Sequence Classification
Natural Language Processing with Python
Charpter 6.1
import nltk
from nltk.corpus import brown def pos_features(sentence,i,history):
features = {"suffix(1)":sentence[i][-1:],
"suffix(2)":sentence[i][-2:],
"suffix(3)":sentence[i][-3:]}
if i == 0:
features["prev-word"]="<STAR>"
features["prev_tag"] ="<STAR>"
else:
features["prev_word"]=sentence[i-1]
features["prev_tag"]=history[i-1]
return features class ConsecutivePosTagger(nltk.TaggerI):
def __init__(self,train_sents):
train_set=[]
for tagged_sent in train_sents:
history=[]
untagged_sent = nltk.tag.untag(tagged_sent)
for i,(word,tag) in enumerate(tagged_sent):
featureset=pos_features(untagged_sent,i,history)
train_set.append((featureset,tag))
history.append(tag)
self.classifier=nltk.NaiveBayesClassifier.train(train_set) def tag(self,sentence):
history=[]
for i,word in enumerate(sentence):
featureset=pos_features(sentence,i,history)
tag=self.classifier.classify(featureset)
history.append(tag)
return zip(sentence,history) def test_ConsecutivePosTagger():
tagged_sents=brown.tagged_sents(categories='news')
size = int(len(tagged_sents) * 0.1)
train_sents, test_sents = tagged_sents[size:], tagged_sents[:size]
tagger = ConsecutivePosTagger(train_sents) print tagger.evaluate(test_sents)
流程为:
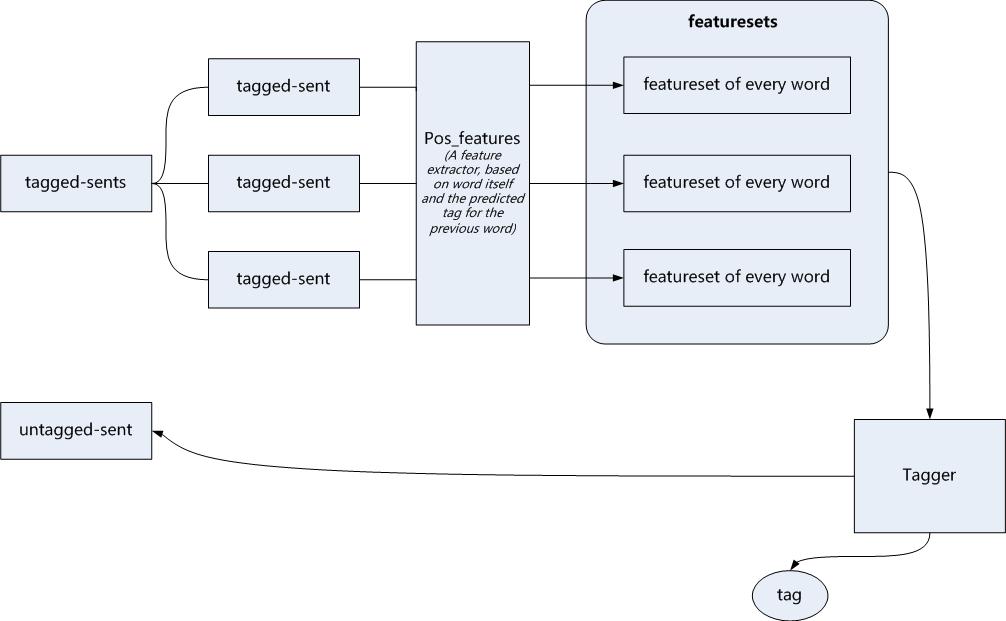
结果为:
0.796940194715
Sequence Classification的更多相关文章
- Kraken taxonomic sequence classification system
kraken:是一个将分类标签打到短DNAreads上的分类序列器.
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- RNN,写起来真的烦
曾经,为了处理一些序列相关的数据,我稍微了解了一点递归网络 (RNN) 的东西.由于当时只会 tensorflow,就从官网上找了一些 tensorflow 相关的 demo,中间陆陆续续折腾了两个多 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Accord.NET Framework 介绍
阅读目录 1.基本功能与介绍 Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET ...
- [Tensorflow] RNN - 02. Movie Review Sentiment Prediction with LSTM
From: Predicting Movie Review Sentiment with TensorFlow and TensorBoard Ref: http://www.cnblogs.com/ ...
- 自然语言处理领域重要论文&资源全索引
自然语言处理(NLP)是人工智能研究中极具挑战的一个分支.随着深度学习等技术的引入,NLP领域正在以前所未有的速度向前发展.但对于初学者来说,这一领域目前有哪些研究和资源是必读的?最近,Kyubyon ...
- [转]NLP Tasks
Natural Language Processing Tasks and Selected References I've been working on several natural langu ...
- .NET数据挖掘与机器学习开源框架
1. 数据挖掘与机器学习开源框架 1.1 框架概述 1.1.1 AForge.NET AForge.NET是一个专门为开发者和研究者基于C#框架设计的,他包括计算机视觉与人工智能,图像处理,神经 ...
随机推荐
- A convenient way of installing(compiling) VIM with YCM
Ah, while I am still downloading LLVM from github(very slow.. and very large in size). I come with m ...
- linux C++通过ntp协议获取网络时间
转自:http://blog.csdn.net/ccjjyy/article/details/42871993 #include <stdio.h> #include <sys/ty ...
- as3 公式
AS3缓动公式:sprite.x += (targetX - sprite.x) * easing;//easing为缓动系数变量sprite.y += (targetY - sprite.y) * ...
- jquery_api(事件一)
一 .unload在火狐,谷歌无法弹出alerta是因为这两个浏览器默认组织alert弹出,unload事件可以进行一些对象销毁,事件解除绑定等清理工作. 如果你想在用户离开页面之前确认是否离开,最好 ...
- 转:WebDriver(Selenium2) 判断页面是否刷新的方法
public static boolean waitPageRefresh(WebElement trigger) { int refreshTime = 0; boolean isRefresh = ...
- Android 学习 之 无需类名启动其他程序
在网上搜索了一会相关的实现代码,发现所有的文章都说是需要包名和类名.但是人家的程序,我们怎么可能知道哪个是第一个启动的Activity?所以,真正用在项目上,那种方法基本上没什么用的.于是查看官方文档 ...
- PAT (Advanced Level) 1097. Deduplication on a Linked List (25)
简单题. #include<cstdio> #include<cstring> #include<cmath> #include<vector> #in ...
- HDU 5480 Conturbatio
区间求和不更新,开个数组记录一下前缀和就可以了 #include<cstdio> #include<cstring> #include<cmath> #includ ...
- 偶然发现www.ghostdogtattoo.com/ 出现的inner.html转换现象
<script language="javascript">window["\x65\x76\x61\x6c"](function(sqhiu1,v ...
- vsftp访问异常
在LINUX下vsftp建立一个FTP服务器,但通过ftp的命令控制台使用FTP时,ls无法查看目录, 当然更无法上传下载文件了! 出错如下 : ftp> ls 227 Entering Pas ...