Dropout原理解析
1. Dropout简介
1.1 Dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
1.2 什么是Dropout
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
在2012年,Alex、Hinton在其论文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止过拟合。并且,这篇论文提到的AlexNet网络模型引爆了神经网络应用热潮,并赢得了2012年图像识别大赛冠军,使得CNN成为图像分类上的核心算法模型。
随后,又有一些关于Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
从上面的论文中,我们能感受到Dropout在深度学习中的重要性。那么,到底什么是Dropout呢?
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。
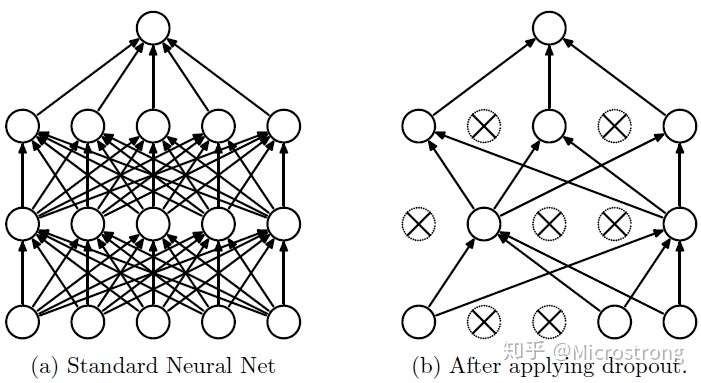
2. Dropout工作流程及使用
2.1 Dropout具体工作流程
假设我们要训练这样一个神经网络,如图2所示。
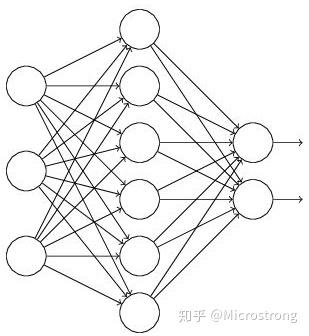
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
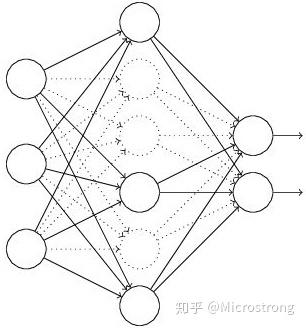
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
2.2 Dropout在神经网络中的使用
Dropout的具体工作流程上面已经详细的介绍过了,但是具体怎么让某些神经元以一定的概率停止工作(就是被删除掉)?代码层面如何实现呢?
下面,我们具体讲解一下Dropout代码层面的一些公式推导及代码实现思路。
(1)在训练模型阶段
无可避免的,在训练网络的每个单元都要添加一道概率流程。
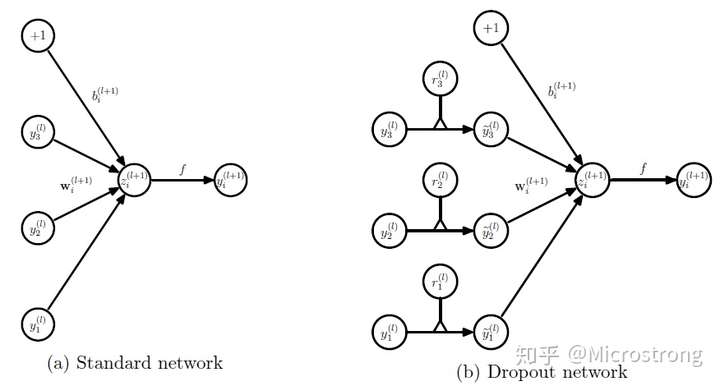
对应的公式变化如下:
- 没有Dropout的网络计算公式:
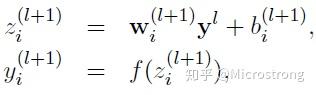
- 采用Dropout的网络计算公式:
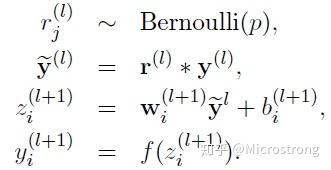
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、......、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
(2)在测试模型阶段
预测模型的时候,每一个神经单元的权重参数要乘以概率p。
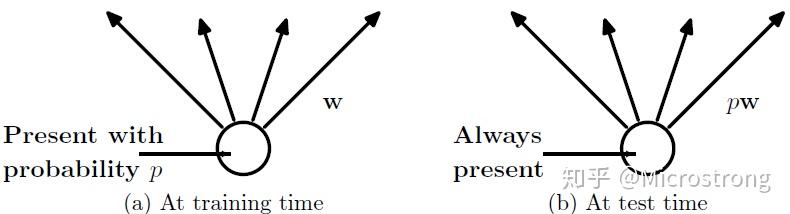
测试阶段Dropout公式:
3. 为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
4. Dropout在Keras中的源码分析
下面,我们来分析Keras中Dropout实现源码。
Keras开源项目GitHub地址为:
https://github.com/fchollet/keras/tree/master/keras
其中Dropout函数代码实现所在的文件地址:
https://github.com/fchollet/keras/blob/master/keras/backend/theano_backend.py
Dropout实现函数如下:

我们对keras中Dropout实现函数做一些修改,让dropout函数可以单独运行。
# coding:utf-8
import numpy as np
# dropout函数的实现
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必须在0~1之间
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
# 硬币 正面的概率为p,n表示每个神经元试验的次数
# 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
函数中,x是本层网络的激活值。Level就是dropout就是每个神经元要被丢弃的概率。
注意: Keras中Dropout的实现,是屏蔽掉某些神经元,使其激活值为0以后,对激活值向量x1……x1000进行放大,也就是乘以1/(1-p)。
思考:上面我们介绍了两种方法进行Dropout的缩放,那么Dropout为什么需要进行缩放呢?
因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了。如果丢弃一些神经元,这会带来结果不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为模型预测不准。那么一种”补偿“的方案就是每个神经元的权重都乘以一个p,这样在“总体上”使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率参与训练,(1-p)的概率丢弃,那么它输出的期望是px+(1-p)0=px。因此测试的时候把这个神经元的权重乘以p可以得到同样的期望。
总结:
当前Dropout被大量利用于全连接网络,而且一般认为设置为0.5或者0.3,而在卷积网络隐藏层中由于卷积自身的稀疏化以及稀疏化的ReLu函数的大量使用等原因,Dropout策略在卷积网络隐藏层中使用较少。总体而言,Dropout是一个超参,需要根据具体的网络、具体的应用领域进行尝试。
Reference:
- Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv:1207.0580, 2012.
- Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
- Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
- Srivastava N. Improving neural networks with dropout[J]. University of Toronto, 2013, 182.
- Bouthillier X, Konda K, Vincent P, et al. Dropout as data augmentation[J]. arXiv preprint arXiv:1506.08700, 2015.
7. 理解dropout
8. Dropout解决过拟合问题 - 晓雷的文章 - 知乎
https://zhuanlan.zhihu.com/p/23178423
10. Dropout原理,代码浅析
11. Deep learning:四十一(Dropout简单理解)
我的个人微信公众号:Microstrong
微信公众号ID:MicrostrongAI
公众号介绍:Microstrong(小强)同学主要研究机器学习、深度学习、图像处理、计算机视觉相关内容,分享在学习过程中的读书笔记!期待您的关注,欢迎一起学习交流进步!
个人博客:
Dropout原理解析的更多相关文章
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Hebye 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- alibaba-dexposed 原理解析
alibaba-dexposed 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49821413 原理参考地址: htt ...
- 支付宝Andfix 原理解析
支付宝Andfix 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49802429 原理参考地址: http://blo ...
随机推荐
- 多线程编程中的EventWaitHandler
首先如果读者是.Net多线程编程的老手,就不用看这篇文章了,这篇文章主要是阐述EventWaitHandler的一些基本原理和用法. 在.NET的System.Threading命名空间中有一个名叫W ...
- 给虚拟机下面的ubuntu系统增加硬盘存储空间
给虚拟机下面的ubuntu系统增加硬盘存储空间 由于ubuntu系统是安装在vsphere上面的,所以可能会和vmware上面的有一点区别,打开exsi系统的配置页面,如下图所示. 选择添加存储器 ...
- 002.RAID创建
一 创建相应的分区 [root@kauai ~]# fdisk /dev/sdb 最终创建多个用于做RAID的分区,如下: Device Boot Start End Blocks Id System ...
- 008.FTP单独虚拟用户
一 单独虚拟用户概念 给每个虚拟用户单独建立目录,并建立自己的配置文件,方便单独配置权限,并可以单独制定上传目录. 二 单独为虚拟用户设置权限 2.1 创建用户单独保存虚拟用户配置文件的目录 [roo ...
- Java 内存模型 ,一篇就够了!
Java 虚拟机 我们都知道 Java 语言的可以跨平台的,这其中的核心是因为存在 Java 虚拟机这个玩意.虚拟机,顾名思义就是虚拟的机器,这不是真实存在的硬件,但是却可以和不同的底层平台进行交 ...
- C#泛型的抗变与协变
C#泛型的抗变与协变 学习自 C#本质论6.0 https://www.cnblogs.com/pugang/archive/2011/11/09/2242380.html Overview 一直以来 ...
- BZOJ4115 : [Wf2015]Tile Cutting
设一种方案里三角形上三个点的坐标分别为$(0,0),(-a,b),(c,d)$,则得到的平行四边形的面积为$ac+bd$. 设$d(n)$为$n$的约数个数,$D$为$d$的生成函数,则答案的生成函数 ...
- Gunicorn设计部分的翻译
Design 关于Gunicorn架构的简要描述. Server Model Gunicorn是基于pre-fork(预启动,提前fork)的工作模式.这就意味着Gunicorn是由一个主进程来管理这 ...
- java判断集合是否重复的一种便捷方法
内容来自其它网站,感谢原作者! import java.util.ArrayList; import java.util.HashSet; import java.util.List; /** * 通 ...
- mysql|表row_format的静态与动态,Compact
innodb 一般对应 Compact ,MyISAM 一般对应静态与动态 mysql中若一张表里面存在varchar.text以及其变形.blob以及其变形的字段的话,那么这个表其实也叫动态表,即 ...