day 69 ORM 多表增删改查操作
http://www.cnblogs.com/liwenzhou/p/8660826.html
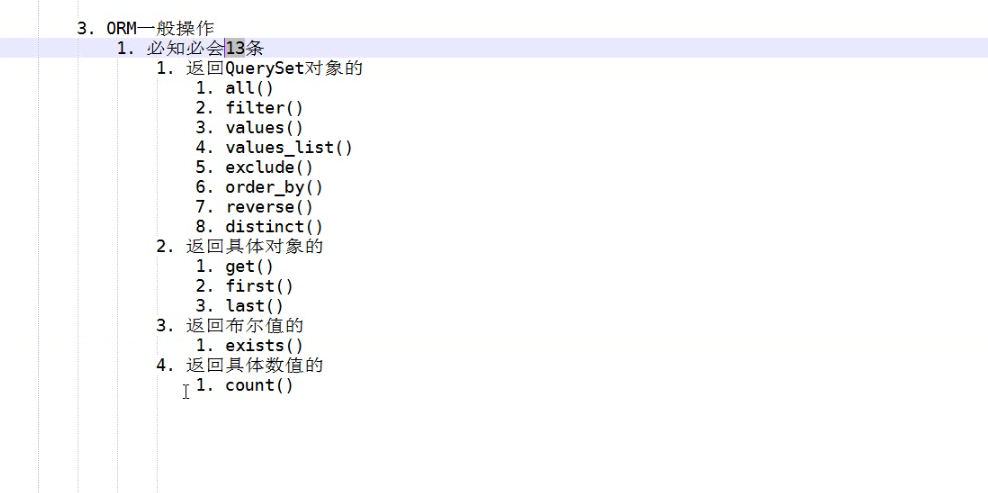




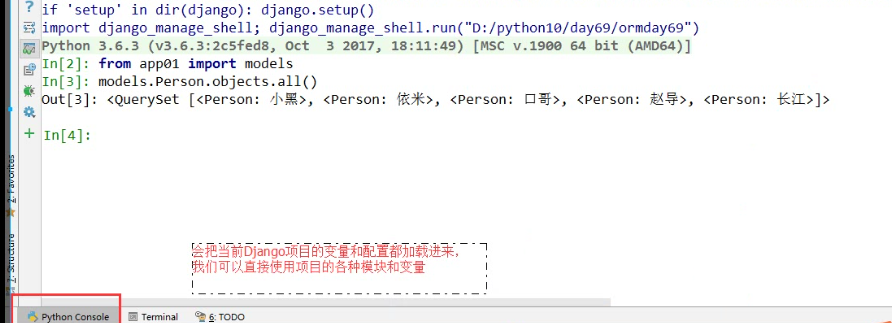
下面的代码是在 python console中配置的。 关闭pycharm会消失。
from app01 import models
models.Person.objects.all()
<QuerySet [<Person: 小黑>, <Person: 小黑2>, <Person: 小黑6>]>

在Python脚本中调用Django环境
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup() from app01 import models books = models.Book.objects.all()
print(books)1.查询所有人
ret = models.Person.objects.all()
print(ret)
结果:
<QuerySet [<Person: 小黑>, <Person: 小黑2>, <Person: 小黑6>]>
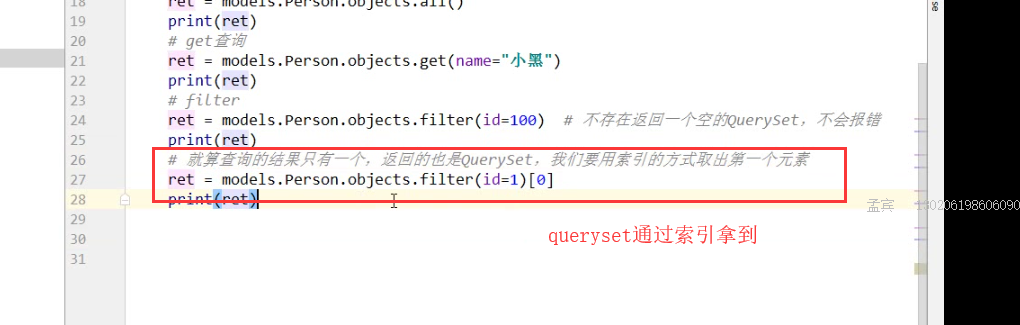
2.get的查询方法
ret = models.Person.objects.get(id =1) #id为 不存在的话会报错
print(ret)
结果:
小黑 3.filter查询
ret = models.Person.objects.filter(name ="小黑")
print(ret)
结果
<QuerySet [<Person: 小黑>]>
为什么会是这个结果因为:
class Queryset(list):
4. 查询id大于1的数据
ret =models.Person.objects.filter(id__gt=1) #如果id等于100 ,不会报错,会返回一个空的QuerySet对象。
print(ret)
结果:
<QuerySet [<Person: 小黑2>, <Person: 小黑6>]>
5.查询id等于1的数据,并取出里面的数据通过索引的方式取出来
ret =models.Person.objects.filter(id=1)[0]
print(ret)
结果:
小黑
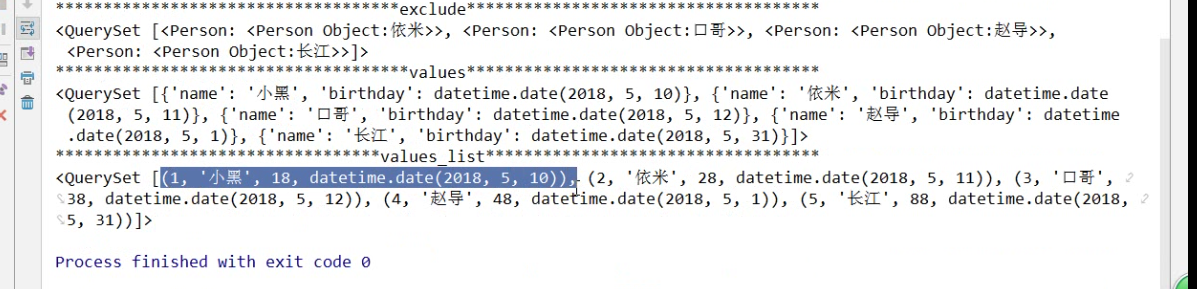
6.exclude
print('exclude'.center(120,'*'))
ret =models.Person.objects.exclude(id=1)
print(ret)
结果
********************************************************exclude*********************************************************
<QuerySet [<Person: 小黑2>, <Person: 小黑6>]>
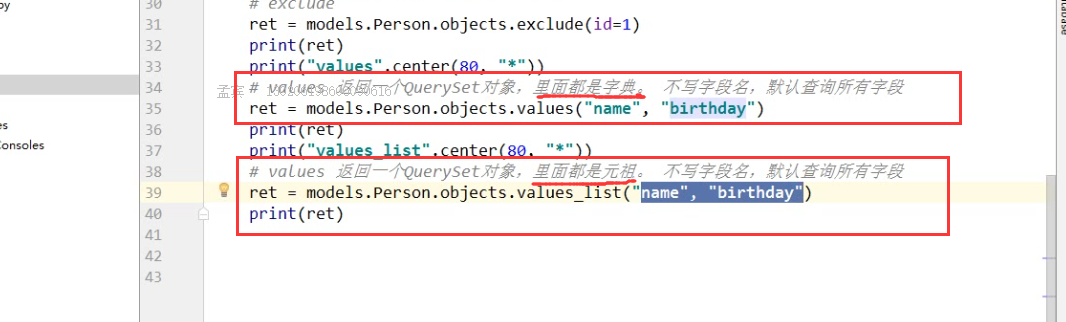
7.values(不写字段名,默认查询所有的字段)
ret = models.Person.objects.values('birthday')
print(ret)
结果
<QuerySet [{'birthday': datetime.date(2018, 5, 10)}, {'birthday': datetime.date(2018, 5, 25)}, {'birthday': datetime.date(2018, 5, 3)}]>
8.values_list, 返回一个QuerySet对象,里面都是元组,不写字段,会查询所有
ret = models.Person.objects.values_list('name','birthday')
print(ret)
结果
<QuerySet [('小黑', datetime.date(2018, 5, 10)), ('小黑2', datetime.date(2018, 5, 25)), ('小黑6', datetime.date(2018, 5, 3))]>
9 .order_by 对查询结果进行排序
ret = models.Person.objects.all().order_by('birthday')
print(ret)
相当于设置元类 在Person类的下面
class meta:
ordering =(‘birthday’)
结果
<QuerySet [<Person: 小黑6>, <Person: 小黑>, <Person: 小黑2>]>
10.reverse 将一个有序的QuerySet进行反转
ret =models.Person.objects.all().order_by('birthday').reverse()
print(ret)
结果:
<QuerySet [<Person: 小黑2>, <Person: 小黑>, <Person: 小黑6>]>
11. count 返回QuerySet中对象的个数
ret =models.Person.objects.all().count()
print(ret)
结果
3 12. first 返回QuerySet对象中第一个元素
ret =models.Person.objects.first()
print(ret)
结果:
小黑 13. last 返回QuerySet对象中最后一个元素
ret =models.Person.objects.last()
print(ret)
结果:
小黑6 14. exist 判断表里面有没有数据
ret =models.Person.objects.exists()#Person表中含有数据 返回True ,如果是空白则为False
print(ret)
结果:
True ,
二 、单表的双下划线查询
1. 查询id值大于1 小于4的结果.
ret = models.Person.objects.filter(id__gt=,id__lt=)
print(ret)
结果
<QuerySet [<Person: 小黑2>, <Person: 小黑6>]>
2. IN 操作查询id在【1,3,5,6】
ret = models.Person.objects.filter(id__in=[1,3,5,6])
print(ret)
结果:
<QuerySet [<Person: 小黑>, <Person: 小黑6>]>
3. exclude 排除在这些id的条目
ret = models.Person.objects.exclude(id__in=[1,3,5,6])
print(ret) 结果:
<QuerySet [<Person: 小黑2>]>
4. name_contains= (name__icontains 忽略大小写)
ret =models.Person.objects.filter(name__contains="6")
print(ret)
输出结果:
<QuerySet [<Person: 小黑6>]>
5. id_range =
ret =models.Person.objects.filter(id__range=[1,2]) #相当于sql语句的between 1 and 2
print(ret)
结果:
<QuerySet [<Person: 小黑>, <Person: 小黑2>]>
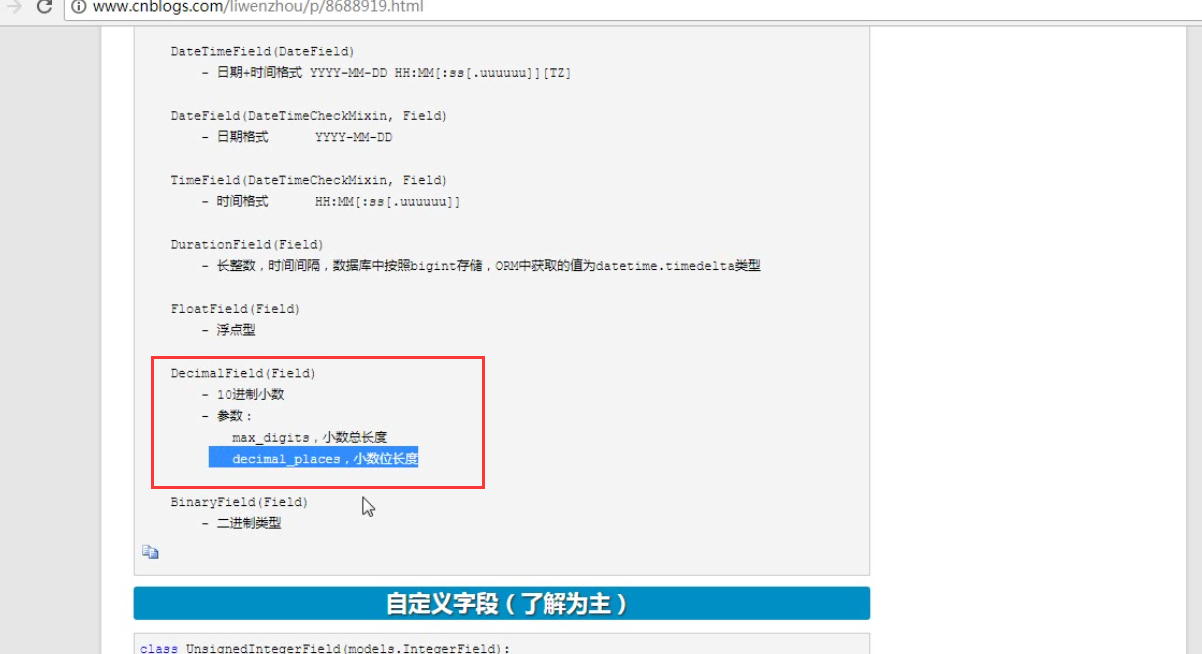
6. 日期和时间字段还可以有以下写法:
ret =models.Person.objects.filter(birthday__year=2018)
print(ret)
ret =models.Person.objects.filter(birthday__month=5)
print(ret) 结果:
<QuerySet [<Person: 小黑>, <Person: 小黑2>, <Person: 小黑6>]>
<QuerySet [<Person: 小黑>, <Person: 小黑2>, <Person: 小黑6>]>
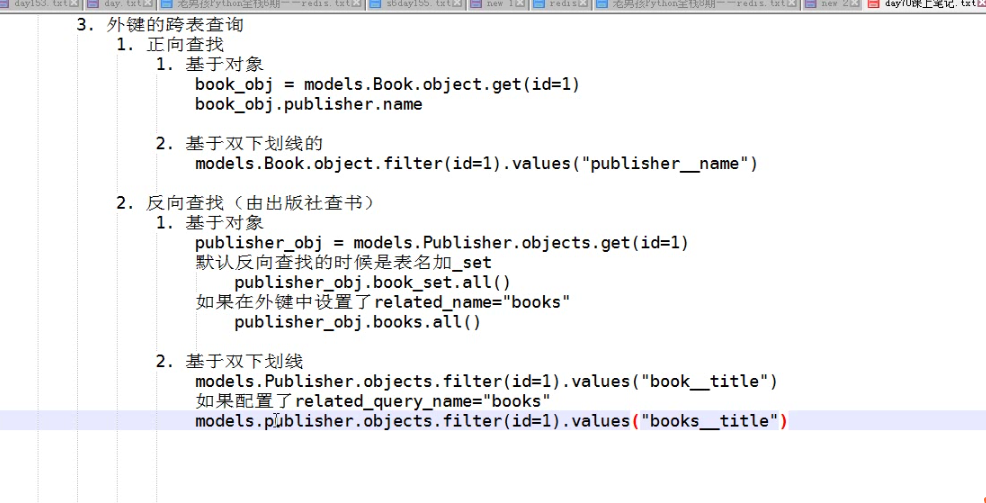
三、正向查询
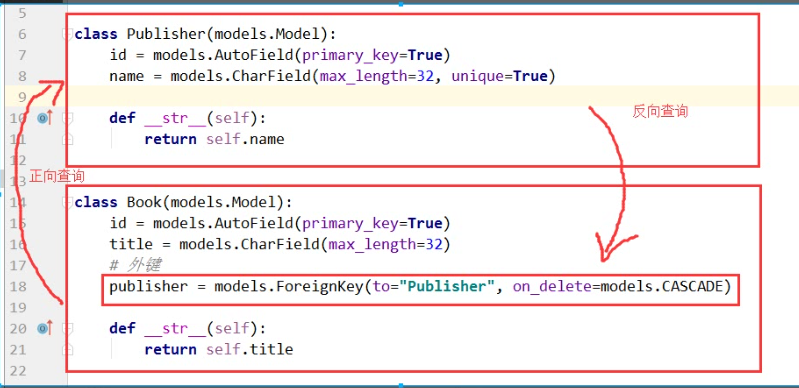
# 外键的查询操作
# 正向查询 方法一、
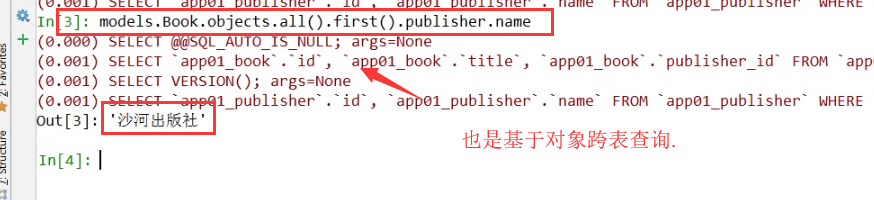
#基于对象 跨表查询
book_obj =models.Book.objects.all().first()
ret = book_obj.publisher #出版社对象
print(ret,type(ret))
ret=book_obj.publisher.name
print(ret,type(ret)) # 和我这本书关联的出版社对象. 结果:
这是沙河第一出版社对象 <class 'app01.models.Publisher'>
沙河第一出版社 <class 'str'>
正向查询方法二、
# 查询id是1的书的出版社的名称.
#双下划线就表示跨了一张表.
book_obj=models.Book.objects.filter(id=1).values('publisher__name')
print(ret)
结果:
沙河第一出版社
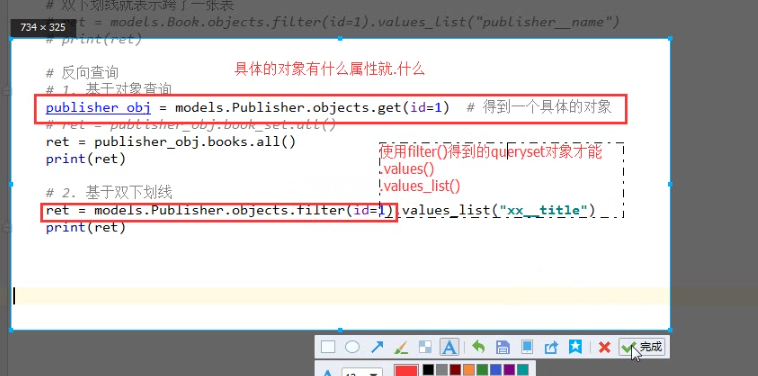
四、反向查询
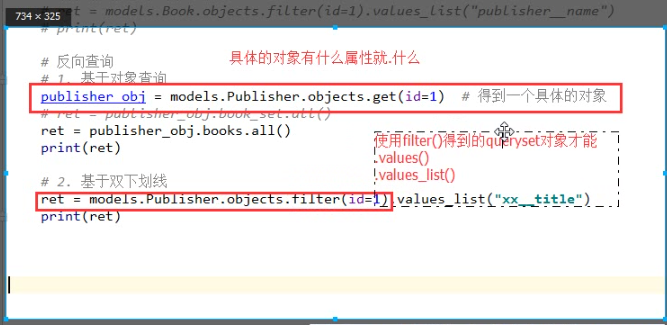
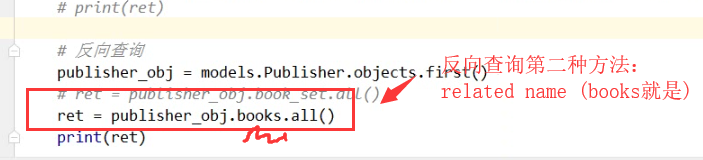
# # 反向查询。用set关键字 (基于对象 查询)
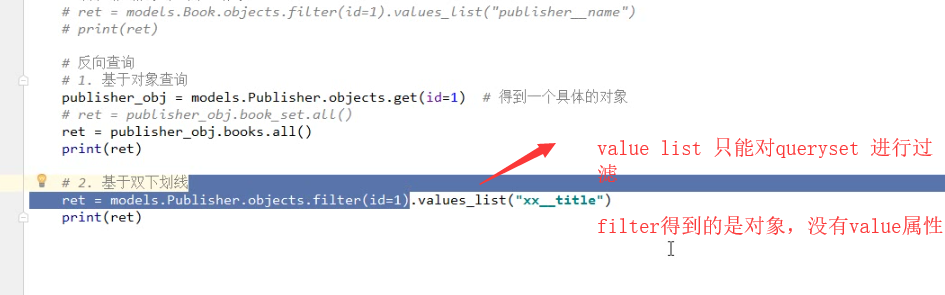
publisher_obj =models.Publisher.objects.first()
# ret =publisher_obj.book_set.all()
# print(ret) # #另外一种写法 (基于双下滑线)
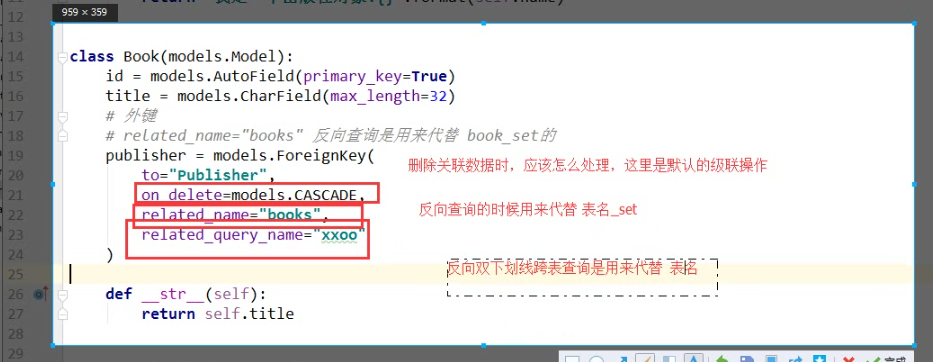
ret =publisher_obj.books.all() #books 为在Book类里设置的related_name 关键字的值
print(ret) 结果:
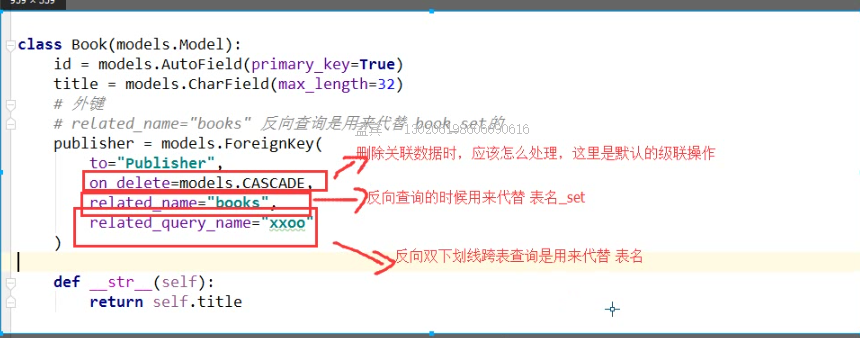
<QuerySet [<Book: 跟老男孩学linux>, <Book: java>]> related_name ='books' 反向查询是用来代替book_set的 根据双下划线 ret =modules.Publisher.objects.filter(id=1).value_list('ooxx__tile') #related_query_name ='ooxx'

五、多对多查询. ManytoManyField
# 多对多 .create
author_obj = models.Author.objects.first()
print(author_obj.name)
#查询小黑1 写过的书
ret =author_obj.books.all()
print(ret) # . create
# 通过作者创建一本书,会自动保存,
# 做了两件事
# 。在book表里创建一本新书,.在作者和书的关系表里添加关联
author_obj.books.create(title ='金老板自传',publisher_id = ) 结果会在book表和book author关系表里自动添加数据。
add
# .add
book_boj =models.Book.objects.get(id =)
author_obj.books.add(book_boj ) # 添加多个
book_objs =models.Book.objects.filter(id__gt=)
author_obj.books.add(*book_objs) #要把列表打算再传进去.
#直接添加id
author_obj.books.add()
remove
# remove 从金老板关联的书里吧开船删掉
# book_obj=models.Book.objects.get(title='gen金老板学开船')
# author_obj.books.remove(book_obj) book_obj =models.Book.objects.get(title="java")
print(book_obj)
author_obj.books.remove(book_obj)
day 69 ORM 多表增删改查操作的更多相关文章
- ORM多表增删改查
一 创建多表 在models.py里创建4张表:Author(作者).AuthorDetail(作者详细信息).Publish(出版社).Book(书) 四张表关系为: (1)首先创建一对一关系.On ...
- JAVA 操作远程mysql数据库实现单表增删改查操作
package MysqlTest; import java.sql.DriverManager; import java.sql.ResultSet; import com.mysql.jdbc.C ...
- Django项目的创建与介绍.应用的创建与介绍.启动项目.pycharm创建启动项目.生命周期.三件套.静态文件.请求及数据.配置Mysql完成数据迁移.单表ORM记录的增删改查
一.Django项目的创建与介绍 ''' 安装Django #在cmd中输入pip3 #出现这个错误Fatal error in launcher: Unable to create process ...
- ORM之单表增删改查
ORM之单表增删改查 在函数前,先导入要操作的数据库表模块,model from model所在的路径文件夹 import model 在views文件中,加的路径: #就一个app01功能的文件 ...
- GZFramwork数据库层《三》普通主从表增删改查
运行结果: 使用代码生成器(GZCodeGenerate)生成tb_Cusomer和tb_CusomerDetail的Model 生成器源代码下载地址: https://github.com/Gars ...
- GZFramwork数据库层《一》普通表增删改查
运行结果: 使用代码生成器(GZCodeGenerate)生成tb_MyUser的Model 生成器源代码下载地址: https://github.com/GarsonZhang/GZCode ...
- Django框架(八)--单表增删改查,在Python脚本中调用Django环境
一.数据库连接配置 如果连接的是pycharm默认的Sqlite,不用改动,使用默认配置即可 如果连接mysql,需要在配置文件中的setting中进行配置: 将DATABASES={} 更新为 DA ...
- Django框架(九)—— 单表增删改查,在Python脚本中调用Django环境
目录 单表增删改查,在Python脚本中调用Django环境 一.数据库连接配置 二.orm创建表和字段 三.单表增删改查 1.增加数据 2.删除数据 3.修改数据 4.查询数据 四.在Python脚 ...
- 48.Python中ORM模型实现mysql数据库基本的增删改查操作
首先需要配置settings.py文件中的DATABASES与数据库的连接信息, DATABASES = { 'default': { 'ENGINE': 'django.db.backends.my ...
随机推荐
- vmware14中安装centos7并使用docker发布spring-boot项目
1.vmare中centos7安装(同一路由器无线网络下) 1.1选择桥接模式 1.2修改配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33(这里不一 ...
- oracle pl/sql程序
简单的pl/sql程序 declare begin dbms_output.put_line('hello world'); end; 什么是PL/SQL? pl/sql(Procedure lang ...
- IDEA 的VM Option设置加快页面的加载速度
VM Option的设置: -Xms1024M -Xmx2048M -XX:PermSize=128M -XX:MaxPermSize=256M
- Ubuntu下安装VirtualBox并为其添加USB支持
1.下载VirtualBox软件包和USB支持包 下载网址均为官方网站(可在此查看其使用教程):https://www.virtualbox.org/wiki/Downloads (若下载各平台各版本 ...
- Fiddler的钩子hook导致电脑无法连上网络
今天,电脑怎么都无法连上网络,重启了几次电脑也不行,网络环境是没有问题的,后来同事告诉我,Fiddler有一个BUG,就是Fiddler获取钩子之后没有释放掉,必须启动Fiddler,再关闭Fiddl ...
- eclipse缓存太重,新手最容易中招
有4种方法,从上到下清理:
- mysql 查询表 的所有字段名称
select COLUMN_NAME from information_schema.COLUMNS where table_name = 'your_table_name' and table_sc ...
- jsp调用java servlet
1.依赖jar servlet-api.jar 2.工程结构 3.java servlet实现类 package testServlet; import java.io.IOException; im ...
- MySQL】存储过程、游标、循环简单实例
create procedure my_procedure() -- 创建存储过程 begin -- 开始存储过程 declare my_id varchar(32); -- 自定义变量1 decla ...
- ics
5.网分用法 时延测试: Format ->Delay Scale Ref -> AUTO SCALE Marker Search -> TRACKING[ON OFF]这样以后把M ...