3.MongoDB恢复探究:为什么oplogReplay参数只设置了日志应用结束时间oplogLimit,而没有设置开始时间?
(一)问题
在使用MySQL数据库binlog日志基于时间点恢复数据库时,我们必须要指定binlog的开始位置和结束位置,而在MongoDB里面,如果使用oplog进行恢复,只有oplogLimit参数,该参数信息如下
--oplogLimit=<seconds>[:ordinal] only include oplog entries before the provided Timestamp
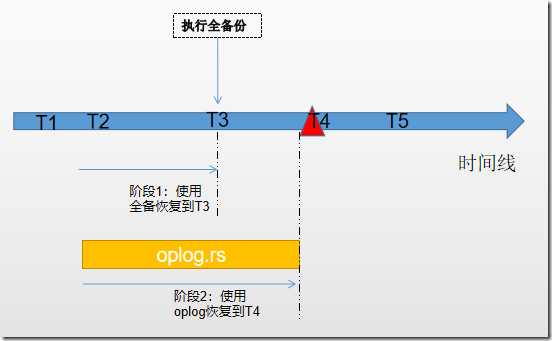
oplogLimit参数定义了数据库恢复到该时间点。也就是说,MongoDB只是设置了oplog的结束位置,没有指定oplog的开始位置。那么就存在问题了,以下图为例,我在T3时刻执行了全备份,在T4时刻数据库发生了误操作,当我执行恢复的时候,分为2个步骤:
- 阶段1:使用之前的完全备份,将数据库恢复到T3时刻;
- 阶段2:使用oplog日志,将数据库恢复到T4故障之前。T4故障之前的时间点由参数oplogLimit控制,但是:oplog的开始时间不是从T3时刻开始的,而是T2时刻开始的,这里T2是oplog记录的最早时间,该时间并不受我们控制。
补充:这里的“不受我们控制”是指在使用mongorestore重做oplog的时候,我们没办法指定开始时间。但是如果想要把oplog的开始时间控制在T3时刻,还是有办法的:使用bsondump分析全备的最后一笔数据,在备份oplog的时候,用query选项过滤掉之前的数据即可。然而,这并不是我们关心的,我所关心的,是为什么mongorestore不指定开始时间。
说了那么多,把问题明确一下:
mongorestore在恢复oplog的时候,只限定了日志的结束位置,而没有开始位置,这样就会造成oplog恢复的开始位置不是T3,而是在T2,那么就会存在T2~T3这段时间数据重复操作的问题,理论上会造成数据变化,为什么mongorestore不设定一个开始时间参数去避免重复操作的问题呢?
(二)问题探索
(2.1)oplog日志格式解析
既然该问题可能会发生在重做oplog时,那么我们不妨先看一下oplog到底存储了什么信息。为了查看oplog日志保存了什么信息,向test集合中插入1条数据:
db.test.insert({"empno":1,"ename":"lijiaman","age":22,"address":"yunnan,kungming"});
查看test集合的数据信息
db.test.find()
/* 1 */
{
"_id" : ObjectId("5f30eb58bcefe5270574cd54"),
"empno" : 1.0,
"ename" : "lijiaman",
"age" : 22.0,
"address" : "yunnan,kungming"
}
使用下面查询语句查看oplog日志信息:
use local db.oplog.rs.find( { $and : [ {"ns" : "testdb.test"} ] } ).sort({ts:1})
结果如下:
/* 1 */
{
"ts" : Timestamp(1597070283, 1),
"op" : "i",
"ns" : "lijiamandb.test",
"o" : {
"_id" : ObjectId("5f30eb58bcefe5270574cd54"),
"empno" : 1.0,
"ename" : "lijiaman",
"age" : 22.0,
"address" : "yunnan,kungming"
}
}
oplog中各个字段的含义:
- ts:数据写的时间,括号里面第1位数据代表时间戳,是自unix纪元以来的秒值,第2位代表在1s内订购时间戳的序列数
- op:操作类型,可选参数有:
-- "i": insert
--"u": update
--"d": delete
--"c": db cmd
--"db":声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.')
--"n": no op,即空操作,其会定期执行以确保时效性
- ns:命名空间,通常是具体的集合
- o:具体的写入信息
- o2: 在执行更新操作时的where条件,仅限于update时才有该属性
(2.2)文档中的“_id”字段
在上面的插入文档中,我们发现每插入一个文档,都会伴随着产生一个“_id”字段,该字段是一个object类型,对于“_id”,需要知道:
- "_id"是集合文档的主键,每个文档(即每行记录)都有一个唯一的"_id"值
- "_id"会自动生成,也可以手动指定,但是必须唯一且非空。
经过测试,发现在执行文档的DML操作时,会根据ID进行,我们不妨来看看DML操作的文档变化。
(1)插入文档,查看文档信息与oplog信息
use testdb //插入文档
db.mycol.insert({id:1,name:"a"})
db.mycol.insert({id:2,name:"b"})
db.mycol.insert({id:3,name:"c"})
db.mycol.insert({id:4,name:"d"})
db.mycol.insert({id:5,name:"e"})
db.mycol.insert({id:6,name:"f"}) rstest:PRIMARY> db.mycol.find()
{ "_id" : ObjectId("5f3b471a6530eb8aa5bf88a0"), "id" : 1, "name" : "a" }
{ "_id" : ObjectId("5f3b471a6530eb8aa5bf88a1"), "id" : 2, "name" : "b" }
{ "_id" : ObjectId("5f3b471a6530eb8aa5bf88a2"), "id" : 3, "name" : "c" }
{ "_id" : ObjectId("5f3b471a6530eb8aa5bf88a3"), "id" : 4, "name" : "d" }
{ "_id" : ObjectId("5f3b471a6530eb8aa5bf88a4"), "id" : 5, "name" : "e" }
{ "_id" : ObjectId("5f3b471b6530eb8aa5bf88a5"), "id" : 6, "name" : "f" }
这里记录该集合文档的变化,可以发现,mongodb为每条数据都分配了一个唯一且非空的”_id”:

此时查看oplog,如下
/* 1 */
{
"ts" : Timestamp(1597720346, 2),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "i",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"wall" : ISODate("2020-08-18T03:12:26.231Z"),
"o" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a0"),
"id" : 1.0,
"name" : "a"
}
} /* 2 */
{
"ts" : Timestamp(1597720346, 3),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "i",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"wall" : ISODate("2020-08-18T03:12:26.246Z"),
"o" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a1"),
"id" : 2.0,
"name" : "b"
}
} ... 略 ...
(2)更新操作
rstest:PRIMARY> db.mycol.update({"id":1},{$set:{"name":"aa"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
这里更新了1行数据,可以看到,文档id是没有发生变化的
此时查看oplog,如下:
/* 7 */
{
"ts" : Timestamp(1597720412, 1),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a0")
},
"wall" : ISODate("2020-08-18T03:13:32.649Z"),
"o" : {
"$v" : 1,
"$set" : {
"name" : "aa"
}
}
}
这里值得我们注意:上面我们说到,oplog的”o2”参数是更新的where条件,我们在执行更新的时候,指定的where条件是”id=1”,id是我们自己定义的列,然而,在oplog里面指定的where条件是
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a0"),很明显,他们都指向了同一条数据。这样,当我们使用oplog进行数据恢复的时候,直接根据”_id”去做数据更新,即使再执行N遍,也不会导致数据更新出错。
(3)再次更新操作
上面我们是对某一条数据进行更新,并且在update中指出了更新后的数据,这里再测试一下,我使用自增的方式更新数据。每条数据的id在当前的基础上加10
rstest:PRIMARY> db.mycol.update({},{$inc:{"id":10}},{multi:true})
WriteResult({ "nMatched" : 6, "nUpserted" : 0, "nModified" : 6 })
数据变化如图,可以看到,id虽然发生了变化,但是”_id”是没有改变的。

再来看oplog信息
/* 8 */
{
"ts" : Timestamp(1597720424, 1),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a0")
},
"wall" : ISODate("2020-08-18T03:13:44.398Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 11.0
}
}
} /* 9 */
{
"ts" : Timestamp(1597720424, 2),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a1")
},
"wall" : ISODate("2020-08-18T03:13:44.399Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 12.0
}
}
} /* 10 */
{
"ts" : Timestamp(1597720424, 3),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a2")
},
"wall" : ISODate("2020-08-18T03:13:44.399Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 13.0
}
}
} /* 11 */
{
"ts" : Timestamp(1597720424, 4),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a3")
},
"wall" : ISODate("2020-08-18T03:13:44.400Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 14.0
}
}
} /* 12 */
{
"ts" : Timestamp(1597720424, 5),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a4")
},
"wall" : ISODate("2020-08-18T03:13:44.400Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 15.0
}
}
} /* 13 */
{
"ts" : Timestamp(1597720424, 6),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "u",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"o2" : {
"_id" : ObjectId("5f3b471b6530eb8aa5bf88a5")
},
"wall" : ISODate("2020-08-18T03:13:44.400Z"),
"o" : {
"$v" : 1,
"$set" : {
"id" : 16.0
}
}
}
这里也值得我们注意:o2记录的是已经发生更改的文档_id,o就比较有意思了,记录的是发生变更之后的值。我们可以发现,如果我们把上面自增更新的SQL执行每执行1次,id都会加10,但是,我们重复执行N次oplog,并不会改变该条记录的值。
(4)再来看看删除操作
rstest:PRIMARY> db.mycol.remove({"id":{"$gt":14}})
WriteResult({ "nRemoved" : 2 })
数据变化如下图:

再来看看oplog日志:
/* 14 */
{
"ts" : Timestamp(1597720485, 1),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "d",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"wall" : ISODate("2020-08-18T03:14:45.511Z"),
"o" : {
"_id" : ObjectId("5f3b471a6530eb8aa5bf88a4")
}
} /* 15 */
{
"ts" : Timestamp(1597720485, 2),
"t" : NumberLong(11),
"h" : NumberLong(0),
"v" : 2,
"op" : "d",
"ns" : "testdb.mycol",
"ui" : UUID("56c4e1ad-4a15-44ca-96c8-3b3b5be29616"),
"wall" : ISODate("2020-08-18T03:14:45.511Z"),
"o" : {
"_id" : ObjectId("5f3b471b6530eb8aa5bf88a5")
}
}
”op”:”d”选项记录了该操作是执行删除,具体删除什么数据,由o选项记录,可以看到,记录的是”_id”,可以看到,删除操作是根据”_id”执行的。
(三)结论
可以看到,在DML操作数据库时,oplog时基于"_id"记录文档变化的。那么,我们来总结一下开头提出的问题:未指定开始时间,oplog数据是否会重复操作呢?
- 如果当前数据库已经存在相同id的数据,那么不会执行二次插入,主键冲突报错;
- 在做更新时,记录的是更新文档的"_id"以及发生变更后的数据,因此,如果再次执行,只会修改该条数据,哪怕执行N遍,效果也和执行一遍是一样的,所有也就不怕重复操作单条数据了;
- 在执行删除操作时,记录的是删除的文档"_id",同样,执行N遍和执行一遍效果是一样的,因为”_id”是唯一的。
因此,即使oplog从完全备份之前开始应用,也不会造成数据的多次变更。
【完】
|
相关文档: 1.MongoDB 2.7主从复制(master –> slave)环境基于时间点的恢复 3.MongoDB恢复探究:为什么oplogReplay参数只设置了日志应用结束时间oplogLimit,而没有设置开始时间? |
3.MongoDB恢复探究:为什么oplogReplay参数只设置了日志应用结束时间oplogLimit,而没有设置开始时间?的更多相关文章
- mongodb write 【摘自网上,只为记录,学习】
mongodb有一个write concern的设置,作用是保障write operation的可靠性.一般是在client driver里设置的,和db.getLastError()方法关系很大 一 ...
- Python装饰器探究——装饰器参数
Table of Contents 1. 探究装饰器参数 1.1. 编写传参的装饰器 1.2. 理解传参的装饰器 1.3. 传参和不传参的兼容 2. 参考资料 探究装饰器参数 编写传参的装饰器 通常我 ...
- Oracle恢复ORA-00600: 内部错误代码, 参数: [kcratr_scan_lastbwr] 问题的简单解决
Oracle恢复ORA-00600: 内部错误代码, 参数: [kcratr_scan_lastbwr] 1. 简单处理 sqlplus / as sysdba startup mount recov ...
- 居然还有WM_TIMECHANGE(只在用户手动改变系统时间时才会产生作用)
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- mongoDB之监控工具mongostat及其参数的具体含义
mongostat是mongdb自带的状态检测工具,在命令行下使用.它会间隔固定时间获取mongodb的当前运行状态,并输出.如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mon ...
- Spring data mongodb @CreatedBy@LastModifiedBy@CreatedBy@LastModifiedBy SpringSecurityAuditorAware,只记录用户名
要在Spring data mongodb 中使用@CreatedBy@LastModifiedBy@CreatedBy@LastModifiedBy 这四个注解 必须实现 SpringSecuri ...
- Tomcat参数调优包括日志、线程数、内存【转】
[Tomcat中日志打印对性能测试的影响] 一般都提供了这样5个日志级别: ▪ Debug ▪ Info ▪ Warn ▪ Error ▪ Fatal 由于性能测试需要并发进行压力测试,如果日志级别是 ...
- log4j2用Log4jContextSelector启动参数配置全局异步日志是如何使用disruptor
与 log4j2用asyncRoot配置异步日志是如何使用disruptor差异有几个: 给disruptor实例的EventFactory不同 此处EventFactory采用的是RingBuffe ...
- log4j配置参数详解——按日志文件大小、日期切分日志文件
项目中尽管对log4j有基本的配置,例如按天生成日志文件以作区分,但如果系统日志文件过大,则就需要考虑以更小的单位切分或者其他切分方式.下面就总结一下log4j常用的配置参数以及切分日志的不同方式. ...
随机推荐
- 怎么理解Python迭代器与生成器?
怎么理解Python迭代器与生成器?在Python中,使用for ... in ... 可以对list.tuple.set和dict数据类型进行迭代,可以把所有数据都过滤出来.如下: ...
- jenkins集群(二)(master --> slave) -- allure自动化测试报告部署
一.前提 1.环境 1)已经部署好了jenkins环境,包括jenkins的“全局工具配置”也配好了. 2.master与slave的简单的概念 1)master:jenkins部署所在的机器 2)s ...
- pdb 进行调试
import pdb a = 'aaa' pdb.set_trace( ) b = 'bbb' c = 'ccc' final = a+b+c print(final) import pdb a = ...
- 女生学Java编程是什么感受?
那我就代表女生来说说感受 在编程的世界很难遇到好看的帅哥 记得当年15年7月4号是我实习生入职的日子,因为是校企合作,所以没有面试.老师推荐.直接入职.刚来北京第一个感觉就是人多,还有就是热.刚到公司 ...
- PHP array_diff_key() 函数
实例 比较两个数组的键名,并返回差集: <?php $a1=array("a"=>"red","b"=>"gre ...
- Python File flush() 方法
概述 flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入.高佣联盟 www.cgewang.com 一般情况下,文件关闭后会自动刷 ...
- Python List cmp()方法
描述 cmp() 方法用于比较两个列表的元素.高佣联盟 www.cgewang.com 语法 cmp()方法语法: cmp(list1, list2) 参数 list1 -- 比较的列表. list2 ...
- PHP preg_match_all() 函数
preg_match_all 函数用于执行一个全局正则表达式匹配.高佣联盟 www.cgewang.com 语法 int preg_match_all ( string $pattern , stri ...
- C/C++编程笔记:C++入门知识丨继承和派生
本篇要学习的内容和知识结构概览 继承和派生的概念 派生 通过特殊化已有的类来建立新类的过程, 叫做”类的派生”, 原有的类叫做”基类”, 新建立的类叫做”派生类”. 从类的成员角度看, 派生类自动地将 ...
- 为什么overflow:hidden能达到清除浮动的目的?
1. 什么是浮动 <精通CSS>(第3版)关于浮动的描述: 浮动盒子可以向左或向右移动,直到其外边沿接触包含块的外边沿,或接触另一个浮动盒子的外边沿. 浮动盒子也会脱离常规文档流,因此常规 ...