无监督学习——K-均值聚类算法对未标注数据分组
无监督学习
和监督学习不同的是,在无监督学习中数据并没有标签(分类)。无监督学习需要通过算法找到这些数据内在的规律,将他们分类。(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个无监督学习过程。)
无监督学习没有训练过程。
聚类算法
该算法将相似的对象轨道同一个簇中,有点像全自动分类。簇内的对象越相似它的分类效果越好。
未接触这个概念可能觉得很高大上,稍微看了一会其实算法的思路和KNN一样很简单。
原始数据集如下(数据有两个特征,分别用横纵坐标表示),原始数据集并没有任何标签和分类信息:

由图中的数据可以大概判断,该数据集可以分为三类数据(定义为0,1,2),那么每个点到底属于哪个分类呢,这里通过K-均值聚类算法得到三个质心点,并根据每个点到三个质心的距离进行分类(到0,1,2三个质心距离最近,则将该数据分为该类),计算出的三个质心点如下图(图中红叉点表示):
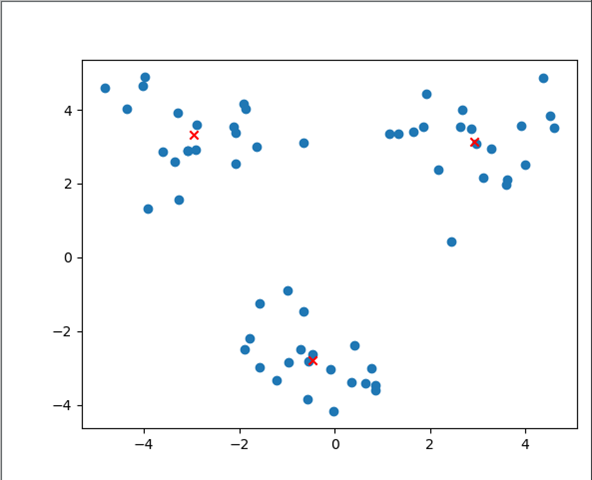
K-均值聚类算法
该算法的流程如下:
1. 加载数据集
2. 数据初始化
2.1 创建随机质心点
2.2 穿件保存结果的各个矩阵/数组
3. 多次迭代 (判断所有点的分类是否发生变化)
3.1 计算所有点的分类
3.2 根据3.1分类结果,重新计算质心点(用属于当前类的数据取平均作为新的质心点)
4. 返回数据
该算法缺点:
算法容易收敛到局部最小值,而非全局最小值。(局部最小值指结果还可以,但是并非最好结果,全局最小值时可能的最好结果)
二分K-均值聚类算法
SSE: 度量聚类效果的指标(Sum of Squared Erro,误差平方和)
SSE越小说明所有数据点越接近他们的质心,聚类效果也就越好。
该算法的流程如下:
1. 将所有点看成一个簇
2. 当簇数目小于K时
2.1 对每个簇
2.1.1 计算总误差
2.1.2 在给定簇上面进行K-均值聚类(K=2)
2.1.2 计算在该簇上一分为二之后的总误差
2.2 选择是的误差最小的那个簇进行划分
Python实现
数据加载
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat
数据的形式如下,和监督学习数据形式最大的区别是这里的数据是不带有标签的数据。每个数据是一个二维的向量。
3.275154 2.957587
-3.344465 2.603513
0.355083 -3.376585
1.852435 3.547351
-2.078973 2.552013
-0.993756 -0.884433
2.682252 4.007573
-3.087776 2.878713
-1.565978 -1.256985
2.441611 0.444826
-0.659487 3.111284
-0.459601 -2.618005
2.177680 2.387793
-2.920969 2.917485
-0.028814 -4.168078
3.625746 2.119041
-3.912363 1.325108
-0.551694 -2.814223
2.855808 3.483301
..................
向量欧式距离计算函数
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
随机产生n个质心
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
K-均值聚类算法
缺点: 该算法必须要业务提前输入分类的个数K。
该函数返回值为质心坐标centroids,以及每个点最近的质心(即该点的分类结果)和它的距离clusterAssment。
这里需要注意迭代的终止条件: clusterChanged,该标记位用来标记此次迭代是否有数据的分类和上一次得带不同,如果当前这次迭代的对所有数据的分类和上一次分类结果完全相同,则不再继续迭代。
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
#计算数据个数
m = shape(dataSet)[0]
# 存放每个数据到哪个质心距离最近,以及它的距离值
clusterAssment = mat(zeros((m,2)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)#产生随机的质心点(通过迭代,逐步变得精确)
clusterChanged = True #分类是否改变,迭代结束的条件
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k):#recalculate centroids
#ptsInClust表示到该质心距离最近的点集合
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
#将质心坐标 用最近点坐标的均值代替,所以称为均值聚类算法
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
二分K-均值算法
该算法的输入和输出和K-均值算都相同,只是它的内部实现更复杂。
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] #create a list with one centroid
for j in range(m):#calc initial Error
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#get the data points currently in cluster i
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])#compare the SSE to the currrent minimum
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment
其它机器学习算法:
监督学习——随机梯度下降算法(sgd)和批梯度下降算法(bgd)
参考:
《机器学习实战》
无监督学习——K-均值聚类算法对未标注数据分组的更多相关文章
- 机器学习——利用K-均值聚类算法对未标注数据分组
聚类是一种无监督的学习,它将相似的对象归到同一簇中.它有点像全自动分类.聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好. K-均值(K-means)聚类算法,之所以称之为K-均值是因 ...
- 机器学习:利用K-均值聚类算法对未标注数据分组——笔记
聚类: 聚类是一种无监督的学习,它将相似的对象归到同一个簇中.有点像全自动分类.聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好.聚类分析试图将相似对象归入同一簇,将不相似对象归到不同 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- K均值聚类
聚类(cluster)与分类的不同之处在于, 分类算法训练过程中样本所属的分类是已知的属监督学习. 而聚类算法不需要带有分类的训练数据,而是根据样本特征的相似性将其分为几类,又称为无监督分类. K均值 ...
随机推荐
- C++STL 迭代器
迭代器类别: 输入迭代器(只读迭代器).输出迭代器(只写迭代器).正向迭代器.双向迭代器.随机访问迭代器 逆向遍历 for(vector<int>::reverse_iterator ri ...
- struts2访问web资源
通过ActionContext访问 public class TestActionContextAction { public String execute(){ //获取 ActionContext ...
- 20145232 韩文浩 《Java程序设计》第9周学习总结
教材学习内容总结 学习目标 了解JDBC架构 掌握JDBC架构 掌握反射与ClassLoader 了解自定义泛型和自定义枚举 会使用标准注解 JDBC标准主要分为两个部分:JDBC应用程序开发者接口和 ...
- bash多进程
#!/bin/bashCMD_PATH=`dirname $0`#echo $CMD_PATH > /home/wubin/testjava -jar $CMD_PATH/Server.jar ...
- android 增量更新原理
原理如下:服务器端设计增量表,记录数据操作顺序id,和增删改查信息.在进行数据库表操作的时候同时进行将信息保存在增量表. android客户端在请求的时候上传最后保存的id.服务端判断最后的id,返回 ...
- Java的StringBuffer和StringBuilder类
StringBuffer (字符串缓冲对象) 概念:用于表示可以修改的字符串,称为字符串缓冲对象 作用:使用运算符的字符串将自动创建字符串缓冲对象 例如: str1+str2的操作,实际上是把str1 ...
- 我看Windows 8.1
在大家惊叹于Windows 8的大胆创新之时,Windows 8.1却已然来到.在公布了Preview之后,笔者便迫不及待地进行了安装,并在这里简单的说说最直观的感受. 提到Windows 8,不得不 ...
- 关于FPGA的一些小见解
Xilinx FPGA配置bit流文件 Xilinx FPGA的供电是采用USB作为电源,使用Verilog HDL或VHDL实现的逻辑电路通过Xilinx的综合工具生成bit流文件,通过Digile ...
- 2-Sat小结
关于2-sat,其实就是一些对于每个问题只有两种解,一般会给出问题间的关系,比如and,or,not等关系,判定是否存在解的问题.. 具体看http://blog.csdn.net/jarjingx/ ...
- php支付宝手机网页支付类实例
<?php $alipayConfig = array( 'key' => 'xxxxx', //买卖安全校验码,用于签名的32位密钥 'transport' => 'https', ...