机器学习的Spark与Scala开发简介
一、机器学习常用开发软件:Spark、Scala
1. Spark简介:
MLlib包含的库文件有:
- 分类
- 降维
- 回归
- 聚类
- 推荐系统
- 自然语言处理
- 在线学习
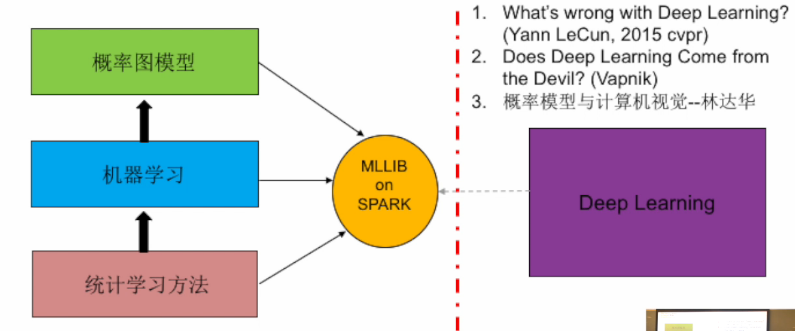
- 统计学习方法:偏向理论性,数理统计的方法,对实时性没有特别要求;
- 机器学习:偏向工程化(包含数据预处理、特征选择、参数优化),有实时性要求,旨在构造一个整体的系统,如在线学习等;
- 概率图模型:构建一个统一的方法论,可以解决一些时序模型,概括了表示、推理、学习的流程,如贝叶斯网络等。
Spark在Standalone模式下的工作原理:

首先,介绍三种重要的角色:
- Application(发布管理任务)带有自己需要的mem和cpu资源量,会在master里排队,最后被分发到worker上执行。app的启动是去各个worker遍历,获取可用的cpu,然后去各个worker launch executor。
- Worker(执行加载任务)每台slave起一个,默认或被设置cpu和mem数,并在内存里做加减维护资源剩余量。Worker同时负责拉起本地的executor backend,即执行进程。
- Master(分配管理资源)接受Worker、app的注册,为app执行资源分配。Master和Worker本质上都是一个带Actor的进程。
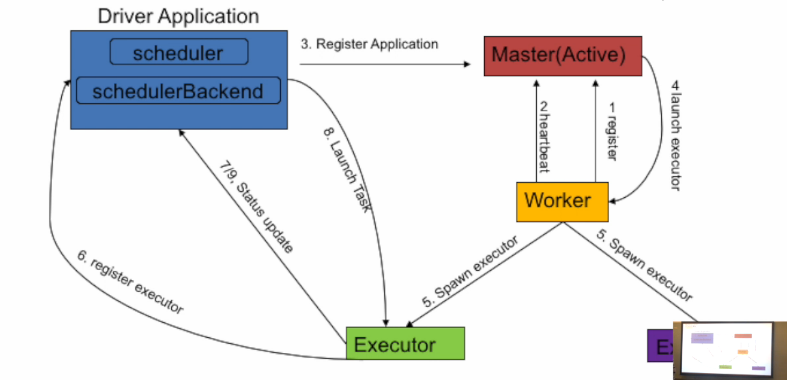
其次,介绍Spark在standalone模式下工作的四个步骤:
- 第一步,(Register Worker)Worker可以认为是一台机器,先在Master注册,是一个启动集群和搜集初始资源的过程,同时给Master维持一个“心跳”;Master负责维护Worker上的资源量和Worker本身host、port等的信息。
- 第二步,(Register Application)Master接收新App的注册。App和Driver都是通过输入一个spark url提交的,最终在master内存里排队;当Master有新的App进来,或资源可用性发生变化时,会触发资源分配的逻辑。
- 第三步,(Launch Executor)Master在资源分配的逻辑里,为App分配了落在若干Worker上的Executors,然后对于每一个Executor,Master通知其Worker去启动。
- 第四步,(Launch Task)App自己来launch task。上面三步都是集群资源的准备过程,App得到了属于自己的资源,包括cpu、内存、起起来的进程及其分布。App内的TaskScheduler和SchedulerBackend是我们熟悉的与task切分、task分配、task管理相关的内容。其中scheduler负责两个重要调度:DAG调度和TASK调度。
2. 函数式编程与Scala:
(1)解释性编程语言,它是一种基于冯诺依曼式架构的语言:
- 修改变量
- 可以赋值
- 包括很多控制语句,如if-then-else、loops、break、continue、return
具体体现在:
- Mutable variables 近似 memory cells
- Variables dereferences 近似 load instructions
- Variables assignments 近似 store instructions
- Control structures 近似 jumps
存在的问题:
- 摩尔定律存在瓶颈,通过多核而不是增加时钟周期来提高性能;
- 多核带来锁的问题,多线程之间会相互影响导致程序跑死;
- 吞吐量巨大也增加了水平扩展的工作量。
(2)纯函数式编程语言:
- 没有任何可变变量
- 没有循环(for、while)
- 使用递归控制函数
函数式编程语言广义定义:关注函数本身

二、基于Spark的机器学习应用
1. 机器学习算法分类:
- 线性分类器:逻辑回归、SVM
- 朴素贝叶斯:概率图模型
- 决策树:非概率模型
(1)线性分类器:
线性分类器有三种重要的函数:连接函数、判决函数、损失函数。
- 连接函数:y=f(x)中的wx是线性的,其中x为特征表示,y为标签表示,w为权值是需要求的参数。
- 判决函数:y可以被判决为-1,0,1,此时所对应的损失函数的值分别为1,1,0。
- 损失函数:通过损失函数最小,即梯度为0,来求取权值w(可采用凸优化来求取,但是因为没有闭式解,故采用迭代的方法求取参数值)。
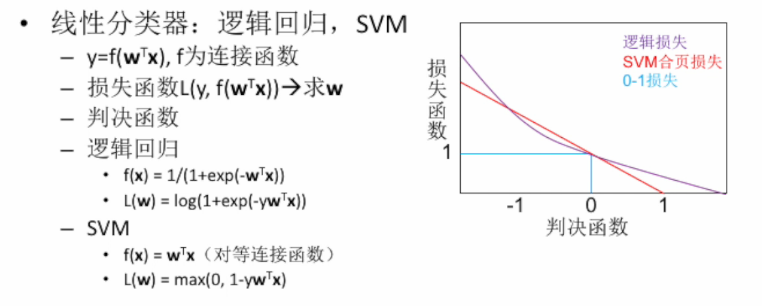
三种典型的损失函数:
- 0-1损失函数:最理想的状态,但是在0处不连续,不可微分,只能采用逼近的方式来表示;
- SVM合页损失函数:利用过(0,1)这点的直线近似表示0-1损失;
- 逻辑损失函数:利用过(0,1)这点的曲线近似表示0-1损失。
(2)概率图模型:贝叶斯网络
满足贝叶斯网络需要具有的条件:每个节点的父节点已知,它与它的非子节点是相互独立的。
朴素贝叶斯网络:

(3)决策树
- 非概率模型
- 可以处理原生的类属和数值特征,不要求数据归一化和标准化
- 非常适合集成方法,如boosting、决策森林
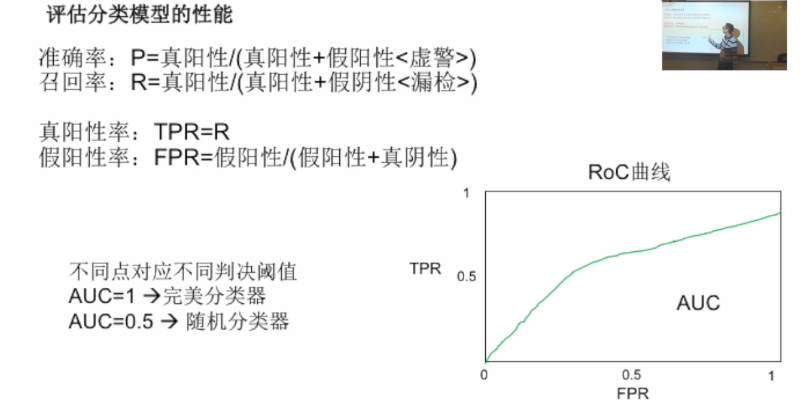
2. 评估分类模型性能的方法:
3. 分类器优化方向:

调优的两个方向:
- 性能调优:提高分类器识别率或降低分类器错误率;
- 系统调优:提高算法运行和识别效率。
性能调优的四点方向:
- 特征值:特征不符合高斯分布(特征变换近似高斯分布,如标准化、对数变换、开根号变换);
- 类别属性:类别属性在做距离时范数不同(统一类别表征的范数,如1of coding);
- 参数模型:迭代步长与次数、正则化参数调整(不同迭代回归方法解法不同,出现过拟合时参数如何调整);
- 假设检验:交叉验证(spark和scala自带,不需要重新编程)。
4. 数据降维方法:
- D维数据输入——>k维数据输入(k<<D),发现隐含结构特征,去除噪声干扰;
- 数据预处理方法,不是模型预测方法;
- 适用维度很高的数据,如图像、视频、文件、声音;
- PCA和SVD。
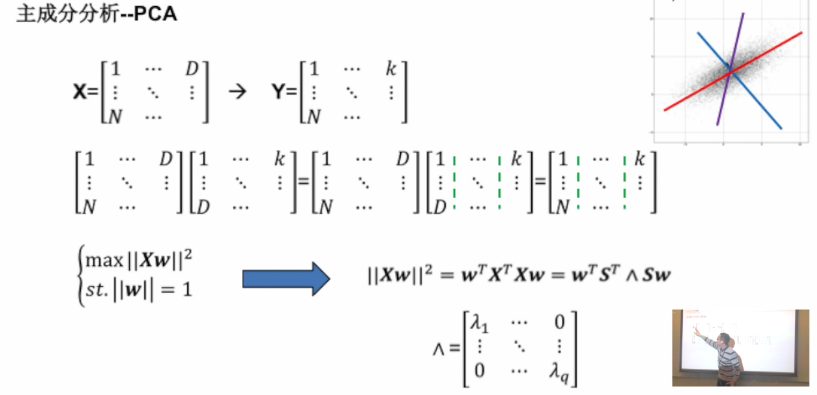
- 一个矩阵X一个列向量,相当于在这个列向量上的一个投影;
- 当这个投影范围越大,数据集的可分性越好,即二范数越大(方差越大);
- w与S方向一致,且选择对角矩阵中的特征值所对应的最大特征向量。
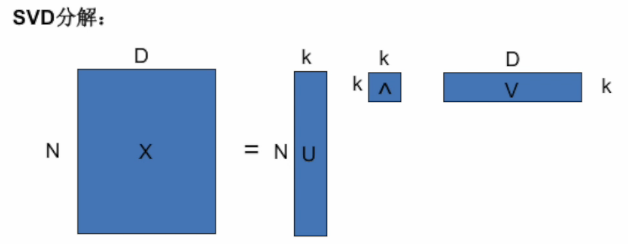
- 奇异值与特征值对应的特征向量相同;
- V矩阵的转置就是w矩阵;
- 聚类也可以做降维(聚成k类,每个点到这k类的距离,将空间映射为k维)。
机器学习的Spark与Scala开发简介的更多相关文章
- 使用scala开发spark入门总结
使用scala开发spark入门总结 一.spark简单介绍 关于spark的介绍网上有很多,可以自行百度和google,这里只做简单介绍.推荐简单介绍连接:http://blog.jobbole.c ...
- Scala语言简介和开发环境配置
Scala语言的简介和开发环境搭建 Scala是一门结合了面向对象特征和函数式编程特征的语言,它是一个创新的编程语言产品.Scala可以做脚本(就像shell脚本一样),可以做服务端编程语言,可以写数 ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- Spark集群 + Akka + Kafka + Scala 开发(2) : 开发一个Spark应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境,我们已经部署好了一个Spark的开发环境. 本文的目标是写一个Spark应用,并可以在集群中测试. ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Spark集群 + Akka + Kafka + Scala 开发(4) : 开发一个Kafka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
随机推荐
- cocos2d-x plist在拍照
if(!CCSpriteFrameCache::sharedSpriteFrameCache()->spriteFrameByName("scrollicon_bg.png" ...
- SQL 无限级分类语句
原文:SQL 无限级分类语句 原表数据为: 此处用到了with关键字,在程序中也可以用递归实现,但觉得还是没有一条sql方便 with tb (ID,Name,ParentID,Sort) as( s ...
- springbatch操作CSV文件
一.需求分析 使用Spring Batch对CSV文件进行读写操作: 读取一个含有四个字段的CSV文件(id, name, age, score), 对文件做简单的处理, 然后输出到还有一个csv文件 ...
- C#映射网络驱动器
using System.Runtime.InteropServices; [StructLayout(LayoutKind.Sequential)] public class NetResource ...
- unity资源
unity资源集中贴 1.unity经验之谈 http://jingyan.baidu.com/article/19192ad820f17be53e570715.html 2.百度网盘,分享了一点模型 ...
- UC编程:环境变量的查询与修改
每个程序中都维护一个指向环境变量的指针char **environ; 子进程会从父进程继承环境变量.子进程环境变量的修改不一定会影响父进程 无关的多个进程之间修改环境变量不会互相影响 打印环境变量 [ ...
- cocos2d-x的TestCpp分析
最近,我刚开始学coco2d-x 我会写我的学习经验来 首先TestCppproject有许多例子文件夹,而在这些文件夹以外的其他文件 .我首先研究这些文件: controller.h/cpp:管理方 ...
- Oracle 11g+FluentNHibernate AutoMapping组合尝试
一次Oracle 11g+FluentNHibernate AutoMapping组合尝试 本文的上下文环境 操作系统:Win7 x64 Ultimate开发工具:Visual Studio 2013 ...
- RESTful API Develop
yii2 RESTful API Develop 参考文档:http://www.yiiframework.com/doc-2.0/guide-rest.html 以 DB 中的 news 表为例 ...
- NPOI 2.0 Excel读取显示
NPOI 2.0 Excel读取显示 最近接到需求,需要把excel表格里的数据原样展示到web页面,主要是满足随意跨行跨列. 之前用过一点NPOI,不过接触的不太多,趁这次机会再熟悉一下.由于操 ...