Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里
一、存储机制
1、基础描述
NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据时,修改内存中的元数据会把操作记录追加到edits日志文件中,这里不包括查询操作。如果NameNode节点发生故障,可以通过FsImage和Edits的合并,重新把元数据加载到内存中,此时SecondaryNameNode专门用于fsImage和edits的合并。
2、工作流程
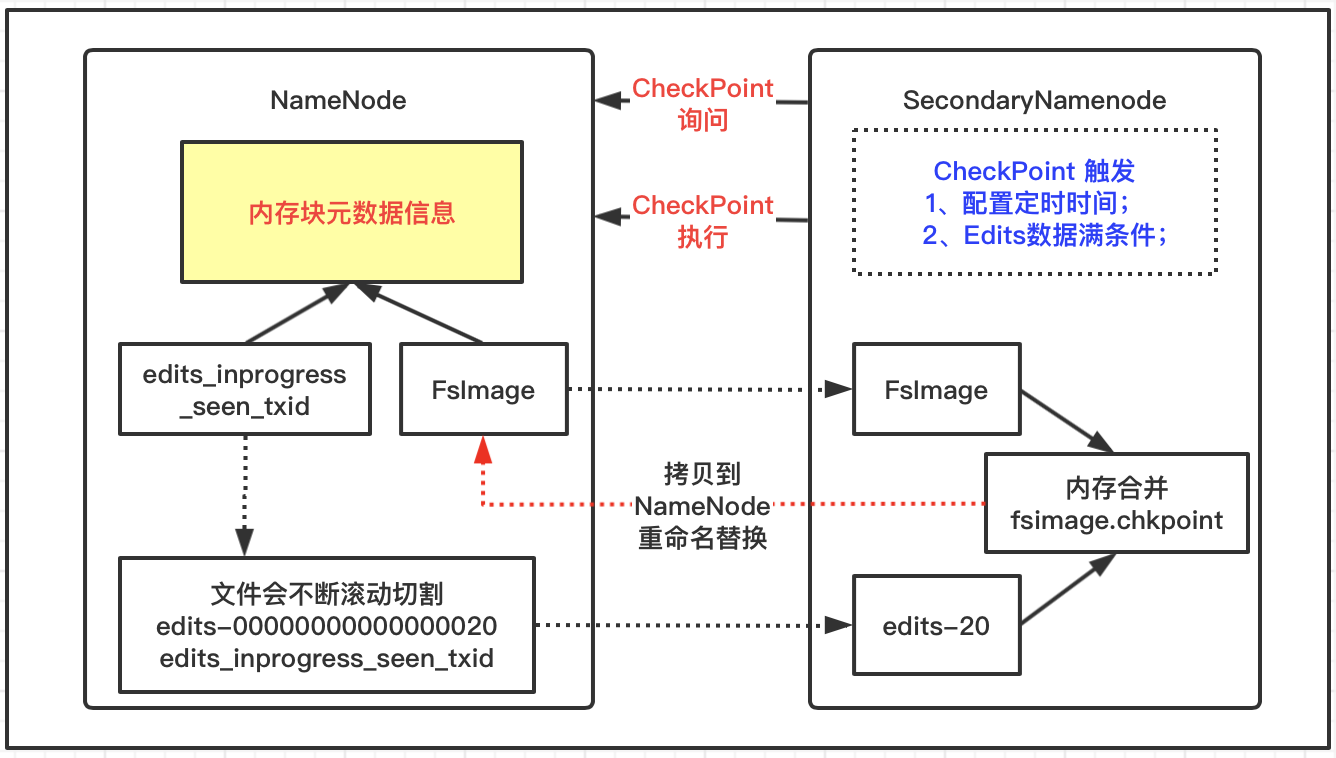
NameNode机制
- NameNode格式化启动之后,首次会创建Fsimage和Edits文件;
- 非首次启动直接加载FsImage镜像文件和Edits日志到内存中;
- 客户端对元数据执行增删改操作会记录到Edits文件;
- 然后请求的相关操作会修改内存中的元数据;
SecondaryNameNode机制
- 询问NameNode是否需要CheckPoint,NameNode返回信息;
- 如果需要SecondaryNameNode请求执行CheckPoint;
- NameNode切割现有日志文件,新记录滚动写入新Edits文件;
- 滚动前的编辑日志和镜像文件拷贝到SecondaryNameNode;
- SecondaryNameNode加载Edits日志和FsImage镜像文件到内存合并;
- 生成新的镜像文件fsimage.chkpoint后拷贝到NameNode;
- NameNode将fsimage.chkpoint重新命名成fsimage;
3、CheckPoint设置
通过修改hdfs-default.xml文件的相关配置,设置一些SecondaryNameNode的机制,例如每隔一小时执行一次。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>文件满1000000记录数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次文件记录数</description>
</property >
二、文件信息
1、FsImage文件
NameNode内存中元数据序列化备份信息;
生成路径:基于NameNode节点
cd /opt/hadoop2.7/data/tmp/dfs/name/current/
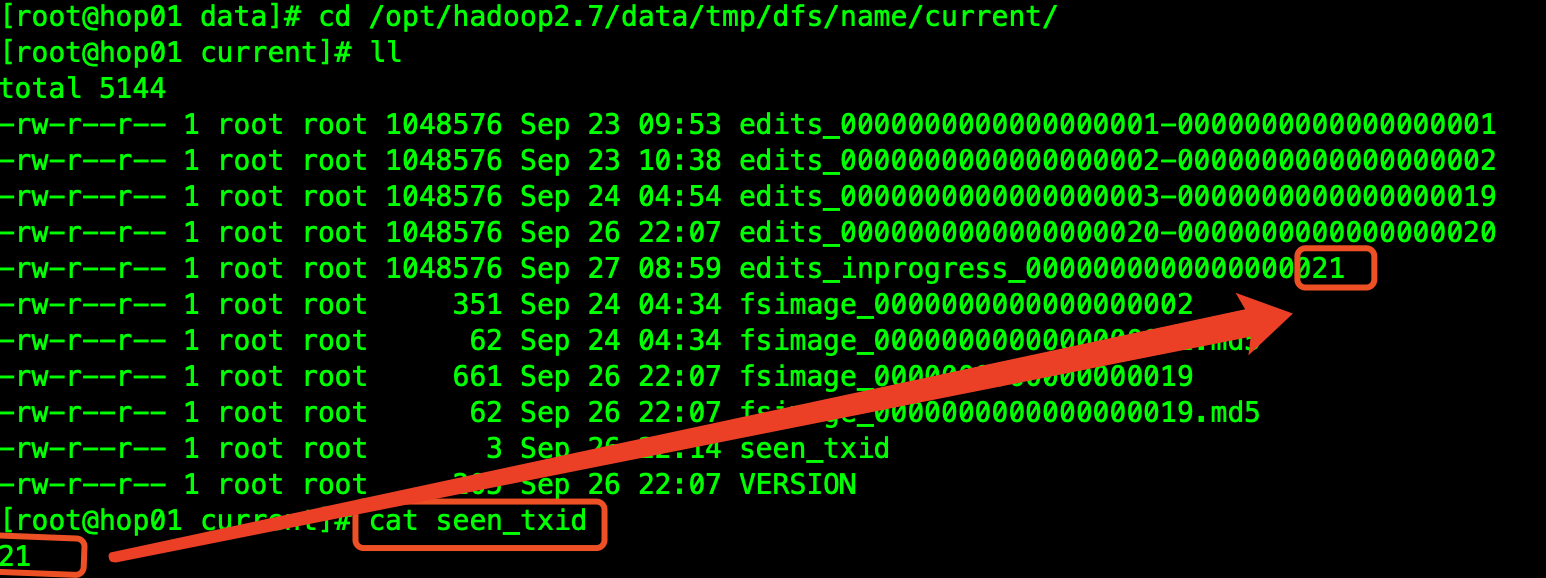
查看文件
# 基本语法
hdfs oiv -p 转换文件类型 -i 镜像文件 -o 转换后文件输出路径
基于语法格式,操作上图中的文件:
# 转换文件
hdfs oiv -p XML -i fsimage_0000000000000000019 -o /data/fsimage.xml
# 查看
cat /data/fsimage.xml
这样就可以看到一些元数据的信息。
2、Edits文件
存放HDFS文件的所有增删改操作的路径,会记录在Edits文件中。
基本语法
hdfs oev -p 转换文件类型 -i 日志文件 -o 转换后文件输出路径
查看文件
# 转换文件
hdfs oev -p XML -i edits_0000000000000000020-0000000000000000020 -o /data/edits.xml
# 查看
cat /data/edits.xml
三、故障恢复
1、拷贝SecondaryNameNode数据
首先结束NameNode进程;
删除NameNode存储的数据;
[root@hop01 /] rm -rf /opt/hadoop2.7/data/tmp/dfs/name/*
拷贝SecondaryNameNode中数据到NameNode数据存储目录下;
# 注意SecondaryNameNode服务配置在hop03上
[root@hop01 /] scp -r root@hop03:/opt/hadoop2.7/data/tmp/dfs/namesecondary/* /opt/hadoop2.7/data/tmp/dfs/name/
重新启动NameNode进程;
2、基于Checkpoint机制
修改hdfs-site.xml配置,同步到集群相关服务下,重启HDFS进程;
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop2.7/data/tmp/dfs/name</value>
</property>
结束NameNode进程;
删除NameNode存储的数据;
[root@hop01 /] rm -rf /opt/hadoop2.7/data/tmp/dfs/name/*
由于集群中SecondaryNameNode(在hop03)不和NameNode(在hop01)在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件;
[root@hop01 /]scp -r root@hop03:/opt/hadoop2.7/data/tmp/dfs/namesecondary /opt/hadoop2.7/data/tmp/dfs/
[root@hop01 namesecondary/] rm -rf in_use.lock
[root@hop01 dfs]$ ls
data name namesecondary
导入检查点数据
[root@hop01 hadoop2.7] bin/hdfs namenode -importCheckpoint
重新启动NameNode
[root@hop01 hadoop2.7] sbin/hadoop-daemon.sh start namenode
四、多个目录配置
NameNode可以配置多本地目录,每个目录存放内容相同,增加运行的可靠性;
1、添加配置
# vim /opt/hadoop2.7/etc/hadoop/hdfs-site.xml
# 添加内容如下
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name01,file:///${hadoop.tmp.dir}/dfs/name02</value>
</property>
该配置需要同步集群下所有服务;
2、删除原有数据
集群下所有服务都需要执行该操作;
[root@hop01 hadoop2.7]# rm -rf data/ logs/
格式化NameNode之后重启集群服务。
五、安全模式
1、基本描述
NameNode刚启动时,会基于镜像文件和编辑日志在内存中加载文件系统元数据的映像,然后开始监听DataNode请求,该过程期间处于一个只读的安全模式下,客户端无法上传文件,在该安全模式下DataNode会发送最新的数据块列表信息到NameNode,如果满足最小副本条件,NameNode在指定时间后就会退出安全模式。
2、安全模式
- 安全模式状态
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode get
- 进入安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode enter
- 退出安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode leave
- 等待安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode wait
六、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
推荐阅读:编程体系整理
| 序号 | 项目名称 | GitHub地址 | GitEE地址 | 推荐指数 |
|---|---|---|---|---|
| 01 | Java描述设计模式,算法,数据结构 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 02 | Java基础、并发、面向对象、Web开发 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 03 | SpringCloud微服务基础组件案例详解 | GitHub·点这里 | GitEE·点这里 | ☆☆☆ |
| 04 | SpringCloud微服务架构实战综合案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 05 | SpringBoot框架基础应用入门到进阶 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 06 | SpringBoot框架整合开发常用中间件 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 07 | 数据管理、分布式、架构设计基础案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 08 | 大数据系列、存储、组件、计算等框架 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
Hadoop框架:NameNode工作机制详解的更多相关文章
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- Session的工作机制详解和安全性问题(PHP实例讲解)
我们先简单的了解一些http的知识,从而理解该协议的无状态特性.然后,学习一些关于cookie的基本操作.最后,我会一步步阐述如何使用一些简单,高效的方法来提高你的php应用程序的安全性以及稳定行. ...
- JVM结构、GC工作机制详解
JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知,JVM主要包括四个部分 ...
- JVM结构、GC工作机制详解(转)
原文地址:http://blog.csdn.NET/tonytfjing/article/details/44278233 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JV ...
- 【转载】JVM结构、GC工作机制详解
文章主要分为以下四个部分 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知, ...
- 【系统之音】WindowManager工作机制详解
前言 目光所及,皆有Window!Window,顾名思义,窗口,它是应用与用户交互的一个窗口,我们所见到视图,都对应着一个Window.比如屏幕上方的状态栏.下方的导航栏.按音量键调出来音量控制栏.充 ...
- hadoop的Namenode HA原理详解
为什么要Namenode HA? 1. NameNode High Availability即高可用. 2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNod ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- NIO组件Selector工作机制详解(下)
转自:http://blog.csdn.net/haoel/article/details/2224069 五. 迷惑不解 : 为什么要自己消耗资源? 令人不解的是为什么我们的Java的New I/ ...
随机推荐
- 反射机制(Java)
反射机制 今天闲来无事,对反射机制http://www.cnblogs.com/jqyp/archive/2012/03/29/2423112.html阅读一番,整理了下这方面的知识以及自己的一些心得 ...
- Java远程连接Linux服务器并执行命令及上传文件
最近再开发中遇到需要将文件上传到Linux服务器上,至此整理代码笔记. 此种连接方法中有考虑到并发问题,在进行创建FTP连接的时候将每一个连接对象存放至 ThreadLocal<Ftp> ...
- 02 axios
request.js import axios from 'axios' const config = require('@/config') const instance = axios.creat ...
- Linux/Unix Terminal中文件/目录的颜色各代表什么意思?
注意:console/terminal中文件目录的颜色设置是可以更改的,故环境不同颜色就可能不一样. 下面是我所用终端的颜色示例: 颜色说明: 白色:普通文件 紫色:目录 红色:有问题的链接文件 蓝绿 ...
- 15个随机图片API
15个随机图片API 妈妈再也不用担心我网站没图用了呜 请不要重复刷新此页面 ! 找了很久的说,你难道不想收藏一下吗 其中有些 API 速度并不太好,可能会拖慢贵站的速度 我也不能保证这些 API 能 ...
- linux(centos)下密码有效期和密码复杂度设置
1.密码有效期 方法一: chage -l 用户名 查看用户的过期时间 chage -M 99999 用户名 用命令修改过期时间为永久 chage -M 90 用户名 设置密码有效期为90天 chag ...
- golang开发:CSP-WaitGroup Mutex
CSP 是 Communicating Sequential Process 的简称,中文可以叫做通信顺序进程,是一种并发编程模型,最初于Tony Hoare的1977年的论文中被描述,影响了许多编程 ...
- 简单地 Makefile 书写
注意事项 每个标签分支前都不能用空格,必须用tab 标签外调用bash命令用 $(shell -),标签内可以正常使用 标签后可以指定其他标签,执行顺序是先执行其他标签,而后在执行自己 比如 all: ...
- 第18课 - make 中的路径搜索(下)
第18课 - make 中的路径搜索(下) 1. 问题一 当 VPATH 和 vpath 同时出现,make 会如何处理? 工程项目的目录结构如下图所示,src1 和 src2 中都包含了 func. ...
- 用后台开发的逻辑理念学习VUE
前言 近些年前端开发快速发展,现在学习前端已经不像以前那样仅仅学习一个语法就可以了,它已经是一门编程技术了,它们有自己独立的类似Main函数的入口,有像MVC一样规范好的层次结构,有自己的开发工具可以 ...