Hive Hooks介绍
Hive作为SQL on Hadoop最稳定、应用最广泛的查询引擎被大家所熟知。但是由于基于MapReduce,查询执行速度太慢而逐步引入其他的近实时查询引擎如Presto等。值得关注的是Hive目前支持MapReduce、Tez和Spark三种执行引擎,同时Hive3也会支持联邦数据查询的功能。所以Hive还是有很大进步的空间的。
当然,诸如SparkSQL和Presto有着他们非常合适的应用场景,我们的底层也是会有多种查询引擎存在,以应对不同业务场景的数据查询服务。但是由于查询引擎过多也会导致用户使用体验不好,需要用户掌握多种查询引擎,而且要明确知道各个引擎的适用场景。而且多种SQL引擎各自提供服务会对数据仓库建设过程中的血缘管理、权限管理、资源利用都带来较大的困难。
之前对于底层平台的统一SQL服务有考虑过在上层提供一层接口封装,进行SQL校验、血缘管理、引擎推荐、查询分发等等,但是各个引擎之间的语法差异较大,想要实现兼容的SQL层有点不太现实。最近看了快手分享的《SQL on Hadoop 在快手大数据平台的实践与优化》,觉得有那么点意思。大家有兴趣的话可以看一看。
其实快手的实现核心逻辑是一样的,有一个统一的SQL入口,提供SQL校验,SQL存储、引擎推荐、查询分发进而实现血缘管理等。优秀的是它基于Hive完成了上述工作,将Hive作为统一的入口而不是重新包装一层。既利用了HiveServer2的架构,又做到了对于用户的感知最小。而实现这些功能的基础就是Hive Hooks,也就是本篇的重点。
Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,无需重新编译Hive。所以Hive Hook提供了使用hive扩展和集成外部功能的能力。 我们可以通过Hive Hooks在查询处理的各个步骤中运行/注入一些代码,帮助我们实现想要实现的功能。
根据钩子的类型,它可以在查询处理期间的不同点调用:
Pre-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之前调用。
Post-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之后调用。
Pre-driver-run hooks:在driver执行查询之前调用。
Post-driver-run hooks:在driver执行查询之后调用。
Pre-execution hooks:在执行引擎执行查询之前调用。请注意,这个目的是此时已经为Hive准备了一个优化的查询计划。
Post-execution hooks:在查询执行完成之后以及将结果返回给用户之前调用。
Failure-execution hooks:当查询执行失败时调用。
由以上的Hive Hooks我们都可以得出Hive SQL执行的生命周期了,而Hive Hooks则完整的贯穿了Hive查询的整个生命周期。
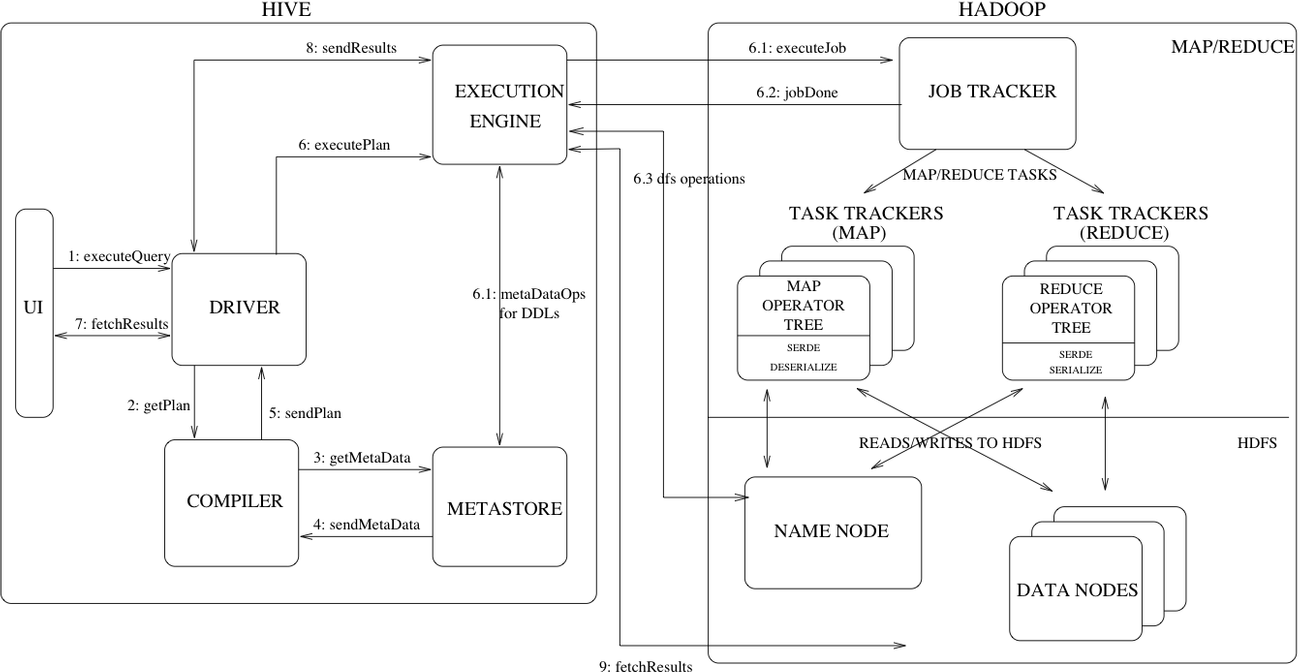
对于Hive Hooks有了初步理解之后,后面我们会通过示例介绍如何实现一个Hive Hook,并且尝试一下如何基于Hive实现统一的SQL查询服务。
Hive Hooks介绍的更多相关文章
- Hive 接口介绍(Web UI/JDBC)
Hive 接口介绍(Web UI/JDBC) 实验简介 本次实验学习 Hive 的两种接口:Web UI 以及 JDBC. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanl ...
- Hive QL 介绍
小结 本次课程学习了 Hive QL 基本语法和操作. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的 ...
- Hive权限介绍
一.开启权限 眼下hive支持简单的权限管理,默认情况下是不开启.这样全部的用户都具有同样的权限.同一时候也是超级管理员.也就对hive中的全部表都有查看和修改的权利,这样是不符合一般数据仓库的安全原 ...
- Hive体系结构介绍
http://www.aboutyun.com/thread-6217-1-1.html 1.Hive架构与基本组成 下面是Hive的架构图. 图1.1 Hive体系结构 Hive ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive 体系结构介绍
下面是Hive的架构图. 图1.1 Hive体系结构 Hive的体系结构可以分为以下几部分: (1)用户接口主要有三个:CLI,Client 和 WUI.其中最常用的是CLI,Cli启动的时候,会同时 ...
- Hive入门笔记---1.Hive简单介绍
1. Hive是什么 Hive是基于Hadoop的数据仓库解决方案.由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性.这是来自官方的解 ...
- Hive基本介绍
4.1 基本介绍: Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学 ...
- Hive函数介绍
一些函数不太会,查了些资料,分享一下 Hive已定义函数介绍: 1.字符串长度函数:length 语法: length(string A)返回值: int举例:[sql] view plain cop ...
随机推荐
- Arduion学习(三)驱动温度传感器
一.实验目的: 1.将温度值打印显示在串口监视器 1.将温度值打印显示在串口,不同温度段显示不同的灯光,并在温度过高或过低时利用蜂鸣器报警. 二.实验准备: 1.查阅相关资料,了解本次实验所用到的引脚 ...
- mq存储文件
存储文件 启动broker之后我们可以看到下面这些文件 1.config包含了运行期间一些配置信息,主要包括下列信息. consumerFilter.json:主体消息过滤信息 consumerOff ...
- qsort的cmp函数理解
qsort使用 近期频繁使用qsort函数,但是对于cmp函数却一直不太熟悉,现用现查.故写一篇小笔记记录一下. 函数原型: void qsort(void *base,size_t NumEle,s ...
- 区块链V1版本实现之五
代码重构: block.go文件: package main import ( "crypto/sha256" ) //定义区块结构 type Block struct { //前 ...
- for循环与while循环
1.两中循环的语法结构 for循环结构: for(表达式1;表达式2;表达式3) { 执行语句; } while循环结构: while(表达式1) { 执行语句; } 2.两者区别: 应用场景:由于f ...
- Toolbar+DrawerLayout+NavigationView的使用
http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2015/0303/2522.html(转载) Toolbar介绍 ActionBar由于其 ...
- kafka监听出现的问题,解决和剖析
问题如下: kafka为什么监听不到数据 kafka为什么会有重复数据发送 kafka数据重复如何解决 为什么kafka会出现俩个消费端都可以消费问题 kafka监听配置文件 一. 解决问题一(kaf ...
- 自动化运维工具之Puppet变量、正则表达式、流程控制、类和模板
前文我们了解了puppet的file.exec.cron.notify这四种核心资源类型的使用以及资源见定义通知/订阅关系,回顾请参考https://www.cnblogs.com/qiuhom-18 ...
- 记一次MySQL出现Waiting for table metadata lock的原因、排查过程与解决方法
任务背景:将sql文件通过shell直接导入到mysql中执行(还原) bug表现:导入后java项目卡死 过程: 1.网上乱搜一通,无意间看到一篇文章,这篇文章说明了如何开启mysql的genera ...
- 在Python中使用moviepy进行音视频剪辑混音合成时输出文件无声音问题
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在使用moviepy进行音视频剪辑时发现输出成功但 ...