python数据分析Numpy(二)
Numpy (Numerical Python)
- 高性能科学计算和数据分析的基础包;
- ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间;
- 矩阵运算,无需循环,可以完成类似Matlab中的矢量运算;
- 线性代数、随机送生成;
ndarray ,N维数组对象(矩阵)
- 所有元素必须是相同类型
- ndim属性,维度个数
- shape属性,各维度大小
- dtype属性,数据类型
代码示例:
import numpy
# 生成指定维度的随机多维数据(两行三列)
data = numpy.random.rand(2, 3)
print data
print type(data)
- 执行结果:
[[ 0.49458614 0.14245674 0.26883084]
[ 0.87402248 0.71089966 0.29023523]]
<type 'numpy.ndarray'>
print '维度个数', data.ndim
print '各维度大小: ', data.shape
print '数据类型: ', data.dtype
- 执行结果:
维度个数 2
各维度大小: (2L, 3L)
数据类型: float64
1、创建ndarray
numpy.array(collection),collection为序列型对象(list),嵌套序列(list of list)
# list 转换为 ndarray(一维数组)
l = range(10)
data = numpy.array(l)
print data
print data.shape
print data.ndim
- 执行结果
[0 1 2 3 4 5 6 7 8 9]
(10L,)
1
# 嵌套序列转换为ndarray
l2 = [range(10), range(10)]
data = numpy.array(l2)
print data
print data.shape
- 执行结果
[[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]]
(2L, 10L)
numpy.zeros,numpy.ones,numpy.empty 指定大小的全0或全1数组
- 第一个参数是元祖,用来指定大小,如(3,4)
- empty不是总是返回全0,有事返回的是未初始的随机值
# numpy.zeros
zeros_arr = numpy.zeros((3, 4)) # numpy.ones
ones_arr = numpy.ones((2, 3)) # numpy.empty
empty_arr = numpy.empty((3, 3)) # numpy.empty 指定数据类型
empty_int_arr = numpy.empty((3, 3), int) print zeros_arr
print '-------------'
print ones_arr
print '-------------'
print empty_arr
print '-------------'
print empty_int_arr
- 执行结果:
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
-------------
[[ 1. 1. 1.]
[ 1. 1. 1.]]
-------------
[[ 2.10788133e-316 2.98795843e-316 2.16703793e-316]
[ 1.55258311e-316 1.55258311e-316 2.10819471e-316]
[ 2.98795843e-316 2.42334417e-316 3.32767718e-316]]
-------------
[[1778384910 40108033 156928]
[1509950083 23330819 217856]
[1392509284 0 24969340]]
numpy.arange()类似range()
print numpy.arange(10)
- 执行结果:
[0 1 2 3 4 5 6 7 8 9]
ndarray数据类型
- dtype,类型名+位数,如float64、int32
- 转换数组类型 astype
zeros_float_arr = numpy.zeros((3, 4), dtype=numpy.float64)
print zeros_float_arr
print zeros_float_arr.dtype # astype转换数据类型
zeros_int_arr = zeros_float_arr.astype(numpy.int32)
print zeros_int_arr
print zeros_int_arr.dtype
- 执行结果:
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
float64
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
int32
矢量化(vectorization)
- 矢量运算,相同大小的数组键间的运算应用在元素上
- 矢量和标量运算,“广播”- 将标量“广播”到各个元素
# 矢量与矢量运算
arr = numpy.array([[1, 2, 3],
[4, 5, 6]]) print "元素相乘:"
print arr * arr print "矩阵相加:"
print arr + arr
- 执行结果:
元素相乘:
[[ 1 4 9]
[16 25 36]]
矩阵相加:
[[ 2 4 6]
[ 8 10 12]]
arr = numpy.array([[1, 2, 3],
[4, 5, 6]])
# 矢量与标量运算
print 1. / arr
print 2. * arr
- 执行结果:
[[ 1. 0.5 0.33333333]
[ 0.25 0.2 0.16666667]]
[[ 2. 4. 6.]
[ 8. 10. 12.]]
索引与切片
- 一维数组与python的列表索引功能相似
- 多维数组的索引 (arr[1,1]等价于arr[1][1],[:]代表某个维度的数据)
- 条件索引(布尔值多维数组,arr[condition],condition可以是多个条件组合,多个条件组合要使用&、|,而不是and、or)
# 一维数组
arr1 = numpy.arange(10)
print arr1 print arr1[2:5]
- 执行结果:
[0 1 2 3 4 5 6 7 8 9]
[2 3 4]
# 多维数组
arr2 = numpy.arange(12).reshape(3,4)
print arr2
print arr2[1]
print arr2[0:2, 2:]
print arr2[:, 1:3]
- 执行结果:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] [4 5 6 7] [[2 3]
[6 7]] [[ 1 2]
[ 5 6]
[ 9 10]]

# 条件索引 # 找出 data_arr 中 2015年后的数据
data_arr = numpy.random.rand(3,3)
print data_arr year_arr = numpy.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]]) is_year_after_2005 = year_arr >= 2005
print is_year_after_2005, is_year_after_2005.dtype filtered_arr = data_arr[is_year_after_2005]
print filtered_arr
- 执行结果:
[[ 0.63168725 0.85543622 0.30599083]
[ 0.11615184 0.51911173 0.52385353]
[ 0.14844493 0.91796881 0.21024523]] [[False False False]
[ True False True]
[False False True]] bool [ 0.11615184 0.52385353 0.21024523]
上面条件索引简洁写法
# 条件索引 # 找出 data_arr 中 2015年后的数据
data_arr = numpy.random.rand(3,3)
print data_arr year_arr = numpy.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]]) filtered_arr = data_arr[year_arr >= 2005]
print filtered_arr
执行结果:
[[ 0.95234521 0.5807057 0.52735329]
[ 0.47923737 0.59162051 0.45005005]
[ 0.76956902 0.42958933 0.79465332]] [ 0.47923737 0.45005005 0.79465332]
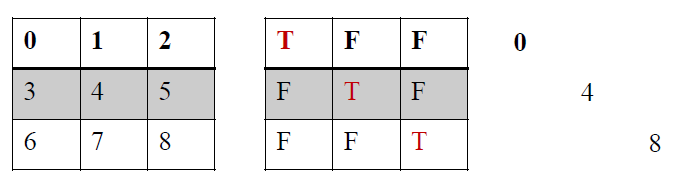
# 条件索引 # 找出 data_arr 中 2015年以前的数据,并且除2余0
data_arr = numpy.random.rand(3,3)
print data_arr year_arr = numpy.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]]) # 多个条件
filtered_arr = data_arr[(year_arr <= 2005) & (year_arr % 2 == 0)]
print filtered_arr
执行结果:
[[ 0.73363831 0.82841715 0.96231068]
[ 0.88736662 0.31812448 0.58970943]
[ 0.30176911 0.37907437 0.13729544]] [ 0.73363831 0.96231068 0.31812448]
维数转换
- 转置transpose
- 高维数组转置要指定维度编号

arr = numpy.random.rand(2,3)
print arr
print arr.transpose()
执行结果:
[[ 0.0386642 0.87739409 0.58251658]
[ 0.88991982 0.73074965 0.92150766]] [[ 0.0386642 0.88991982]
[ 0.87739409 0.73074965]
[ 0.58251658 0.92150766]]
arr3d = numpy.random.rand(2,3,4)
print arr3d
print '----------------------'
print arr3d.transpose((1,0,2)) # 3x2x4
执行结果:
[[[ 0.58897083 0.3391822 0.33545661 0.94196946]
[ 0.55366683 0.20265899 0.6147795 0.18669334]
[ 0.93987911 0.43558565 0.58834912 0.99346361]] [[ 0.84025212 0.86950502 0.69863368 0.91995894]
[ 0.85805814 0.26802831 0.06903254 0.40061396]
[ 0.56639909 0.23823499 0.48753265 0.54143843]]]
----------------------
[[[ 0.58897083 0.3391822 0.33545661 0.94196946]
[ 0.84025212 0.86950502 0.69863368 0.91995894]] [[ 0.55366683 0.20265899 0.6147795 0.18669334]
[ 0.85805814 0.26802831 0.06903254 0.40061396]] [[ 0.93987911 0.43558565 0.58834912 0.99346361]
[ 0.56639909 0.23823499 0.48753265 0.54143843]]]
说明:代码中transpose参数元组(1,0,2)可以理解为是索引组成的元组,
1对应的还是3,0对应的还是2,2对应的还是4, 通过索引的位置变换。
通用函数(ufunc)
- 元素级运算
- ceil,向上最接近的整数
- floor,向下最接近的整数
- rint,四舍五入
- isnan,判断元素是否为NaN(Not a Number)
- multiply,元素相乘
- divide,元素相除
arr = numpy.random.randn(2,3) print arr
print numpy.ceil(arr)
print numpy.floor(arr)
print numpy.rint(arr)
print numpy.isnan(arr)
- 执行结果:
[[-1.58805196 -0.81383734 -0.0310861 ]
[-1.19410445 0.77250857 0.66694595]] [[-1. -0. -0.]
[-1. 1. 1.]] [[-2. -1. -1.]
[-2. 0. 0.]] [[-2. -1. 0.]
[-1. 1. 1.]] [[False False False]
[False False False]]
numpy.where
- 矢量版本的三元表达式 x if condition else y
- numpy.where(condition,x,y)
arr = numpy.random.randn(3,4)
print arr numpy.where(arr > 0, 1, -1)
- 执行结果:
[[-0.06283048 0.90505846 -1.53498969 1.44885017]
[ 0.19133703 -1.63035289 1.40158507 0.05605055]
[ 1.58101557 1.31273601 -0.17298785 -1.95508151]] array([[-1, 1, -1, 1],
[ 1, -1, 1, 1],
[ 1, 1, -1, -1]])
常用统计方法
- numpy.mean 数组平均值
- numpy.sum 数组求和
- numpy.max 数组最大值
- numpy.min 数组最小值
- numpy.std 数组平方差
- numpy.var 数组方差
- numpy.argmax 最大元素的下标输出
- numpy.argmin 最小元素的下标输出
- numpy.cumsum 累加
- numpy.cumprod 累乘
- numpy.all 全部满足条件
- numpy.any 至少有一个元素满足条件
- numpy.unique 找到唯一值并返回排序结果
- numpy.loadtxt
注意:多维数组可以指定统计的维度,否则默认是全部维度上做统计。
arr = numpy.arange(10).reshape(5,2)
print arr
print numpy.sum(arr)
print numpy.sum(arr, axis=0)
print numpy.sum(arr, axis=1)
执行结果:
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]] 45 [20 25] [ 1 5 9 13 17]
arr = numpy.random.randn(2,3)
print arr
print numpy.any(arr > 0)
print numpy.all(arr > 0)
- 执行结果:
[[-0.89387663 0.69226989 -1.71408496]
[-0.25904772 -0.88833077 -1.141312 ]] True False
arr = numpy.array([[1, 2, 1], [2, 3, 4]])
print arr
print numpy.unique(arr)
执行结果:
[[1 2 1]
[2 3 4]] [1 2 3 4]
# loadtxt, 明确指定每列数据的类型
filename = './shhnwangjian.csv'
data_array = numpy.loadtxt(filename, # 文件名
delimiter=',', # 分隔符
skiprows=1, # 跳过第一行
dtype={'names':('cycle', 'type', 'matchup'),
'formats':('i4', 'S15', 'S50')}, # 数据类型
usecols=(0,2,3)) # 指定读取的列索引号 print data_array, data_array.shape # 读取的结果是一维的数组,每个元素是一个元组
学习参考
快速入门numpy、scipy https://docs.scipy.org/doc/numpy-dev/user/quickstart.html
numpy教程 http://cs231n.github.io/python-numpy-tutorial/
numpy、SciPy 介绍 https://engineering.ucsb.edu/~shell/che210d/numpy.pdf
13个numpy、SciPy教程 http://www.erzama.com/scipy-numpy-tutorials-w-12023/
《Python数据分析基础教程:NumPy学习指南》
python数据分析Numpy(二)的更多相关文章
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
- Python数据分析Numpy库方法简介(二)
数据分析图片保存:vg 1.保存图片:plt.savefig(path) 2.图片格式:jpg,png,svg(建议使用,不失真) 3.数据存储格式: excle,csv csv介绍 csv就是用逗号 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- python 数据分析----numpy
NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进行快速运算的数学函数 ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- Python数据分析 | Numpy与1维数组操作
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/33 本文地址:http://www.showmeai.tech/article-det ...
- [读书笔记] Python数据分析 (二) 引言
1. 数据分析的任务:数据读写,数据准备(清洗,修整,规范化,重塑,切片切块,变形),转换,建模计算,呈现(模型/数据) 2. 数据集: bit.ly的1.usa.gov数据:URL缩短服务bit ...
随机推荐
- Jenkins控制台输出乱码
一.问题详情 jenkins构建mav任务,在控制台显示乱码: 二.原因分析 1. 查看系统编码和tomcat的编码都正常 # grep encoding /usr/local/tomcat/conf ...
- R绘图 第六篇:绘制线图(ggplot2)
线图是由折线构成的图形,线图是把散点从左向右用直线连接起来而构成的图形,在以时间序列为x轴的线图中,可以看到数据增长的趋势. geom_line(mapping = NULL, data = NULL ...
- JQuery快速入门-Ajax
一.AJAX概述 概念:AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML). 优点:通过在后台与服务器进行少量数据交换,AJAX ...
- Java中Class类详解、用法及泛化
Java中Class类及用法 Java程序在运行时,Java运行时系统一直对所有的对象进行所谓的运行时类型标识,即所谓的RTTI.这项信息纪录了每个对象所属的类.虚拟机通常使用运行时类型信息选准正确方 ...
- iOSApp上下有黑边
如图: 这种情况就是没有启动页导致的,加了启动页图片之后就不会再出现了. 设置启动页的方法: http://www.cnblogs.com/BK-12345/p/5218229.html 有的人说我加 ...
- 如何设计一个异步Web服务——任务调度
接上一篇<如何设计一个异步Web服务——接口部分> Application已经将任务信息发到了Service服务器中,接下来,Service服务器改如何对自身的资源进行合理分配以满足App ...
- 【DDD】业务建模实践 —— 发布帖子
本文是基于上一篇‘业务建模战术’的实践,主要讲解‘发表帖子’场景的业务建模,包括:业务建模.业务模型.示例代码:示例代码会使用java编写,文末附有github地址.相比于<领域驱动设计> ...
- python基础面试题
函数1def foo(arg,li=[]): li.append(arg) return li list1 = foo(21) list2 = foo(11,[2]) list3 = foo(28) ...
- PAT甲题题解-1063. Set Similarity (25)-set的使用
题意:两个整数集合,它们的相似度定义为:nc/nt*100%nc为两个集合都有的整数nt为两个集合一共有的整数注意这里的整数都是各不相同的,即重复的不考虑在内.给出n个整数集合,和k个询问,让你输出每 ...
- [2017BUAA软工助教]团队beta得分总表
一.累计得分 项目 α例会 α发布 α测试 α展示 α事后 合计 满分 50 10 10 150 10 230 hotcode5 50 10 9 150 9 228 弗朗明哥舞步 50 10 8 13 ...