hadoop集群中zkfc的作用和工作过程
一、 简单了解NameNode的ZKFC机制
NameNode的HA可以个人认为简单分为共享editLog机制和ZKFC对NameNode状态的控制
一般导致NameNode切换的原因
ZKFC的作用是什么?如何判断一个NN是否健康
一般导致NameNode切换的原因
随着集群规模的变大和任务量变多,NameNode的压力会越来越大,一些默认参数已经不能满足集群的日常需求,除此之外,异常的Job在短时间内创建和删除大量文件,引起NN节点频繁更新内存的数据结构从而导致RPC的处理时间变长,CallQueue里面的RpcCall堆积,甚至严重的情况下打满CallQueue,导致NameNode响应变慢,甚至无响应,ZKFC的HealthMonitor监控自己的NN异常时,则会断开与ZooKeeper的链接,从而释放锁,另外一个NN上的ZKFC进行抢锁进行Standby到Active状态的切换。这是一般引起的切换的流程。
当然,如果你是手动去切换这也是可以的,当Active主机出现异常时,有时候则需要在必要的时间内进行切换。
ZKFC的作用是什么?如何判断一个NN是否健康
在正常的情况下,ZKFC的HealthMonitor主要是监控NameNode主机上的磁盘还是否可用(空间),我们都知道,NameNode负责维护集群上的元数据信息,当磁盘不可用的时候,NN就该进行切换了。
二、基本概念
首先我们要明确ZKFC 是什么,有什么作用:
zkfc是什么? ZooKeeperFailoverController
它是什么?是Hadoop中通过ZK实现FC功能的一个实用工具。
主要作用:作为一个ZK集群的客户端,用来监控NN的状态信息。
谁会用它?每个运行NN的节点必须要运行一个zkfc
三、有啥功能?
1.Health monitoring
zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点。
2.ZooKeeper Session Management
当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc还有持有一个”ephemeral”的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除。
3.ZooKeeper-based election
如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。Failover的过程是:第一步,对之前的NN执行fence,如果需要的话。第二步,将本地NN转换到active状态。
另外:
如果一个Active因HealthMonitor监控到状态异常,这里会作出判断,先通过Fencing功能关闭它(确保关闭或者不能提供服务),然后在ZK上删除它对应ZNode。
发送上述事件后,在另外一台机器上的ZKFC中的ActiveStandbyElector 会收到事件,并重新进行选举(尝试创建特定ZNode),它将获得成功并更改NN中状态,从而实现Active节点的变更。
四、基本原理
zk的基本特性:
(1) 可靠存储小量数据且提供强一致性
(2) ephemeral node(创建的锁节点), 在创建它的客户端关闭后,可以自动删除
(3) 对于node状态的变化,可以提供异步的通知(watcher)
zk在zkfc中可以提供的功能:
(1) Failure detector(通过watcher监听机制实现): 及时发现出故障的NN,并通知zkfc
(2) Active node locator: 帮助客户端定位哪个是Active的NN
(3) Mutual exclusion of active state(通过加锁): 保证某一时刻只有一个Active的NN
五、 模块
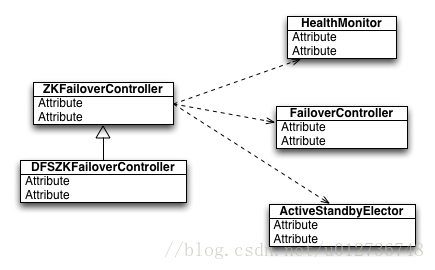
(1) ZKFailoverController(DFSZKFailoverController): 驱动整个ZKFC的运转,通过向HealthMonitor和ActiveStandbyElector注册回调函数的方式,subscribe HealthMonitor和ActiveStandbyElector的事件,并做相应的处理
(2) HealthMonitor: 定期check NN的健康状况,在NN健康状况发生变化时,通过回调函数把变化通知给ZKFailoverController
(3) ActiveStandbyElector: 管理NN在zookeeper上的状态,zookeeper上对应node的结点发生变化时,通过回调函数把变化通知给ZKFailoverController
(4) FailoverController: 提供做graceful failover的相关功能(dfs admin可以通过命令行工具手工发起failover) 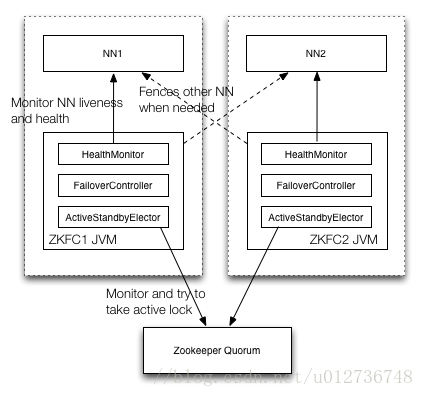
六、系统架构
如上图所示,通常情况下Namenode和ZKFC同布署在同一台物理机器上, HealthMonitor, FailoverController, ActiveStandbyElector在同一个JVM进程中(即ZKFC), Namenode是一个单独的JVM进程。如上图所示,ZKFC在整个系统中有几个重要的作用:
(1) Monitor and try to take active lock: 向zookeeper抢锁,抢锁成功的zkfc,指导对应的NN成为active的NN; watch锁对应的znode,当前active NN的状态发生变化导致失锁时,及时抢锁,努力成为active NN
(2) Monitor NN liveness and health: 定期检查对应NN的状态, 当NN状态发生变化时,及时通过ZKFC做相应的处理
(3) Fences other NN when needed: 当前NN要成为active NN时,需要fence其它的NN,不能同时有多个active NN
七、线程模型
ZKFC的线程模型总体上来讲比较简单的,它主要包括三类线程,一是主线程;一是HealthMonitor线程; 一是zookeeper客户端的线程。它们的主要工作方式是:
(1) 主线程在启动所有的服务后就开始循环等待
(2) HealthMonitor是一个单独的线程,它定期向NN发包,检查NN的健康状况
(3) 当NN的状态发生变化时,HealthMonitor线程会回调ZKFailoverController注册进来的回调函数,通知ZKFailoverController NN的状态发生了变化
(4) ZKFailoverController收到通知后,会调用ActiveStandbyElector的API,来管理在zookeeper上的结点的状态
(5) ActiveStandbyElector会调用zookeeper客户端API监控zookeeper上结点的状态,发生变化时,回调ZKFailoverController的回调函数,通知ZKFailoverController,做出相应的变化
八、 类关系图
hadoop集群中zkfc的作用和工作过程的更多相关文章
- Hadoop集群中添加硬盘
Hadoop工作节点扩展硬盘空间 接到老板任务,Hadoop集群中硬盘空间不够用,要求加一台机器到Hadoop集群,并且每台机器在原有基础上加一块2T硬盘,老板给力啊,哈哈. 这些我把完成这项任务的步 ...
- 在Hadoop集群中添加机器和删除机器
本文转自:http://www.cnblogs.com/gpcuster/archive/2011/04/12/2013411.html 无论是在Hadoop集群中添加机器和删除机器,都无需停机,整个 ...
- 一次hadoop集群机器加内存的运维过程
由于前期的集群规划问题,导致当前Hadoop集群中的硬件并没有完全利用起来.当前机器的内存CPU比例为2G:1core,但一般的MapReduce任务(数据量处理比较大,逻辑较复杂)的MR两端都需要将 ...
- 如何使用Hive&R从Hadoop集群中提取数据进行分析
一个简单的例子! 环境:CentOS6.5 Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 1.分析题目 --有一个用户数据样本(表名huserinfo)10万数据左右: ...
- hadoop集群中动态添加新的DataNode节点
集群中现有的计算能力不足,须要另外加入新的节点时,使用例如以下方法就能动态添加新的节点: 1.在新的节点上安装hadoop程序,一定要控制好版本号,能够从集群上其它机器cp一份改动也行 2.把name ...
- hadoop集群中客户端修改、删除文件失败
这是因为hadoop集群在启动时自动进入安全模式 查看安全模式状态:hadoop fs –safemode get 进入安全模式状态:hadoop fs –safemode enter 退出安全模式状 ...
- hadoop集群中动态添加节点
集群的性能问题需要增加服务器节点以提高整体性能 https://www.cnblogs.com/fefjay/p/6048269.html hadoop集群之间hdfs文件复制 https://www ...
- hadoop 集群中数据块的副本存放策略
HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性.可用性和网络带宽的利用率.目前实现的副本存放策略只是在这个方向上的第一步.实现这个策略的短期目标是验证它在生产环境下的有效 ...
- Hadoop集群中Hbase的介绍、安装、使用
导读 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. 一.Hbase ...
随机推荐
- 第15.24节 PyQt(Python+Qt)入门学习:Model/View架构中QTableView的作用及属性详解
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在Designer的部件栏Item Views中提供了PyQt和Qt已经实现好的table ...
- 第12.2节 Python sys模块导览
sys模块包括一些用于系统处理的功能,常用的成员包括: sys.argv:当前执行进程的命令参数列表,不含执行程序本身的名字: sys.stdin .sys.stdout 和 stderr :分别对应 ...
- python 读取excel表格内不同类型的数据
不同类型数据对应值: #coding=utf-8 import os import xlrd from datetime import datetime,date newparh = os.chdir ...
- Java 8 中的方法引用,轻松减少代码量,提升可读性!
1. 引言 Java8中最受广大开发中喜欢的变化之一是因为引入了 lambda 表达式,因为这些表达式允许我们放弃匿名类,从而大大减少了样板代码,并提高了可读性. 方法引用是lambda表达式的一种特 ...
- LeetCode初级算法之数组:1 两数之和
两数之和 题目地址:https://leetcode-cn.com/problems/two-sum/ 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个整 ...
- 新挖个坑,准备学习一下databricks的spark博客
挖坑 https://databricks.com/blog 一.spark3.0特性(Introducing Apache Spark 3.0) 1.通过通过自适应查询执行,动态分区修剪和其他优化使 ...
- Docker部署FastDFS(附示例代码)
1. FastDFS简介 FastDFS是一个开源的分布式文件系统,它对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题.特别适合以文 ...
- Maven基础知识详解
1. 简介 Maven在Java领域的应用已经非常广泛了,有了Maven的存在是的开发人员在搭建.依赖.扩展和打包项目上变得非常简单. 2. Windows安装Maven 下载安装包 http ...
- css精髓:这些布局你都学废了吗?
前言 最近忙里偷闲,给自己加油充电的时候,发现自己脑海中布局这块非常的凌乱混杂,于是花了一些时间将一些常用的布局及其实现方法整理梳理了出来,在这里,分享给大家. 单列布局 单列布局是最常用的一种布局, ...
- 多个HDFS集群的fs.defaultFS配置一样,造成应用一直连接同一个集群的问题分析
背景 应用需要对两个集群中的同一目录下的HDFS文件个数和文件总大小进行比对,在测试环境中发现,即使两边HDFS目录下的数据不一样,应用日志显示两边始终比对一致,分下下来发现,应用连的一直是同一个集群 ...