SPSS-相关分析
相关分析(二元定距变量的相关分析、二元定序变量的相关分析、偏相关分析和距离相关分析)
定义:衡量事物之间,或称变量之间线性关系相关程度的强弱并用适当的统计指标表示出来,这个过程就是相关分析
变量之间的关系归纳起来可以分为两种类型,即函数关系和统计关系。
相关分析的方法较多,比较直接和常用的一 种是绘制散点图。图形虽然能够直观展现变量之间的相关关系,但不很精确。为了能够更加准确地描述变量之间的线性相关程度,可以通过计算相关系数来进行相关分析
总体相关系数,记为 ρ;样本相关系数,记为 r。统计学中,一般用样本相关系数 r 来推断总体相关系数
相关系数的取值范围在1和+1之间,即1≤r≤+1
若0<r≤1,表明变量之间存在正相关关系,即两个变量的相随变动方向相同;
若-1≤r<0,表明变量之间存在负相关关系,即两个变量的相随变动方向相反;
当|r| =1时,其中一个变量的取值完全取决于另一个变量,两者即为函数关系;若 r= +1,表明变量之间完全正相关;若 r= -1,表明变量之间完全负相关。
当r= 0时,说明变量之间不存在线性相关关系,但这并不排除变量之间存在其他非线性关系的可能。
根据经验可将相关程度分为以下几种情况:
若r≥0.8 时,视为高度相关
若0.5≤r<0.8 时,视为中度相关
当0.3≤r<0.5 时,视为低度相关
当 r<0.3 时,说明变量之间的相关程度极弱,可视为不相关
二元变量的相关分析是指通过计算变量间两两相关的相关系数,对两个或两个以上变量之间两两相关的程度进行分析。
1.二元定距变量的相关分析
定义:通过计算定距变量间两两相关的相关系数,对两个或两个以上定距变量之间两两相关的程度进行分析。
定距变量:又称为间隔(interval)变量,它的取值之间可以比较大小,可以用加减法计算出差异的大小。
Pearson简单相关系数用来衡量定距变量间的线性关系
对Pearson简单相关系数的统计检验是计算t统计量
SPSS操作
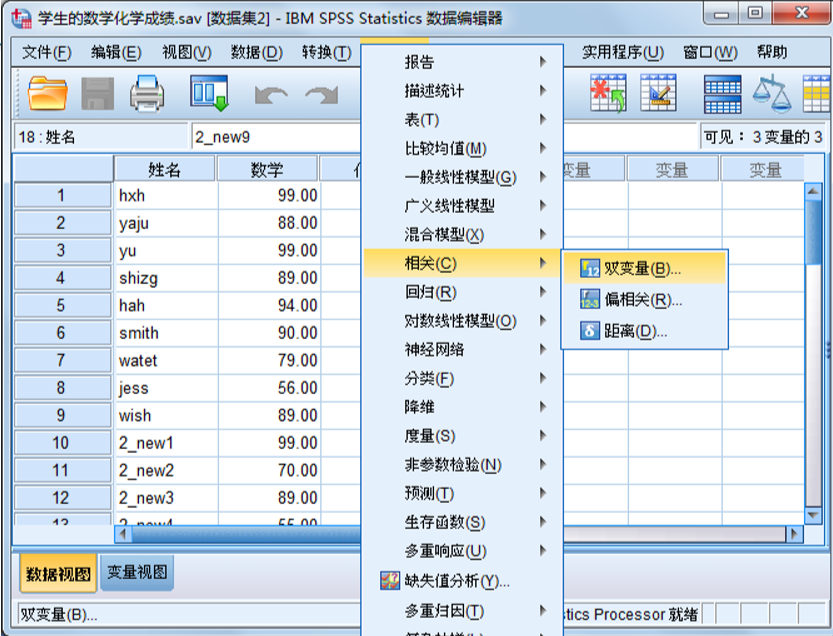
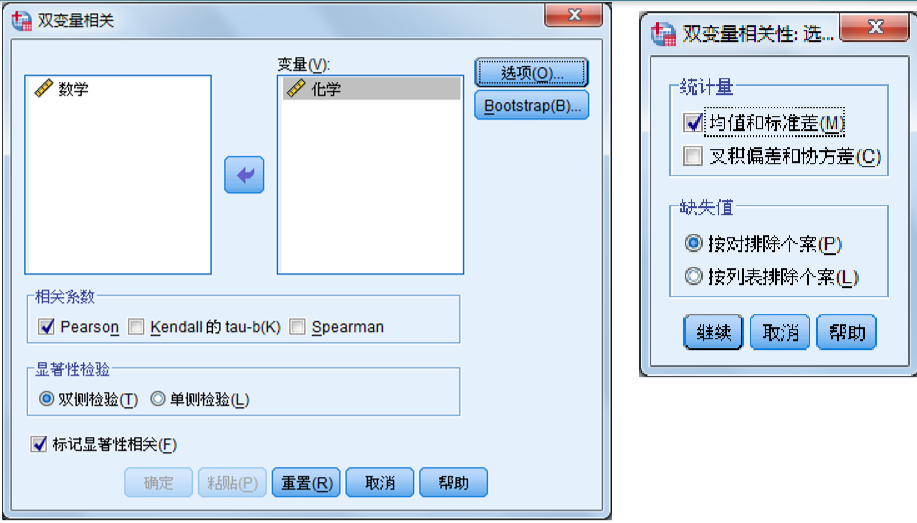
2.二元定序变量的相关分析
定序变量:又称为有序(ordinal)变量、顺序变量,它取值的大小能够表示观测对象的某种顺序关系(等级、方位或大小等)
Spearman和Kendall's tua-b等级相关系数用以衡量定序变量间的线性相关关系,它们利用的是非参数检验的方法。
对Spearman和Kendall's tua-b等级相关系数的统计检验是计算Z统计量
SPSS操作
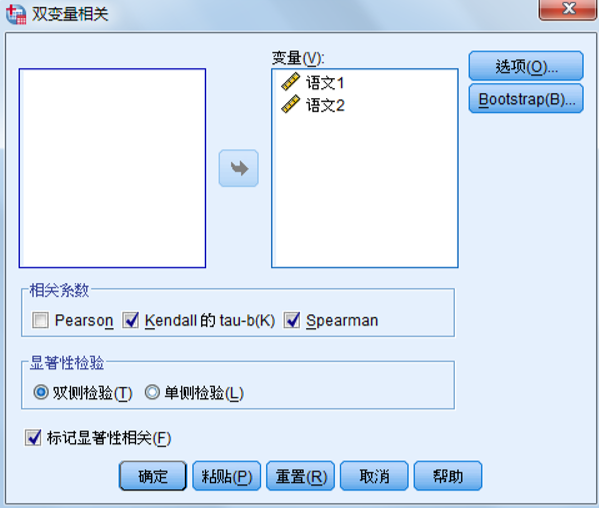
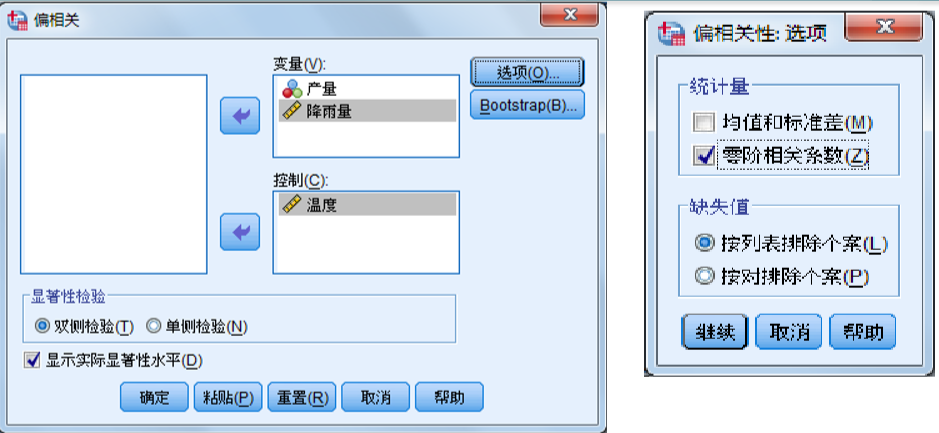
3.偏相关分析
定义:当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程。
偏相关分析的工具是计算偏相关系数,统计检验为t检验
SPSS操作
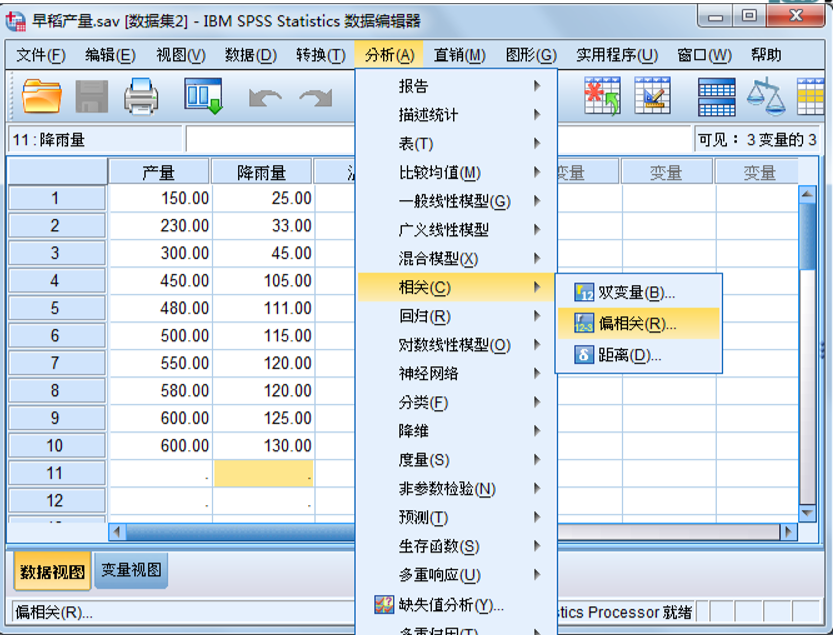
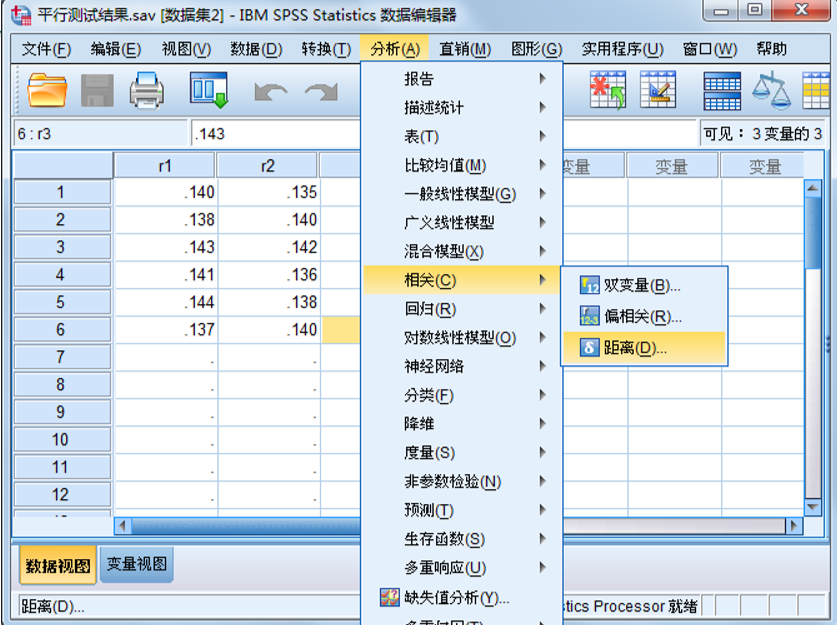
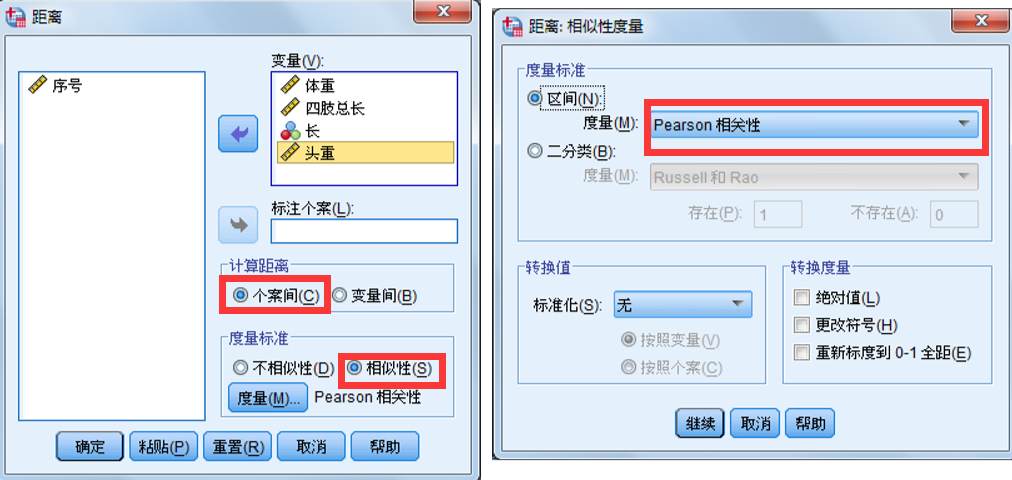
4.距离相关分析
定义:对观测量之间或变量之间相似或不相似的程度的一种测量。 距离相关分析可用于同一变量内部各个取值间,以考察其相互接近程度;也可用于变量间,以考察预测值对实际值的拟合优度。
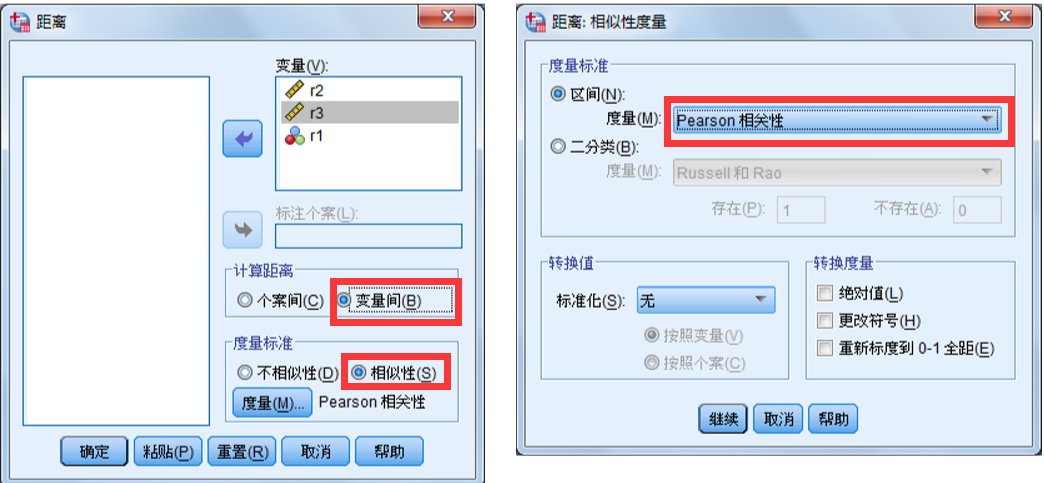
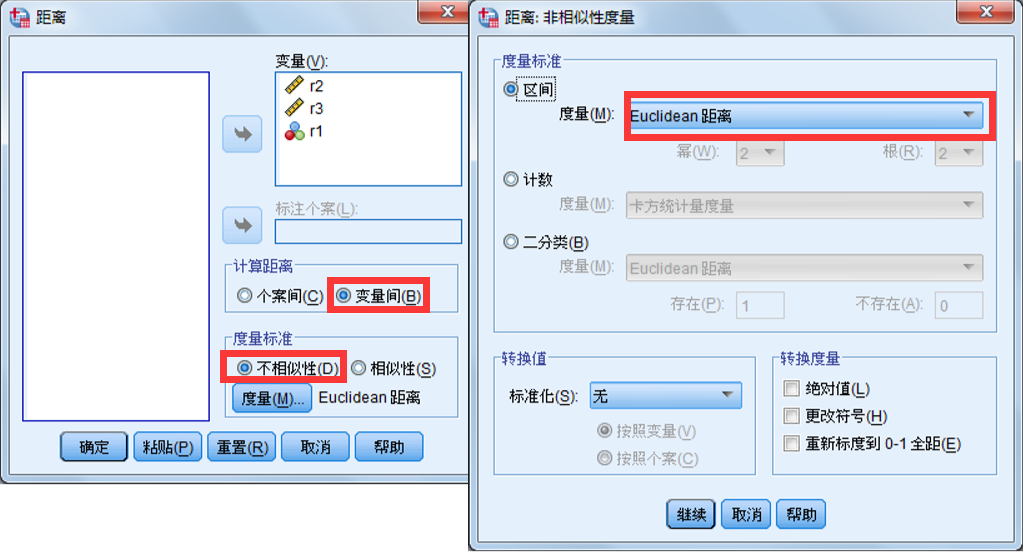
分类:距离相关分析分为相似性测量和不相似性测量,也可分为样本间分析和变量间分析。
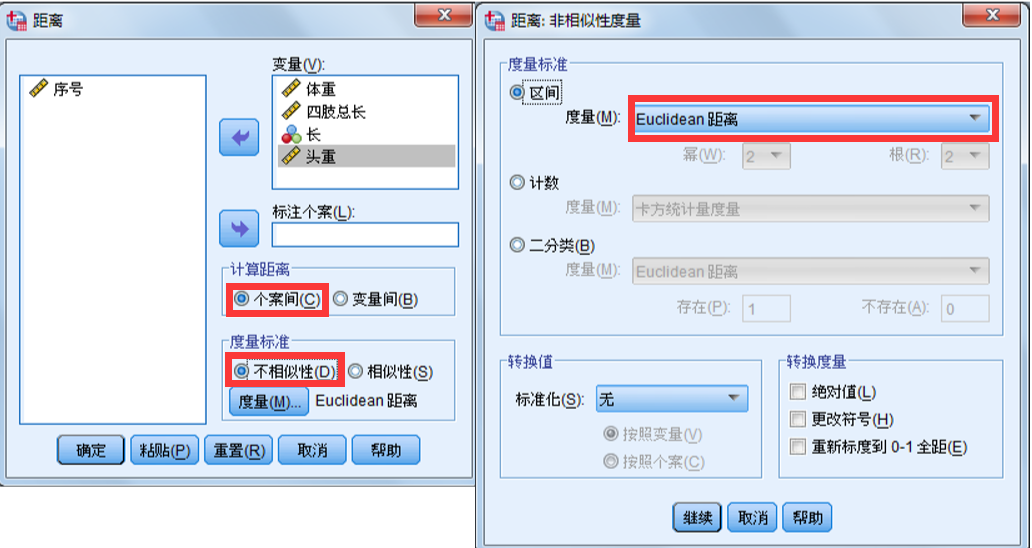
在不相似性测量的距离分析中:
对连续变量的样本 (x,y) 进行距离相关分析时,常用的统计量有:欧氏距离、 欧氏距离平方、 Chebychev距离 、 Block距离 、 Minkowski距离 、Customized 距离(用户自定义距离)
对顺序或名义变量的样本 (x,y) 进行距离相关分析时,常用的统计量有:Chi-square measure (χ2统计量) 、 Phi-square measure (φ2 统计量)
对于二值变量,可以使用欧氏距离、欧氏距离平方、方差等方法进行计算
SPSS操作
SPSS-相关分析的更多相关文章
- SPSS数据分析—典型相关分析
我们已经知道,两个随机变量间的相关关系可以用简单相关系数表示,一个随机变量和多个随机变量的相关关系可以用复相关系数表示,而如果需要研究多个随机变量和多个随机变量间的相关关系,则需要使用典型相关分析. ...
- SPSS数据分析—相关分析
相关系数是衡量变量之间相关程度的度量,也是很多分析的中的当中环节,SPSS做相关分析比较简单,主要是区别如何使用这些相关系数,如果不想定量的分析相关性的话,直接观察散点图也可以. 相关系数有一些需要注 ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- SPSS数据分析—基于最优尺度变换的典型相关分析
传统的典型相关分析只能考虑变量之间的线性相关情况,且必须为连续变量,而我们依然可以使用最优尺度变换来拓展其应用范围,使其可以分析非线性相关.数据为分类数据等情况,并且不再仅限于两个变量间的分析, 虽然 ...
- SPSS数据分析—信度分析
测量最常用的是使用问卷调查.信度分析主要就是分析问卷测量结果的稳定性,如果多次重复测量的结果都很接近,就可以认为测量的信度是高的.与信度相对应的概念是效度,效度是指测量值和真实值的接近程度.二者的区别 ...
- SPSS数据分析—卡方检验
t检验和方差分析主要针对于连续变量,秩和检验主要针对有序分类变量,而卡方检验主要针对无序分类变量(也可以用于连续变量,但需要做离散化处理),用途同样非常广泛,基于卡方统计量也衍生出来很多统计方法. 卡 ...
- spss
编辑 SPSS(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件.最初软件全称为“社会科学统计软件包” (SolutionsStat ...
- SPSS简单使用
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量.数据录入.统计分析 ...
- 快速掌握SPSS数据分析
SPSS难吗?无非就是数据类型的区别后,就能理解应该用什么样的分析方法,对应着分析方法无非是找一些参考资料进行即可.甚至在线网页SPSS软件直接可以将数据分析结果指标人工智能地分析出来,这有多难呢 ...
- SPSS Modeler数据挖掘:回归分析
SPSS Modeler数据挖掘:回归分析 1 模型定义 回归分析法是最基本的数据分析方法,回归预测就是利用回归分析方法,根据一个或一组自变量的变动情况预测与其相关的某随机变量的未来值. 回归分析是研 ...
随机推荐
- Java第一次上机实验源代码
小学生计算题: package 第一次上机实验_; import java.util.*; public class 小学计算题 { public static void main(String[] ...
- HDU1848 Fibonacci again and again 博弈 SG函数
题意:三堆石子,每次能拿走斐波那契数个石子,先取完石子胜,问先手胜还是后手胜 石子个数<=1000 多组数据 题目链接:http://acm.hdu.edu.cn/showproblem.ph ...
- django---单表操作之展示书籍列表
下面使用python console对数据库进行增删改查 下面我们来举个例子在页面上展示记录 结果: 注意html里面变量的写法 {% for book in book_list %} <tr& ...
- IDEA搭建Spring框架环境
一.spring 框架概念 spring 是众多开源 java 项目中的一员,基于分层的 javaEE 应用一站式轻量 级开源框架,主要核心是 Ioc(控制反转/依赖注入) 与 Aop(面向切面) ...
- [Lua]table(一):打印与复制
一.打印table function PrintTable(tb) if type(tb) ~= "table" then print(tb) return end local c ...
- ASP.NET WebApi 图片上传
以下是代码的实现过程: Html页面表单布局: <form id="UpPicture" enctype="multipart/form-data" ac ...
- docker私有仓库pull/push
相关条件: 登录 配置秘钥
- TP5中文件的写入路径有的会被自动重定向到首页
TP5中文件的写入路径有的会被自动重定向到public public function export() { $model=model('FanweUser'); $list=$model->w ...
- 《算法》第一章部分程序 part 1
▶ 书中第一章部分程序,加上自己补充的代码,包括若干种二分搜索,寻找图上连通分量数的两种算法 ● 代码,二分搜索 package package01; import java.util.Arrays; ...
- 4. mysql 查看数据库中所有表的记录数
use information_schema; select table_name,table_rows from tables where TABLE_SCHEMA = 'testdb' orde ...