Python实现删除目录下相同文件
让我们来分析一下这个问题:首先,文件个数非常多,手工查找是不现实的,再说,单凭我们肉眼,在几千张图片或文件里面找到完全相同的难度也是很大的。所以要用程序实现。那么用程序怎么实现呢?根据什么判断两个文件完全相同呢?
1、首先,根据文件名判断是靠不住的,因为文件名可以被随意更改,但文件内容不变。再说在同一个文件夹下面,也不可能出现两个完全相同的文件名,操作系统不允许的。
2、还有一种方法就是根据文件大小来判断,这不失为一种好办法,但是,文件大小相同的图片可能不一样。再说图片一般都比较小,超过3M的基本没有,大部分不够1M,如果文件夹下面文件特别多,出现大小相同的的文件可能性是相当大的。所以单凭文件大小来比较不靠谱。
3、还有一种方法是读取每张图片的内容,然后比较这个图片的内容和其他图片是否完全相同,如果内容相同那么这两张图片肯定是完全相同的。这种方法看起来是比较完美的,让我们来分析一下他的时空效率:首先每张图片的内容都要和其他图片进行比较,这就是一个二重循环,读取的效率低,比较的效率更低,所有的都比较下来是非常费时的!内存方面,如果预先把所有图片读取到内存可以加快文件的比较效率,但是普通计算机的内存资源有限,如果图片非常多,好几个G的话,都读到内存是不现实的。如果不把所有的文件读取到内存,那么每比较一次之前就要先读取文件内容,比较几次就要读取几次,从硬盘读取数据是比较慢的,这样做显然不合适。
4、那么有没有更好的方法呢?我冥思苦想,绞尽脑汁,最后想到了md5。md5是什么?你不知道吗?额,你火星了,抓紧时间duckduckgo吧!也许你会问,md5不是加密的吗?和我们的问题有关系吗?问得好!md5可以把任意长度的字符串进行加密后形成一个32的字符序列,包括数字和字母(大写或小写),因为字符串任何微小的变动都会导致md5序列改变,因此md5可以看作一个字符串的‘指纹’或者‘信息摘要’,因为md5字符串总共有36的32次方个,所以两个不同的字符串得到一个相同的md5概率是很小的,几乎为0,同样的道理,我们可以得到每个文件的md5,若干文件的md5相同的话就基本上可以肯定两个文件是相同的,因为md5相同而文件不同的概率太小了,基本可以忽略,这样我们就可以这样做:得到每个文件的md5,通过比较md5是否相同我们就可以确定两张图片是否相同。下面是代码实现,python的。
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5=[]
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5:
total_delete += 1
print '删除',file
else:
all_md5.append(filemd5)
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒' if __name__=='__main__':
main()
上面的程序原理很简单,就是依次读取每个文件,计算md5,如果md5在md5列表不存在,就把这个md5加到md5列表里面去,如果存在的话,我们就认为这个md5对应的文件已经出现过,这个图片就是多余的,然后我们就可以把这个图片删除了。下面是程序的运行截图:

我们可以看到,在这个文件夹下面有8674个文件,有31个是重复的,找到所有重复文件共耗时155.5秒。效率不算高,能不能进行优化呢?我分析了一下,我的程序里面有两个功能比较耗时间,一个是计算每个文件的md5,这个占了大部分时间,还有就是在列表中查找md5是否存在,也比较费时间的。从这两方面入手,我们可以进一步优化。
首先我想的是解决查找问题,或许我们可以对列表中的元素先排一下序,然后再去查找,但是列表是变化的,每次都排序的话效率就比较低了。我想的是利用字典进行优化。字典最显著的特点是一个key对应一个值我们可以把md5作为key,key对应的值就不需要了,在变化的情况下字典的查找效率比序列效率高,因为序列是无序的,而字典是有序的,查找起来当然更快。这样我们只要判断md5值是否在所有的key中就可以了。下面是改进后的代码:
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5={}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5.keys():
total_delete += 1
print '删除',file
else:
all_md5[filemd5]=''
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒' if __name__=='__main__':
main()
再看看运行截图
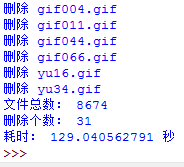
从时间上看,确实比原来快了一点,但是还不理想。下面还要进行优化。还有什么可以优化呢?md5!上面的程序,每个文件都要计算md5,非常费时间,是不是每个文件都需要计算md5呢?能不能想办法减少md5的计算次数呢?我想到了一种方法:上面分析时我们提到,可以通过比较文件大小的方式来判断图片是否完全相同,速度快,但是这种方法是不准确的,md5是准确的,我们能不能把两者结合一下?答案是肯定的。我们可以认定:如果两个文件完全相同,那么这两个文件的大小和md5一定相同,如果两个文件的大小不同,那么这两个文件肯定不同!这样的话,我们只需要先查看文件的大小是否存在在size字典中,如果不存在,就将它加入到size字典中,如果大小存在的话,这说明有至少两张图片大小相同,那么我们只要计算文件大小相同的文件的md5,如果md5相同,那么这两个文件肯定完全一样,我们可以删除,如果md5不同,我们把它加到列表里面,避免重复计算md5.具体代码实现如下:
# -*- coding: cp936 -*-
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5 = {}
all_size = {}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
size = os.stat(real_path).st_size
name_and_md5=[real_path,'']
if size in all_size.keys():
new_md5 = getmd5(real_path)
if all_size[size][1]=='':
all_size[size][1]=getmd5(all_size[size][0])
if new_md5 in all_size[size]:
print '删除',file
total_delete += 1
else:
all_size[size].append(new_md5)
else:
all_size[size]=name_and_md5
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒' if __name__=='__main__':
main()
时间效率怎样呢?看下图:
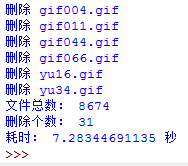
只用了7.28秒!比前两个效率提高了十几倍!这个时间还可以接受
算法是个很神奇的东西,不经意间用一下会有意想不到的收获!上面的代码还可以进一步优化,比如改进查找算法等,读者有啥想法可以和我交流一下。换成C语言来实现可能会更快。呵呵,我喜欢python的简洁!
啊啊!快凌晨两点啦!明天,不,今天还有课呢,悲剧!睡觉去了............
沉睡中。。。。
Python实现删除目录下相同文件的更多相关文章
- python glob删除目录下的文件
使用glob匹配目录下的文件 import os import glob path="./" for infile in glob.glob(os.path.join(path,& ...
- 火狐删除配置文件 会删除目录下所有文件 切记不要把配置文件建立在桌面 恢复软件:易我数据恢复向导 9.0 DiskGenius500
火狐删除配置文件 会删除目录下所有文件 切记不要把配置文件建立在桌面 恢复软件:易我数据恢复向导 9.0 DiskGenius500 结果:由于时间比较常 恢复文件均失败了~
- Linux删除目录下的文件的10种方法
看到了一遍文章,便突发奇想的想起Linux中删除目录下的所有文件的方法:整理了几个,如有不足,还望读者不吝赐教! 删除当前目录下的文件 1.rm -f * #最经典的方法,删除当前目录下的所有类型的文 ...
- Python打开目录下所有文件
用Python打开指定目录下所有文件,统计文件里特定的字段信息. 这里是先进入2017-02-25到2017-03-03目录,然后进入特定IP段目录下,最后打开文件进行统计 import os, gl ...
- Python遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例
遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例: #-*- encoding: utf-8 -*- __author__ = 'liudong' import linecache,sys ...
- linux删除目录下所有文件,但是保留文件夹
删除目录和子目录下所有rpm文件,但是保留文件夹,先cd到想要删除的目录 命令如下 find ./ -name "*.rpm" | xargs rm
- Python语言获取目录下所有文件
#coding=utf-8# -*- coding: utf-8 -*-import osimport sysreload(sys) sys.setdefaultencoding('utf-8') d ...
- Python遍历目录下xlsx文件
对指定目录下的指定类型文件进行遍历,可对文件名关键字进行条件筛选 返回值为文件地址的列表 import os # 定义一个函数,函数名字为get_all_excel,需要传入一个目录 def get_ ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
随机推荐
- jQuery 学习小结
1,jQuery是一个简单的JavaScript库,提供了一系列辅助函数:以下简称jq; 使用jq时,通常将jq代码放到head部分的事件处理方法中,也可以将其单独写出 .js 文件,引入:但无论哪种 ...
- ActiveMQ in Action(5) - Clustering
关键字: activemq 2.5 Clustering ActiveMQ从多种不同的方面提供了集群的支持.2.5.1 Queue consumer clusters ActiveMQ支持 ...
- poj 1142 Smith Numbers
Description While skimming his phone directory in 1982, Albert Wilansky, a mathematician of Lehigh U ...
- python学习入门第一天总结
虽然之前自己也看过许多关于python的视频,但一直没有动力与勇气,所以未能坚持且也没有学得这么深刻,这次希望通过python自动化培训,能够彻底改变自己,通过第一天的python学习,自己学到了许多 ...
- NOIP2011-普及组复赛模拟试题-第一题-NBA总冠军
题目背景 Background 一年两度的期末考要到来了!! 题目描述 Description 又要到考试了,Ljw决定放松一下,就打开电视,看见了篮球赛,他立即想到了每年的NBA总冠军队伍.由 ...
- MySQL性能优化(来源于简书)
1.为查询优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存 ...
- 3.编写BinIoDemo.java的Java应用程序,程序完成的功能是:完成1.doc文件的复制,复制以后的文件的名称为自己的学号姓名.doc。
package zuoye; import java.io.FileInputStream; import java.io.FileOutputStream; public class BinIoDe ...
- javascript performence
1.将脚本放在底部 javascript是阻塞式的加载,如果先加载脚本,后面的dom都没有办法进行渲染,页面会是一片空白: 采用无阻塞下载javascript a.使用<script>标签 ...
- DNS 域名系统 (Domain Name System)
DNS 域名系统 (Domain Name System) 许多应用层软件经常直接使用域名系统 DNS (Domain Name System),但计算机的用户只是间接而不是直接使用域名系统. 因 ...
- [原]innerText与innerHTML区别
window.onload = function () { document.getElementById('btn1').onclick = function () { ...