Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据!
那我们应该怎么办呢???
思路是这样的:F12,查看网络,筛选XHR,点击下拉菜单,等待异步加载的文件 ,得到异步加载url,在通过这个url请求得到我们想要的数据。
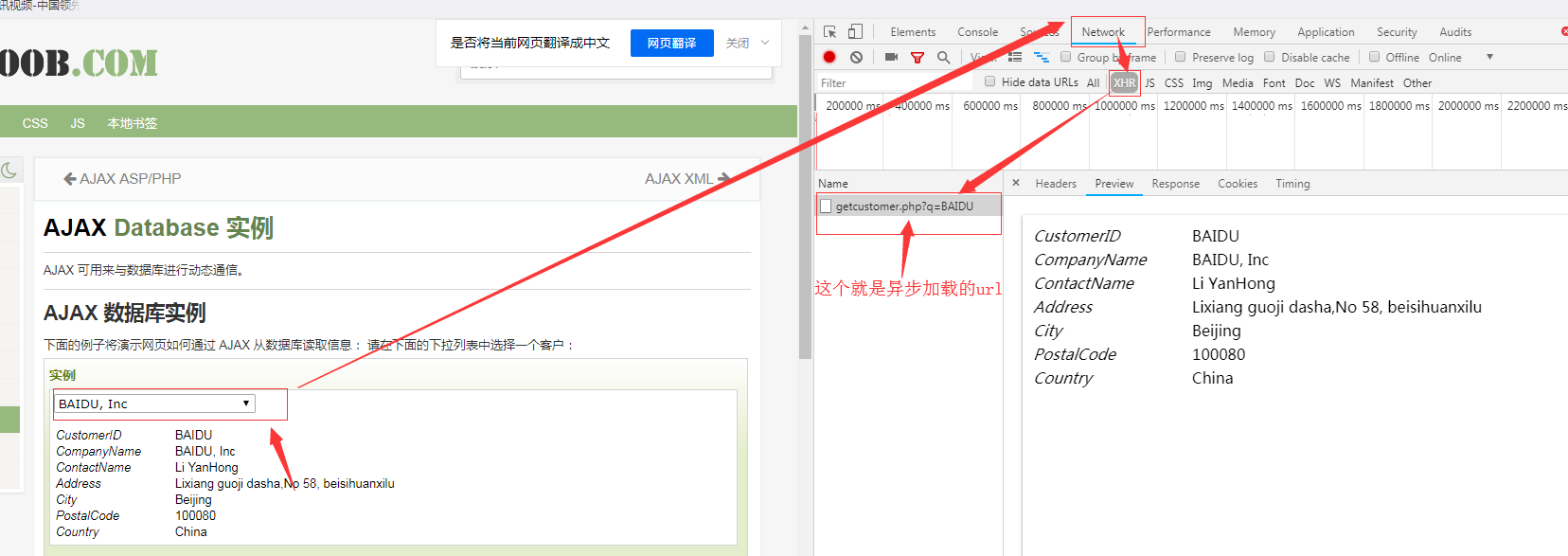
以下为实战代码,可以供大家参考。
import requests
from lxml import etree
# 浏览器伪装
ua = 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko'
header = {"User-Agent": ua}
# GET请求
url = 'http://www.runoob.com/ajax/ajax-database.html'
r = requests.get(url, headers=header)
r.encoding = 'urf-8'
text = r.text
# xpath提取信息
element = etree.HTML(text)
options = element.xpath('/html/body/div[3]/div/div[2]/div/div[3]/div/div[1]/div/form/select/option/@value')
print(options)
# 提取异步加载的信息
for option in options:
url = 'http://www.runoob.com/try/ajax/getcustomer.php?q='+option.strip()
r = requests.get(url, headers=header)
r.encoding = 'GBK'
text = r.text
# xpath提取信息
element = etree.HTML(text)
em = element.xpath('/html/body/table/tr[1]/td[1]/em/text()')
td = element.xpath('/html/body/table/tr[1]/td[2]/text()')
for e, t in zip(em, td):
print(e, ' | ', t)
print('-' * 55, options.index(option) + 1)
希望能够帮到有需要的朋友。(如果没有安装requests和lxml 模块的话,需要在命令行pip install request、pip install lxml,不然会报错)
Python 爬取异步加载的数据的更多相关文章
- Python爬虫爬取异步加载的数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:努力努力再努力 爬取qq音乐歌手数据接口数据 https://y.qq ...
- Jsoup配合 htmlunit 爬取异步加载的网页
加入 jsoup 和 htmlunit 的依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId&g ...
- 关于python爬取异步ajax数据的一些见解
我们在利用python进行爬取数据的时候,一定会遇到这样的情况,在浏览器中打开能开到所有数据,但是利用requests去爬取源码得到的却是没有数据的页面框架. 出现这样情况,是因为别人网页使用了aja ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- Android-LoaderManager异步加载数据库数据
LoaderManager异步加载数据库数据,是在(Activity/fragment/其他UI等) 加载大量的本地Database库表数据,由于数据大在加载过程中会导致UI线程阻塞,导致用户体验不好 ...
- ztree插件的使用及列表项拖拽的实现(jQuery)+异步加载节点数据
为了实现如图所示的树状结构图,并使列表项可拖动到盒子里,研究了ztree这个插件的使用,并仔细研究了列表项的拖动事件.完成了预期需求,对jQuery的运用得到了提高.这个插件的功能非常强大,除了基本的 ...
随机推荐
- 从零开始的Spring Boot(5、Spring Boot整合Thymeleaf)
Spring Boot整合Thymeleaf 写在前面 从零开始的Spring Boot(4.Spring Boot整合JSP和Freemarker) https://www.cnblogs.com/ ...
- Oracle SQL调优系列之SQL Monitor Report
@ 目录 1.SQL Monitor简介 2.捕捉sql的前提 3.SQL Monitor 参数设置 4.SQL Monitor Report 4.1.SQL_ID获取 4.2.Text文本格式 4. ...
- chromedp入门
chromedp入门 chromedp是什么? chromedp是go写的,支持Chrome DevTools Protocol 的一个驱动浏览器的库.并且它不需要依赖其他的外界服务(比如 Selen ...
- 黎活明8天快速掌握android视频教程--25_网络通信之资讯客户端
1 该项目的主要功能是:后台通过xml或者json格式返回后台的视频资讯,然后Android客户端界面显示出来 首先后台新建立一个java web后台 采用mvc的框架 所以的servlet都放在se ...
- trollcave解题
这是第一次完整地进行模拟渗透,前前后后一共花了一天时间,花了点时间写了个writeup. 博主是个菜鸡,如果有大神看到,请轻喷...... writeup下载:https://hrbeueducn-m ...
- Spark HA搭建
正文 下载Spark版本,这版本又要求必须和jdk与hadoop版本对应. http://spark.apache.org/downloads.html tar -zxvf 解压到指定目录,进入con ...
- MongoDB快速入门教程 (4.4)
4.5.Mongoose索引和方法 4.5.1.设置索引 let UserSchema = mongoose.Schema({ sn: { type: Number, // 设置唯一索引 unique ...
- linux下安装jdk并设置环境变量
首先去官网下载jdk安装包 我这里下载的是jdk7,因为jdk8之后做了很大的改动,所以现在常用的还是jdk7.下载地址:www.oracle.com/technetwork/cn/java/ja ...
- 洛谷 P2648 赚钱
这道题其实就是求最长路顺便再判断一下正环而已. 这种题肯定要用SPFA的啦,有又正边权(因为最长路所以正边就相当于负边),又是正环(同理,相当于负环),SPFA专治这种问题. 当一个点入队多次的时候, ...
- For setting NODE_ENV you can use any of these methods.
method 1: set NODE_ENV for all node apps Windows: set NODE_ENV=production Linux or other Unix based ...