Realitymining 数据集简单介绍与使用
数据集的官网 http://realitycommons.media.mit.edu/index.html(可能需要翻墙) ,下面是数据集的简要介绍(摘自官方网站)
The goal of this experiment was to explore the capabilities of the smart phones that enabled social scientists to investigate human interactions beyond the traditional survey based methodology or the traditional simulation base methodology. The subjects were 75 students or faculty in the MIT Media Laboratory, and 25 incoming students at the MIT Sloan business school adjacent to the Media Laboratory. Of the 75 Media Lab participants, 20 were incoming masters students and 5 were incoming MIT freshman, and the rest had remained in the Media Lab for at least a year.
本文的初衷是在尽可能保户用户隐私的情况下对用户进行好友推荐,而不是像许多文献那样(这里指获取用户的隐私数据,我个人觉得不可行.),这里只是在实验的情况下,因为在现实生活中,不会有人经常开着无线设备而为了得到一些无关紧要的推荐结果.本文思想是利用 bluetooth 数据,发现用户好友关系,对其简单的排序结果对用户进行好友推荐,并与随推荐结果相比较,验证其方法的可以行性.实验使用的数据集是 2004年,mit的数据,不知道有没近些年的相关数据集,有感兴趣的可以交流一下.
抽取部分自己需要的数据:
%获取需要的数据,
%转入原始数据
data = load('realitymining.mat');
%subject数据 struct 数组 1*106 struct
%结构体数组 data.s(0) - data.s(106)
%可以采用这种方式 给新 结构数组 赋值 datalite.s(0).mac = data.s(0).mac % 新建一个结构体数组,可采用 使用直接引用方式定义结构
s = struct([]);
n = 1;
while (n~=107)
%添加想要的数据
s(n).mac = data.s(n).mac;
s(n).device_list_macs = data.s(n).device_list_macs;
s(n).device_list_names = data.s(n).device_list_names;
%这三列数据的 列数应该是相等的.
s(n).device_date = data.s(n).device_date;
s(n).device_names = data.s(n).device_names;
s(n).device_macs = data.s(n).device_macs;
s(n).neighborhood = data.s(n).neighborhood;
s(n).my_office = data.s(n).my_office;
n=n+1; end network = data.network;
save 'slite' 's' 'network'
根据好友关系绘制拓扑图,结点显示 bluetooth的 mac号.
function ND_netplot(network,s)
A = network.friends;
[n,m]=size(A);
w=floor(sqrt(n));
h=floor(n/w);
x = zeros(,w*h);
y = zeros(,w*h);
index = ;
for i=:h %使产生的随机点有其范围,使显示分布的更广
for j=:w
index = index +;
x(index)=*rand()+(j-)*;
y(index) =*rand()+(i-)*; end
end ed=n-h*w;
for i=:ed
index = index +;
x(index)=*rand()+(i-)*;
y(index)=*rand()+h*;
end
plot(x,y,'ok'); title('网络拓扑图');
for i=:n
for j=:n
if A(i,j) ==
c=num2str(A(i,j)); %将A中的权值转化为字符型
text((x(i)+x(j))/,(y(i)+y(j))/,c,'Fontsize',); %显示边的权值
if i ~= j
arrow([x(j),y(j)],[x(i),y(i)]); %带箭头的连线
end
end
%hold on;
end
if i<
%这里不显示点的序号,显示 mac地址.
sub_index = network.sub_sort(i);
mac = ['--',num2str(s(sub_index).mac)];
text(x(i),y(i),[num2str(sub_index),mac],'Fontsize',,'color','r'); %显示点的序号
disp([num2str(sub_index),mac]);
end end
end
结果如图:
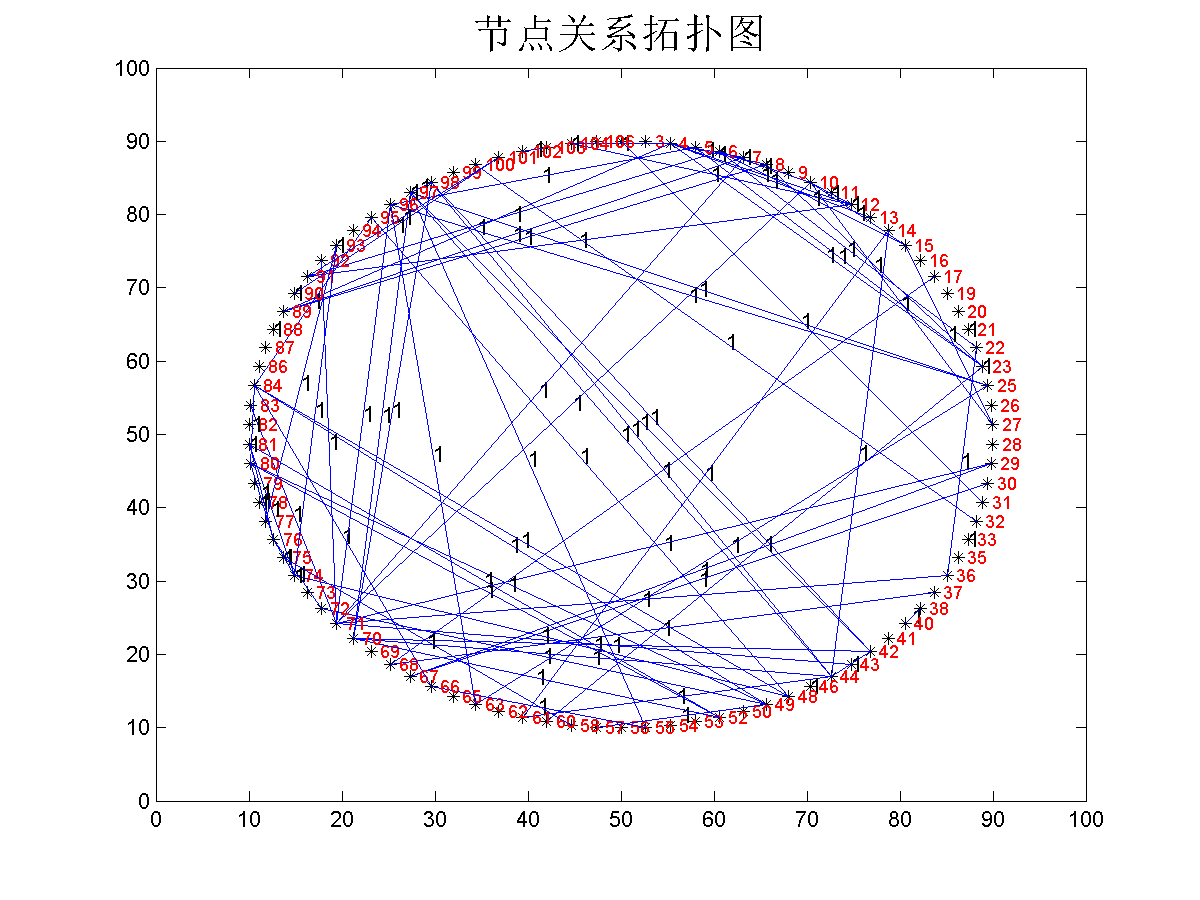
到这里并不没做什么实际性的工作,只是将需要的数据分离出现.并将好友关系,以有向图的方式绘制出来 .
用户 hash_number 与之对应的 bluetooth mac
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
--
把好友关系蓝牙的扫描到的次数用用图形表示出来,程序写的比较乱便不贴上来了:
根据扫描到的次数进行好友排序的排序算法 ,这里是根据相遇时长进行排序,基于相遇频率的算法与之类似,对于连续扫描到相同mac 认为是一次相遇,略修改即可:
function getdurationbluetoothfriends(S,Network)
disp('run scipt to get duration');
[~,wS] = size(S);
[~,wN] = size(Network.friends);
limits = wN; %
durationbluetooth = zeros(wS,wS);%这里储存的是 sub_index
for n = :limits- %ws -
%sub_sort 是得到对应的 subject 号 -
device_mac = S(Network.sub_sort(n)).device_macs;
[~,t] = size(device_mac); %cell
for m = :t
%添加一些什么方法 这里数据 是 - m
EveryScan = device_mac{m}; %每一个cell 包含多个数据,所以还需要解析.
%每个output 还有多个数据,所以也要分离出来.
[hE,~] = size(EveryScan);
for r = :hE
%在这里把每次扫描 的mac 与现有的mac 做比较 ,并加入到频率直方图中.
%这里mac 获取应该没问题了.
mac = EveryScan(r,);
sub_index = submacindex(mac,Network.sub_sort(n));
if sub_index >
%某个 subject 与某个 subject '相遇一次' 并计算次数
durationbluetooth(Network.sub_sort(n),sub_index) = durationbluetooth(Network.sub_sort(n),sub_index)+;
end
end
end
disp(Network.sub_sort(n));
end
%对 frequencybluetooth 排序
% 行 为 project 号 列为对应好友 .
% 对 frequencybluetooth 数据进行排序
sortduration = zeros(wS,wS);%这里储存的是 sub_index
for i = :wS
[~,index] = sort(durationbluetooth(i,:),'descend');
sortduration(i,:) = index;
end
save 'sortduration' 'sortduration';
save 'durationbluetooth' 'durationbluetooth';
%用于获取根据传递 过来的 mac 的 subject 索引号
% sub_index 为当前 mac 对应索引.
function index = submacindex(mac,currentIndex)
for index = :wS
if isempty(S(index).mac) %-
continue;
end
if index~=currentIndex && mac==S(index).mac
return;
end
end
index = -; %表示数据不存在,非本实验已有的数据.
end
end
为了确保数据的有效,我简单写了个数据验证的 程序 :
function checkdata(s)
a = ;
num = ;
data = s().device_macs;
for n = :
everyScan = data{n}; %每一个cell 包含多个数据,所以还需要解析.
[h1,w1] = size(everyScan);
for r = :h1
mac = everyScan(r,);
if mac == a
index = char(num2str(n),'.',num2str(r),':');
disp(index);
num = num+;
disp(num2str(num));
end
end
end
end
看看这里统计的数据是否与上面排序时的频率是否相同,只需要取一个数据验证即可.
下面验证一下随机推荐的推荐效果.
根据上面好友排序算法生成的 sortduration 数据 和 原network数据 ,随机推荐算法:
%根据之前的生成的矩阵,与随机推荐做比较,并绘图
%这里先实现随机推荐,观察推荐好友数与 命中 个数的关系,正常情况下应该近似线性关系.
function recommendfriends(Sortfreq,Network)
[~,wN] = size(Network.friends);
[~,wS] = size(Sortfreq);
relations = zeros(,wS); %推荐好友的 个数从 -
for m = :wS %随机选择 m个好友,计算其命中个数
randomHit = ; r=randperm(wS);%生成1到106的随机排列
selectedMatrix = r(:m); %选择推荐 m 个好友 ,这里是随机推荐 是一维矩阵.
%n 为对应subject 索引,非真正索引.
for n = :wN- %- 对应 -
% -
subjectIndex = Network.sub_sort(n); %subjectIndex为真实索引.
randomHit =randomHit + hits(n,selectedMatrix);
end
% 储存 randomHit 与 对应 m 值 .
relations(m) = randomHit;
end
save 'relations' 'relations';
%绘图 %数据做平滑处理.
smoothData = smooth(relations,);
%plot(:wS,smoothData(:wS));
plot(:wS,smoothData(:wS),'r*');
%传入参数 ,
function value = hits(n,selectedMatrix)
value = ;
for i = :wN- %-
if Network.friends(n,i) >=
realInex = Network.sub_sort(i); %-
if any(selectedMatrix == realInex) %矩阵中包含.realInex
value = value+;
end
end
end
end %子函数
%最外部函数
end
因为数据的稀疏性,我简单做了smooth处理,感觉好很多.其结果如图:
简单说明一下,为了验证推荐算法的有效性,我这里只做与随机推荐的对比.这里用命中数进行衡量,由于真实数据中,好友关系比较稀疏,统计的好友共有125个数据,
对于每个人,其推荐的好友越多其越是能够命中其原有的真实好友,所以在不采用任何算法的基础之上,其推荐好友人数与命中人数成线性关系 .
推荐比较图:
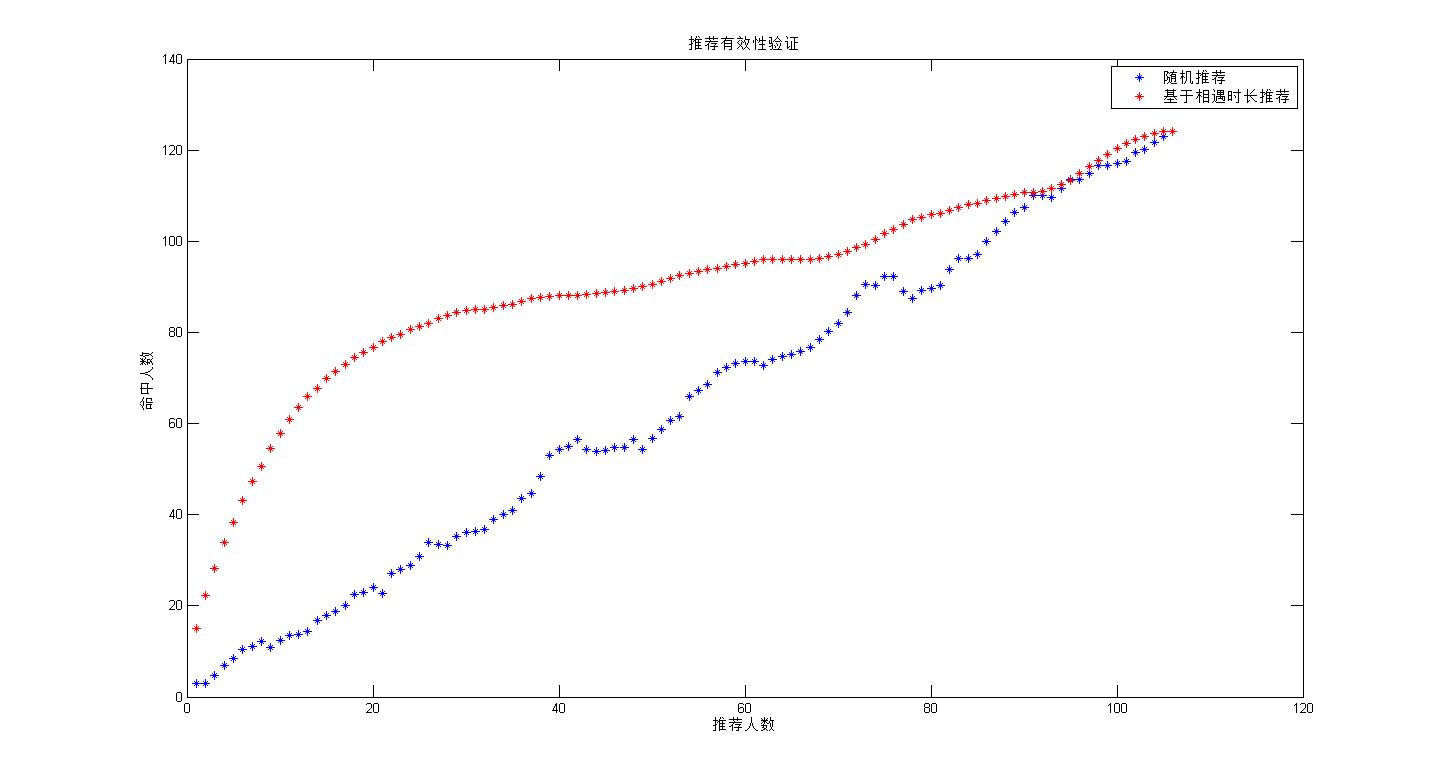
进行基于相遇时长和 相遇频率的实验,结果如图,看来基本没有什么差异,

实验总算完成了,和当初预想的一样,基于时长的推荐在开始处会一相对好的推荐结果,当推荐的人数增加,其逐渐等同于随机推荐.
为了做实验,生成了好多子数据,有需要的可以邮箱.本文程序供大家参考,请误抄袭.
Realitymining 数据集简单介绍与使用的更多相关文章
- 决策树简单介绍(二) Accord.Net中决策树的实现和使用
决策树介绍 决策树是一类机器学习算法,可以实现对数据集的分类.预测等.具体请阅读我另一篇博客(http://www.cnblogs.com/twocold/p/5424517.html). Accor ...
- OpenCV 编程简单介绍(矩阵/图像/视频的基本读写操作)
PS. 因为csdn博客文章长度有限制,本文有部分内容被截掉了.在OpenCV中文站点的wiki上有可读性更好.而且是完整的版本号,欢迎浏览. OpenCV Wiki :<OpenCV 编程简单 ...
- Cloudera impala简单介绍及安装具体解释
一.Impala简单介绍 Cloudera Impala对你存储在Apache Hadoop在HDFS,HBase的数据提供直接查询互动的SQL.除了像Hive使用同样的统一存储平台,Impala也使 ...
- Hadoop简单介绍
Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. 随后在2003 ...
- python之pandas简单介绍及使用(一)
python之pandas简单介绍及使用(一) 一. Pandas简介1.Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据 ...
- 简单介绍aspose-words-18.10-jdk16做导出word
今天在搞那个用aspose words for java做导出word的功能,顺便简单介绍这个怎么用,我有两个版本的破解版,就都做简单介绍怎么用 警告:请勿用于商业用途,仅供学习研究使用,如有任何版权 ...
- Redis简单介绍
redis简单介绍 Redis VS key-value缓存产品 Redis支持数据的持久化,能够将内存中的数据保持在磁盘中,重新启动的时候能够再次载入进行使用. Redis不只支持简单的key-va ...
- Redis实战——简单介绍
出自:https://www.cnblogs.com/moonlightL/p/7364107.html Redis简单介绍 Redis是一个开源,高级的键值存储和一个适用的解决方案,用于构建高性能, ...
- Redis主从复制简单介绍
由于本地环境的使用,所以搭建一个本地的Redis集群,本篇讲解Redis主从复制集群的搭建,使用的平台是Windows,搭建的思路和Linux上基本一致! (精读阅读本篇可能花费您15分钟,略读需5分 ...
随机推荐
- IIS7配置Gzip压缩 JS压强失败的原因
开启配置HTTP压缩(GZip) 在IIS7中配置Gzip压缩相比IIS6来说实在容易了许多,而且默认情况下就是启用GZip压缩的.如果没有,则可以再功能视图下找到“压缩”项,进入之后就会看到“静态内 ...
- phonegap android 开发环境搭建
1.下载JDK并安装 http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html 配置环境变量 ...
- 从零开始学习Node.js例子八 使用SQLite3和MongoDB
setup.js:初始化数据库 var util = require('util'); var async = require('async'); //npm install async var no ...
- SQL函数创建错误
[Err] 1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration a ...
- IplImage结构体
一.IplImage的一些重要成员: 1.origin:图像原点的定义.=0,则图片的左上角是原点:=1,则左下角是原点. IplIm ...
- Spring 的 NamedParameterJdbcTemplate(转)
NamedParameterJdbcTemplate类是基于JdbcTemplate类,并对它进行了封装从而支持命名参数特性. NamedParameterJdbcTemplate主要提供以下三类方法 ...
- 新建STM32工程
1) 2)保存 3)选择公司和芯片的型号,STM32F103C8T6,64kB Flash, 20kB SRAM. 4)手动添加启动代码 5)新建如下文件夹 6)回到工程,选中target,右键Add ...
- 转:android异步任务设计思详解(AsyncTask)
这里说有设计思想是我根据查看Android源代码提炼出来的代码逻辑,所以不会跟Google工程师的原始设计思想100%符合(也有可能是0%),但是本文一定可以帮助你理解AsyncTask,也可能有一些 ...
- Linux下高cpu解决方案(转载)
昨天搞定了一个十万火急的issue,客户抱怨产品升级后系统会变慢和CPU使用率相当高,客户脾气很大,声称不尽快解决这个问题就退货,弄得我们 R&D压力很大,解决这个issue的任务分给了我,客 ...
- BOM和DOM
Day 01 正课: 1.什么是DOM: 2.DOM Tree 3.遍历DOM树: 1.什么是DOM: 原生js=ECMAScript(核心语法)+ DOM(专门操作网页内容的API)+ 3天 BOM ...