解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
http://improve.dk/orcamdf-now-supports-databases-with-multiple-data-files/
OrcaMDF 其中一个最新特性是支持多数据文件的数据库。这在解析上面需要作出相关的小改变,实际上大部分都是bug 修复代码
由于之前只支持单个数据文件而引起的。然而这确实需要一些重大的重构而离开MdfFile 的主入口点,现在使用数据库封装类,封装一个数据文件变量
分配比例填充
OrcaMDF 支持标准的数据库表的比例填充架构,这个数据库表除了有mdf文件之外还有ndf文件,而这些文件都在主文件组里,例如,你可能会创建以下数据文件或者架构
CREATE DATABASE
[SampleDatabase]
ON PRIMARY
(
NAME = N'SampleDatabase_Data1',
FILENAME = N'C:SampleDatabase_Data1.mdf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data2',
FILENAME = N'C:SampleDatabase_Data2.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data3',
FILENAME = N'C:SampleDatabase_Data3.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'SampleDatabase_log',
FILENAME = N'C:SampleDatabase_log.ldf',
SIZE = 3072KB,
FILEGROWTH = 10%
)
GO USE SampleDatabase
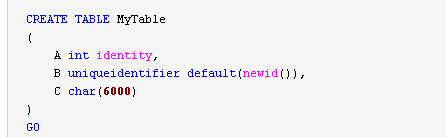
GO CREATE TABLE MyTable
(
A int identity,
B uniqueidentifier default(newid()),
C char(6000)
)
GO INSERT INTO MyTable DEFAULT VALUES
GO 100
这会引起MyTable 按比例填充三个数据文件(C列的作用为了让SQLSERVER分配100个页面来装载数据,好让填满三个数据文件)
为了解析这种情况,我们需要做下面的工作
var files = new[]
{
@"C:SampleDatabase_Data1.mdf",
@"C:SampleDatabase_Data2.ndf",
@"C:SampleDatabase_Data3.ndf"
}; using (var db = new Database(files))
{
var scanner = new DataScanner(db);
var result = scanner.ScanTable("MyTable"); EntityPrinter.Print(result);
}
运行之后的结果是
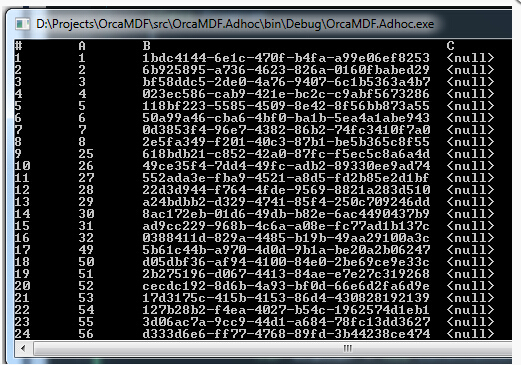
大家注意看:
A(4个字节)+B(16个字节)+C(6000个字节)=6020字节
刚好一条记录一页,下面说到,SQLSERVER分配完了一个区之后,一个区8个页面,当一个区分配完毕之后,SQLSERVER
会转到SampleDatabase_Data2.ndf数据文件继续分配页面,分配的值是9~16,一个区分配完毕之后又到
SampleDatabase_Data3.ndf数据文件继续分配页面,分配的值是17~24
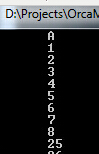
自增值会一直到100,注意到A列有间隔,这是由于一个事实我们在每个数据文件的一个区里面以循环赛的方式来分配。
ID1~8在第一个数据文件,9~16在第二个数据文件最后17~24在第三个数据文件。由于这一点,页面25~32分配在第一个数据文件,一直这样下去
由于是堆表,我们使用文件分配顺序扫描,这导致我们获得结果1~8,25~32,49~56,73~80,97~100 全部都是从第一个文件开始,然后9~16,33~40
从第二个数据文件里读取然后到最后一个数据文件的剩余页面。想一下这是不是很怪,好吧,SQLSERVER里面也是完全一样的

不理解的童鞋可以看一下这篇文章《SQLSERVER中的ALLOCATION SCAN和RANGE SCAN》或者
《Microsoft SQL Server 2008技术内幕:T-SQL查询 笔记》里面有相关介绍
文件组支持
OrcaMDF 也支持使用文件组,包括按比例分配填充在一个单独的 文件组里,举个例子,你可能创建下面的数据库和架构
CREATE DATABASE
[SampleDatabase]
ON PRIMARY
(
NAME = N'SampleDatabase_Data1',
FILENAME = N'C:SampleDatabase_Data1.mdf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'SampleDatabase_log',
FILENAME = N'C:SampleDatabase_log.ldf',
SIZE = 3072KB,
FILEGROWTH = 10%
)
GO ALTER DATABASE
[SampleDatabase]
ADD FILEGROUP
[SecondFilegroup]
GO ALTER DATABASE
[SampleDatabase]
ADD FILE
(
NAME = N'SampleDatabase_Data2',
FILENAME = N'C:SampleDatabase_Data2.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data3',
FILENAME = N'C:SampleDatabase_Data3.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
TO FILEGROUP
[SecondFilegroup]
GO USE SampleDatabase
GO CREATE TABLE MyTable
(
A float default(rand()),
B datetime default(getdate()),
C uniqueidentifier default(newid()),
D char(5000)
) ON [SecondFilegroup]
GO INSERT INTO MyTable DEFAULT VALUES
GO 100
这将会引起MyTable去按比例填充分配在第二和第三个数据文件之间(D列用来占位置,确保让SQLSERVER分配100个页面来装载数据,好让对文件组里的两个数据文件进行
分配填充)数据只会分别对第二和第三数据文件进行填充而主数据文件不受影响
跟先前的例子的解释一样,结果如下
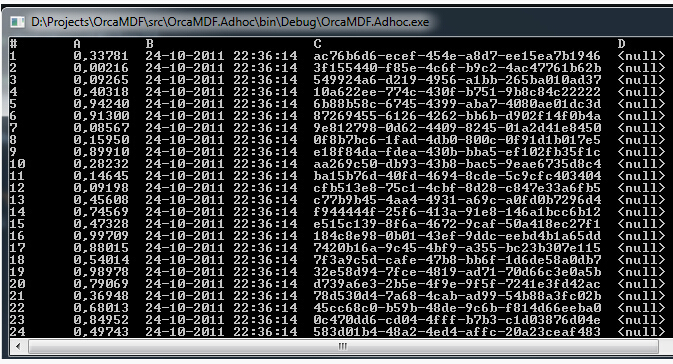
将会一直到100
第八篇完
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)的更多相关文章
- 解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译)
解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译) http://improve.dk/reading-bits-in-orcamdf/ Bits类型的存储跟SQLSERVE ...
- 解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译)
解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译) http://improve.dk/orcamdf-feature-recap/ 时间过得真快,这已经过了大概四个月了自从我最初介绍我 ...
- 解剖SQLSERVER 第十篇 OrcaMDF Studio 发布+ 特性重温(译)
解剖SQLSERVER 第十篇 OrcaMDF Studio 发布+ 特性重温(译) http://improve.dk/orcamdf-studio-release-feature-recap/ ...
- 解剖SQLSERVER 第四篇 OrcaMDF里对dates类型数据的解析(译)
解剖SQLSERVER 第四篇 OrcaMDF里对dates类型数据的解析(译) http://improve.dk/parsing-dates-in-orcamdf/ 在SQLSERVER里面有几 ...
- 解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions(译)
解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions (译) http://improve.dk/avoiding-regressions-in-orcamdf-b ...
- 解剖SQLSERVER 第十七篇 使用 OrcaMDF Corruptor 故意损坏数据库(译)
解剖SQLSERVER 第十七篇 使用 OrcaMDF Corruptor 故意损坏数据库(译) http://improve.dk/corrupting-databases-purpose-usin ...
- 解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译) http://improve.dk/the-anatomy-of-row-amp-page-compre ...
- 解剖SQLSERVER 第十一篇 对SQLSERVER的多个版本进行自动化测试(译)
解剖SQLSERVER 第十一篇 对SQLSERVER的多个版本进行自动化测试(译) http://improve.dk/automated-testing-of-orcamdf-against ...
- 解剖SQLSERVER 第三篇 数据类型的实现(译)
解剖SQLSERVER 第三篇 数据类型的实现(译) http://improve.dk/implementing-data-types-in-orcamdf/ 实现对SQLSERVER数据类型的解 ...
随机推荐
- 【CodeVS1076】排序
Description 给出n和n个整数,希望你从小到大给他们排序 Input 第一行一个正整数n 第二行n个用空格隔开的整数 Output 输出仅一行,从小到大输出n个用空格隔开的整数 Sample ...
- RVM 多版本Ruby管理-Gentoo
发现了一个非常Amzaing的Ruby的工具RVM,用于安装和管理Ruby的多个版本.相比较于直接在系统中安装不同版本的Ruby,然后使用时切换到对应的版本,这种方式实在是酷毙了,使ruby安装变得非 ...
- C/C++中extern关键字解析
1 基本解释:extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义.此外extern也可用来进行链接指定. 也就是说extern ...
- cookie,session原理,以及如何使用chrome查看。
首先,先补充下chrome浏览器的使用. 1.1.php源码: <?php $cookieDomain = '.elf.com'; setcookie(, '/', $cookieDomain) ...
- iOS判断数组不为空
用([array count]==0 )来判断是否为空,都是坑,如果array为空的话,执行count就会直接报错,程序崩溃退出. 正确判断NSArray是否为空的方法: if(array != ni ...
- touchstart,touchmove判断手机中滑屏方向
滑动屏幕 touchstart:接触屏幕时触发,touchmove:活动过程触发,touchend:离开屏幕时触发 首先获取手接触屏幕时的坐标X,Y //获取接触屏幕时的X和Y$('body') ...
- c#datagirdview ,用DataSource 方式赋值,然后更新出问题问题
先说一下程序 主窗体 ,两个子窗体A,B.嵌入主窗体的Panel里边 主窗体,启动类C里边的查找方法,查到的值,通过事件委托送到窗体A C类里同时修改查询表,把修改的查询表通过事件委托发送给窗体B, ...
- Android安全开发之UXSS漏洞分析
0X01 前言 XSS是我们比较熟悉的一种攻击方式,包括存储型XSS.反射型XSS.DOM XSS等,但UXSS(通用型XSS)另外一种不同的漏洞类型,主要体现在漏洞的载体和影响范围上. XSS问题源 ...
- 关于springmvc的配置文件
开发常用的springmvc.xml配置文件,spring 3.0 spring-servlet.xml配置. <?xml version="1.0" encoding=&q ...
- c# udp局域网通信
udp224.0.0.1 子网上的所有系统224.0.0.2 子网上的所有路由器224.0.0.12 dhcp服务器224.0.1.1 ntp224.0.1.24 wins服务器 http://www ...