java并发包提供的三种常用并发队列实现
java并发包中提供了三个常用的并发队列实现,分别是:ConcurrentLinkedQueue、LinkedBlockingQueue和ArrayBlockingQueue。
ConcurrentLinkedQueue使用的是CAS原语无锁队列实现,是一个异步队列,入队速度很快,出队进行了加锁,性能稍慢;
LinkedBlockingQueue也是阻塞队列,入队和出队都用了加锁,当队空的时候线程会暂时阻塞;当队空的时候线程会暂时阻塞;
ArrayBlockingQueue是初始容器固定的阻塞队列,我们可以用来作为数据库模块成功竞拍的队列,比如有10个商品,那么我们就设定一个10大小的数组队列。
一、BlockingQueue接口
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
二、ArrayBlockingQueue
ArrayBlockingQueue是一个由数组支持的有界阻塞队列。在读写操作上都需要锁住整个容器,因此吞吐量与一般的实现是相似的,适合于实现“生产者消费者”模式。
三、LinkedBlockingQueue
LinkedBlockingQueue内部维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
3. 队列大小初始化方式不同
ArrayBlockingQueue是有界的,必须指定队列的大小;
LinkedBlockingQueue是无界的,可以不指定队列的大小,但是默认是Integer.MAX_VALUE。当然也可以指定队列大小,从而成为有界的;
注意:
1. 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出;
2. 在使用ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,
LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,
即LinkedBlockingQueue消耗在1500ms左右,而ArrayBlockingQueue只需150ms左右。
性能测试:不限容量的LinkedBlockingQueue的吞吐量 > ArrayBlockingQueue > 限定容量的LinkedBlockingQueue
LinkedBlockingQueue内部使用ReentrantLock实现插入锁(putLock)和取出锁(takeLock)。putLock上的条件变量是notFull,即可以用notFull唤醒阻塞在putLock上的线程。takeLock上的条件变量是notEmtpy,即可用notEmpty唤醒阻塞在takeLock上的线程。
四、ArrayBlockingQueue和LinkedBlockingQueue的区别
1. 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock;
2. 在生产或消费时操作不同
ArrayBlockingQueue基于数组,在生产和消费的时候,是直接将枚举对象插入或移除的,不会产生或销毁任何额外的对象实例;
LinkedBlockingQueue基于链表,在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会生成一个额外的Node对象,这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别;
注意:
1. 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出;
2. 在使用ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,
LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,
即LinkedBlockingQueue消耗在1500ms左右,而ArrayBlockingQueue只需150ms左右。
性能测试:不限容量的LinkedBlockingQueue的吞吐量 > ArrayBlockingQueue > 限定容量的LinkedBlockingQueue
五、添加、删除元素的区别
添加元素的方法有三个:add,put,offer
1、add方法: LinkedBlockingQueue构造的时候若没有指定大小,则默认大小为Integer.MAX_VALUE,当然也可以在构造函数的参数中指定大小。LinkedBlockingQueue不接受null。add方法在添加元素的时候,若超出了度列的长度会直接抛出异常;
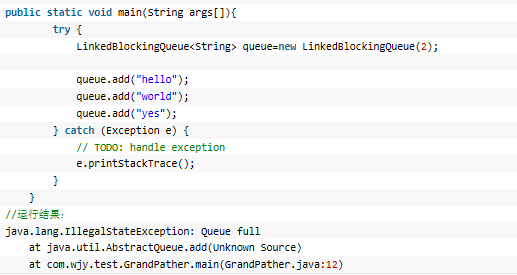
2、put方法:若向队尾添加元素的时候发现队列已经满了会发生阻塞一直等待空间,以加入元素;

3、offer方法: offer方法在添加元素时,如果发现队列已满无法添加的话,会直接返回false。

poll: 若队列为空,返回null。
remove:若队列为空,抛出NoSuchElementException异常。
take:若队列为空,发生阻塞,等待有元素。
java并发包提供的三种常用并发队列实现的更多相关文章
- Java深入学习(2):并发队列
并发队列: 在并发队列中,JDK有两套实现: ConcurrentLinkedQueue:非阻塞式队列 BlockingQueue:阻塞式队列 阻塞式队列非阻塞式队列的区别: 阻塞式队列入列操作的时候 ...
- Java并发包下锁学习第二篇Java并发基础框架-队列同步器介绍
Java并发包下锁学习第二篇队列同步器 还记得在第一篇文章中,讲到的locks包下的类结果图吗?如下图: 从图中,我们可以看到AbstractQueuedSynchronizer这个类很重要(在本 ...
- Java 并发包中的读写锁及其实现分析
1. 前言 在Java并发包中常用的锁(如:ReentrantLock),基本上都是排他锁,这些锁在同一时刻只允许一个线程进行访问,而读写锁在同一时 刻可以允许多个读线程访问,但是在写线程访问时,所有 ...
- Java并发包中线程池的种类和特点介绍
Java并发包提供了包括原子量.并发集合.同步器.可重入锁.线程池等强大工具这里学习一下线程池的种类和特性介绍. 如果每项任务都分配一个线程,当任务特别多的时候,可能会超出系统承载能力.而且线程的创建 ...
- Java并发包线程池之Executors、ExecutorCompletionService工具类
前言 前面介绍了Java并发包提供的三种线程池,它们用处各不相同,接下来介绍一些工具类,对这三种线程池的使用. Executors Executors是JDK1.5就开始存在是一个线程池工具类,它定义 ...
- Java并发包线程池之ForkJoinPool即ForkJoin框架(一)
前言 这是Java并发包提供的最后一个线程池实现,也是最复杂的一个线程池.针对这一部分的代码太复杂,由于目前理解有限,只做简单介绍.通常大家说的Fork/Join框架其实就是指由ForkJoinPoo ...
- Java并发包同步工具之Exchanger
前言 承接上文Java并发包同步工具之Phaser,讲述了同步工具Phaser之后,搬家博客到博客园了,接着未完成的Java并发包源码探索,接下来是Java并发包提供的最后一个同步工具Exchange ...
- Java并发编程(您不知道的线程池操作), 最受欢迎的 8 位 Java 大师,Java并发包中的同步队列SynchronousQueue实现原理
Java_并发编程培训 java并发程序设计教程 JUC Exchanger 一.概述 Exchanger 可以在对中对元素进行配对和交换的线程的同步点.每个线程将条目上的某个方法呈现给 exchan ...
- Java多线程之并发包,并发队列
目录 1 并发包 1.1同步容器类 1.1.1Vector与ArrayList区别 1.1.2HasTable与HasMap 1.1.3 synchronizedMap 1.1.4 Concurren ...
随机推荐
- LeetCode60. 第k个排列
解法一:用next_permutation()函数,要求第k个排列,就从"123...n"开始调用 k - 1 次 next_permutation()函数即可. class So ...
- FreeMarkerz在List中取任意一条数据的某一个值
首先你要知道要取的数据的下标 <#list itemsList as item> <#if item_index==1> <#if "${item.value} ...
- 缓存数据库之redis
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题 N ...
- 什么是DevOps?该如何正确的在企业内进行实践
传统IT技术团队中通常都有多个独立的组织-开发团队.测试团队和运维团队.开发团队进行软件开发.测试团队进行软件测试,运维团队致力于部署,负载平衡和发布管理. 他们之间的职能有时重叠.有时依赖.有时候会 ...
- TJOI2013 奖学金—大根堆实现(洛谷P3963)
奖学金 题目描述 小张学院有 \(c\) 名学生,第 \(i\) 名学生的成绩为 \(ai\) ,要获得的奖学金金额为 \(bi\) . 要从这 \(c\) 名学生中挑出 \(n\) 名学生发奖学金 ...
- 通过源码学习@functools.lru_cache
一.前言 通常在一些代码中包含了重复运算,而这些重复运算会大大增加代码运行所耗费的时间,比如使用递归实现斐波那契数列. 举个例子,当求 fibonacci(5) 时,需要求得 fibonacci(3) ...
- SpringCloud组件的停更和替换说明
SpringCloud的Hoxton版本,和之前的版本相比,用新的组件替换掉了原来大部分的组件,老的组件现在处于 停更不停用 的状况. 详情见下图(× 的表示之前的组件,现在停更了的:√ 的表示新的替 ...
- JVM(完成度95%,不断更新)
一.HotSpot HotSpot是最新的虚拟机,替代了JIT,提高Java的运行性能.Java原先是将源代码编译为字节码在虚拟机运行,HotSpot将常用的部分代码编译为本地代码. 对象创建过程 类 ...
- web 部署专题(四):压力测试(二)压力测试实例 flask 四种wsgi方式对比(tornado,Gunicorn,Twisted,Gevent)
使用工具:siege 代码结构: hello.py templates |--hello.html hello.py代码: from flask import Flask, render_templa ...
- 数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定
数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 目录 数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 需求1:对茅台股票分析 需求2 ...