吴裕雄--天生自然python学习笔记:pandas模块用 dataframe.loc 通过行、列标题读取数据
用 df.va lue s 读取数据的前提是必须知道学生及科目的位置,非常麻烦 。 而 df.loc
可直接通过行、列标题读取数据,使用起来更为方便 。
使用 df.loc 的语法为:

行标题或列标题若是包含多个项目,则用小括号将项目括起来,项目之间以逗
号分隔,如“( ” 数学 ” , ” 自然 ”) ”;若要包含所有项目,则用冒号“.”表示。
例如读取学生陈聪明的所有成绩:
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('df.loc["陈聪明", :] ->')
print(df.loc["陈聪明", :])

读取学生陈聪明的数学科目成绩 :
print('df.loc["陈聪明"]["数学"] ->')
print(df.loc["陈聪明"]["数学"])
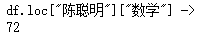
读取学生陈聪明、熊小娟的所有成绩 :
print('df.loc[("陈聪明", "熊小娟") ->')
print(df.loc[("陈聪明", "熊小娟"), :])

读取学生陈聪明、熊小娟的数学、 自然科目成绩 :
print('df.loc[:, "数学"] ->')
print(df.loc[:, "数学"])
print()
print('df.loc[("陈聪明", "熊小娟"), ("数学", "自然")] ->')
print(df.loc[("陈聪明", "熊小娟"), ("数学", "自然")])
print()

读取学生陈聪明到熊小娟的数学科目到社会科目的成绩 :
print('df.loc["陈聪明":"熊小娟", "数学":"社会"] ->')
print(df.loc["陈聪明":"熊小娟", "数学":"社会"])

读取从头到黄美丽的学生 , 及其从数学科目到社会科目 的成绩 :
print('df.loc[:黄美丽, "数学":"社会"] ->')
print(df.loc[:"黄美丽", "数学":"社会"])

读取从陈聪明到最后 的学生 ,他们 的数学科目 到社会科 目 的成绩 :
print('df.loc["陈聪明":, "数学":"社会"] ->')
print(df.loc["陈聪明":, "数学":"社会"])

用 df.iloc 通过行、列位置读取数据
df. iloc 是以行、列位置读取数据的 ,语法为 :
df. iloc 的用法与 df.loc 完全相同,只需要把 “ 标题 ” 改为“位置”即可。例如 ,
读取陈聪明(第 2 位学生〉的所有成绩 :
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('df.iloc[1, :] ->')
print(df.iloc[1, :])

读取学生陈聪明的数学(第 2 个科目)成绩 :
print('df.iloc[1][1] ->')
print(df.iloc[1][1])
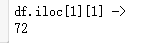
用 df.ix 通过行、列标题或行、列位置读取数据
df.ix 是 df. loc 及 df. iloc 的合体,以行、列标题或行、列位置的方式都可以读取
读取数据,语法为 :
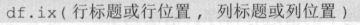
df. i x 的用法与 d f. lo c 完全相同 。 例如 , 读取陈聪明(第 2 位学生〉的数学(第 2
个科目)成绩,通过下列 4 种语法都可以实现 :
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('陈聪明的数学科成绩 ->')
print(df.ix["陈聪明"]["数学"])
print(df.ix["陈聪明"][1])
print(df.ix[1]["数学"])
print(df.ix[1][1])

读取最前面或最后面的几行数据
如果要读取最前面几行数据,可使用 head 方法,语法为:

参数 n 可有可无,表示读取最前面 n 行数据,若省略默认读取 5 行数据 。 例如,
读取最前面 2 个学生成绩(林大明及陈聪明) :
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('最前 2 位学生成绩 ->')
print(df.head(2))

若要读取最后面几行数据, 则使用 tail 方法,语法为 :

print('最后 2 位学生成绩 ->')
print(df.tail(2))

吴裕雄--天生自然python学习笔记:pandas模块用 dataframe.loc 通过行、列标题读取数据的更多相关文章
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然python学习笔记:pandas模块导入数据
有时候,手工生成 Pandas 的 DataFrame 数据是件非常麻烦的事情,所以我们通 常会先把数据保存在 Excel 或数据库中,然后再把数据导入 Pandas . 另 一种情况是抓 取网页中成 ...
- 吴裕雄--天生自然python学习笔记:pandas模块强大的数据处理套件
用 Python 进行数据分析处理,其中最炫酷的就属 Pa ndas 套件了 . 比如,如果我 们通过 Requests 及 Beautifulsoup 来抓取网页中的表格数据 , 需要进行较复 杂的 ...
- 吴裕雄--天生自然python学习笔记:pandas模块删除 DataFrame 数据
Pandas 通过 drop 函数删除 DataFrarne 数据,语法为: 例如,删除陈聪明(行标题)的成绩: import pandas as pd datas = [[65,92,78,83,7 ...
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- 吴裕雄--天生自然python学习笔记:pandas模块读取 Data Frame 数据
读取行数据 读取一个列数据的语法为: 例如,读取所有学生自然科目的成绩 : import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56 ...
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然python学习笔记:python 建立 Firebase 数据库连接
Python 程序通过 python-firebase 包可以存取 Firebase 数据库. 使用 python-firebase 包 首先必须安装 python-firebase 包,安装方法如下 ...
- 吴裕雄--天生自然python学习笔记:python下载安装各种模块的whl文件网址
python下载安装各种模块的whl文件网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
随机推荐
- linux下springboot项目通过jetty发布war包应用
Linux下jetty发布jar包 1.通过官网下载jetty点击下载https://repo1.maven.org/maven2/org/eclipse/jetty/jetty-distributi ...
- Java反射--getDeclaredField()和getField()
Field getField(String name) 返回当前类以及所继承的类的所有public修饰的成员变量 Field getDeclaredField(String name) 返 ...
- JSP页面中提示JSTL标签无法找到的错误
无法解析标签库的错误 1.应该是项目中少了jstl.jar和 standard.jar这两个jar包. 下载地址:https://www.onlinedown.net/soft/1162736.htm ...
- java中abstract怎么使用
abstract(抽象)修饰符,可以修饰类和方法 1,abstract修饰类,会使这个类成为一个抽象类,这个类将不能生成对象实例,但可以做为对象变量声明的类型,也就是编译时类型,抽象类就像当于一类的半 ...
- 吴裕雄--天生自然Linux操作系统:linux yum 命令
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器. 基於RPM包管理,能够从指定的服务器自动下载RPM包 ...
- Django专题-auto模块
Django自带的用户认证 我们在开发一个网站的时候,无可避免的需要设计实现网站的用户系统.此时我们需要实现包括用户注册.用户登录.用户认证.注销.修改密码等功能,这还真是个麻烦的事情呢. Djang ...
- linux 中的.so和.a文件
Linux下的.so是基于Linux下的动态链接,其功能和作用类似与windows下.dll文件. 下面是关于.so的介绍: 一.引言 通常情况下,对函数库的链接是放在编译时期(compile tim ...
- C语言实现整数转字符串
#include <stdio.h> void intToString(int N,char arr[]){ //仅支持有符号4字节的int类型,范围-2147483648 - 21474 ...
- 4. 监控利器nagios手把手企业级实战第三部
1.nagios图形监控显示和管理服务器 虽然能显示,能报警.但是我们企业工作中需要一个历史趋势图. nagios只开放核心,插件是单独的形式,图像也一样,是插件或者整合的方式.所以可能看起来很多,这 ...
- 1.linux系统调优
首先来说调优是一门黑色艺术,使用来满足人的感知,通过人的感觉来进行配置,达到让人感觉操作系统速度很块的感觉. 操作系统拥有四个瓶颈:cpu,内存,网络,磁盘.调优主要是对上述四个子系统进行配置优化,其 ...