保存图片的名字和下载链接的列表
3.2.2 Item_completed函数
item_completed方法的原型如下:
def item_completed(self, results, item, info):
if isinstance(item, dict) or self.images_result_field in item.fields:
item[self.images_result_field] = [x for ok, x in results if ok]
return item
注意到 item_completed里有个 results参数,results参数保存了图片下载的相关信息,将他print看看具体信息:
[(True, {'url': 'http://img.ivsky.com/img/bizhi/pre/201101/10/harry_potter5-015.jpg', 'path': 'full/539c5914730497b094e5c98bfdfe19b65f5.jpg', 'checksum': '37d23ffb0ab983ac2da9a9d'})]
真实结构为一个list [(DownLoad_success_or_failure),dict],字典中含有三个键:1、'url':图片路径 2、'path':图片下载后的保存路径 3、'checksum':校验码
从中我们可以看到只要我们修改字典中图片保存路径(路径详细到图片名称)的值,那么我们就能自定义图片名称。
关键代码为:
os.rename(IMGS + '/' + results[0][1]['path'], IMGS + '/' + item['img_name'])
解释:rename函数,results[0][1]['path']意思就是:在result这个list中找到图片的名称,其中我们也可以看到这个图片的位置是绝对路径,所以需要携带路径IMGS修改。
4 更新pipelines.py后运行结果

如有疑问,欢迎留言讨论交流,转载请注明出处。
scrapy爬取图片并自定义图片名字的更多相关文章
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- scrapy 爬取图片
scrapy 爬取图片 1.scrapy 有下载图片的自带接口,不用我们在去实现 setting.py设置 # 保存log信息的文件名 LOG_LEVEL = "INFO" # L ...
- 用scrapy爬取搜狗Lofter图片
用scrapy爬取搜狗Lofter图片 # -*- coding: utf-8 -*- import json import scrapy from scrapy.http import Reques ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- scrapy框架爬取图片并将图片保存到本地
如果基于scrapy进行图片数据的爬取 在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 配置文件中:IMAGES_STORE = './imgsLib' 在管道文件中进行管道类的制定: f ...
- Scrapy 爬取某网站图片
1. 创建一个 Scrapy 项目,在命令行或者 Pycharm 的 Terminal 中输入: scrapy startproject imagepix 自动生成了下列文件: 2. 在 imagep ...
- 【Python】- scrapy 爬取图片保存到本地、且返回保存路径
https://blog.csdn.net/xueba8/article/details/81843534
随机推荐
- iPad游戏 Calcculator: The Game 程序自动计算求解方法
今天在iPad上下了个小游戏,主要是一个计算器的界面,有开始值,目标值,限定步数,以及一些加减乘除,还有作者脑洞想出来的功能键,主要有左移,直接把一个数加到末尾,将其中的某个数改为另一个数等等..玩到 ...
- Unexpected token o in JSON at position 1
ajax返回的数据已经是object格式,无需再使用“var newjsonObj = JSON.parse(jsonObj)” 进行转换.
- Linux 中将用户添加到指定组的指令
将一个已有用户 testuser 增加到一个已有用户组 root 中,使此用户组成为该用户的附加用户组,可以使用带 -a 参数的 usermod 指令.-a 代表 append, 也就是将用户添加到 ...
- 如何将一个div水平垂直居中
方案一: div绝对定位水平垂直居中[margin:auto实现绝对定位元素的居中], 兼容性:,IE7及之前版本不支持 div{ width: 200px; height: 200px; backg ...
- C#+Winform记事本程序
第17章 记事本 如何使用Visual C# 2010设计一个Windows应用程序——记事本,学习,可以进一步掌握MenuStrip(菜单).ToolStrip(工具栏).RichTextBox(高 ...
- C#进阶学习笔记(个人整理)
学习笔记 第一章: 一.回顾数组 1.变量 : 只能存储一个数据 2.数组 :存储固定大小的相同类型的数据 3.对象 : 存储多个相同/不同类型的数据 4.集合 : 特殊的容器,存储N个相同/不同类型 ...
- linux mysql5.7 安装、 开机启动
一.安装 wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz h ...
- mysql,oracle表数据相互导入
mysql导入oracle: 例如mysql中有ts_user_info表,现在要导入到oracle中的user_info表 1:导出mysql表数据到data.txt文件 mysql> sel ...
- 解决SecureCRT远程Linux遇到文件不能直接往CRT里直接拖入的问题
不能拖入到CRT的第一个原因可能是Options-->Global Options-->Terminal中的Mouse下的Copy on select没有勾选.当发现自己勾选了也不能往里面 ...
- wlr快捷键
ref:http://www.cnblogs.com/zhangyang/archive/2011/07/22/2113856.html Windows Live Writer提供了许多方便的快捷 ...