MyBatis(十):Mybatis缓存的重要内容
本文是按照狂神说的教学视频学习的笔记,强力推荐,教学深入浅出一遍就懂!b站搜索狂神说或点击下面链接
https://space.bilibili.com/95256449?spm_id_from=333.788.b_765f7570696e666f.2
缓存
定义:
Cache
存在内存中的临时数据。
经常查询的数据放在缓存中,用户查询数据不去读数据库而是读缓存,从而提高查询效率。
好处:减少和数据库交互的次数,减少系统开销,提高系统效率。
限制:经常查询而且不易改变的数据才能使用缓存。
Mybatis缓存
Mybatis也有一个缓存设置,如缓存定义,Mybatis也一样:
查询过的数据会放在内存中一段时间,下次使用就直接从内存中去取
定义了两种缓存:
一级缓存。
二级缓存。
为了提高扩展性,Mybatis定义了缓存接口Cache,可以实现Cache接口来自定义二级缓存。
缓存不是一直有效的,缓存机制:
所有 select 语句的结果将会被缓存。
所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
手动清理缓存
备注:以上缓存机制官方没有明确说过是一级缓存的机制,官方只声明了这是二级缓存的默认机制,但是很多也是符合的,具体是不是还要看源码。
一级缓存
定义
也叫本地缓存,其实就是SqlSession这个连接的缓存:
从连接池获取1个SqlSession到放回连接池的这个过程中,查询到的数据会放在本地缓存中。
以后如果要获取相同的数据,直接从缓存中那,不会再查数据库
一级缓存默认是开启的,而且也关不掉。
演示
@org.junit.Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.listById(1);
System.out.println(user);
System.out.println("===================");
User user2 = mapper.listById(1);
System.out.println(user2);
System.out.println(user==user2);
}
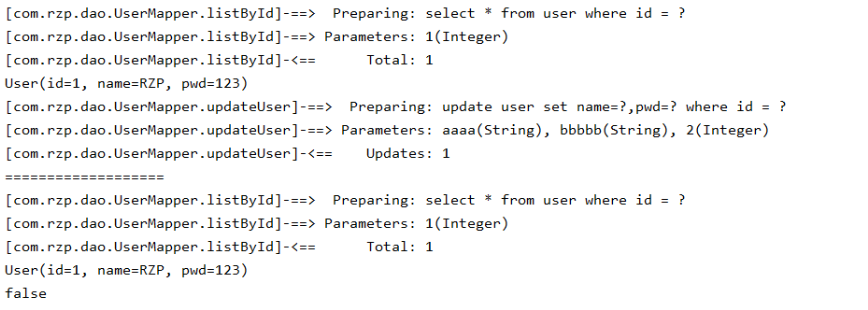
输出内容(这个输出内容要配置日志,可以看我以前的blog):
可以看到,从第一行查询语句到到最后一行释放连接,中间再没有查询语句,说明只查询了1次数据库。
而且user和user2的内存地址都是一样的(user==user2 = true)
[com.rzp.dao.UserMapper.listById]-==> Preparing: select * from user where id = ?
[com.rzp.dao.UserMapper.listById]-==> Parameters: 1(Integer)
[com.rzp.dao.UserMapper.listById]-<== Total: 1
User(id=1, name=RZP, pwd=123)
===================
User(id=1, name=RZP, pwd=123)
true
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2118cddf]
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@2118cddf]
[org.apache.ibatis.datasource.pooled.PooledDataSource]-Returned connection 555273695 to pool.
拓展
该部分内容摘自:https://blog.csdn.net/ztchun/article/details/79110096
如果想要复制对象,除了实现clonable接口,还有个简单的工具类就可以实现--PropertyUtils
User user3 =new User();
try {
PropertyUtils.copyProperties(user3,user2);
} catch (Exception e) {
e.printStackTrace();
}
sqlSession.close();
user2.setId(123312);
System.out.println(user);
System.out.println(user2);
System.out.println(user3);

需要导入依赖
<!--工具类,可以复制对象-->
<!-- https://mvnrepository.com/artifact/commons-beanutils/commons-beanutils -->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>
缓存失效:
增删改会失效缓存。(因为增删改以后数据就不一样了,显然要重新查)
@org.junit.Test
public void tes1(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.listById(1);
System.out.println(user);
mapper.updateUser(new User(2,"aaaa","bbbbb")); System.out.println("===================");
User user2 = mapper.listById(1);
System.out.println(user2);
System.out.println(user==user2);
}
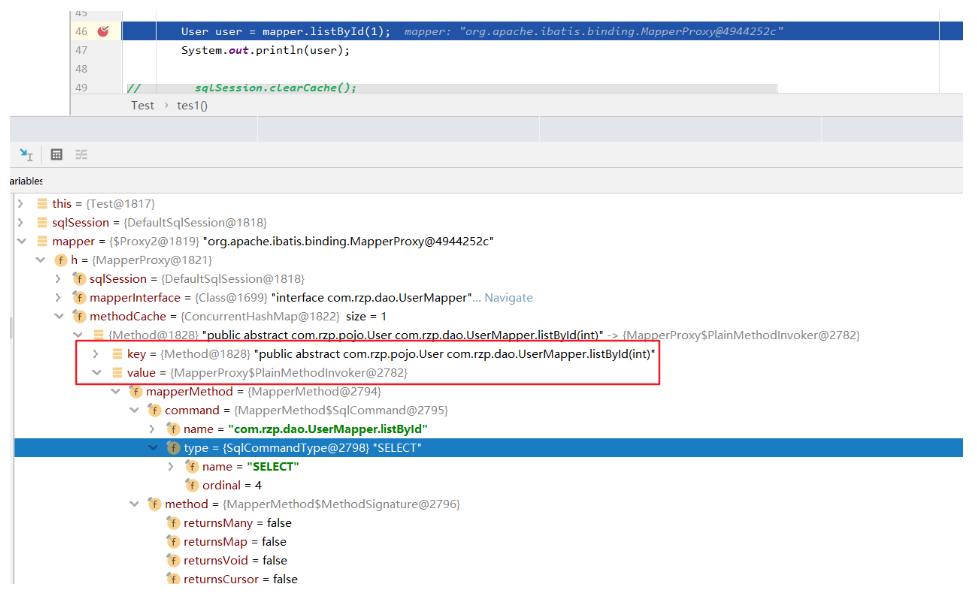
手动清理缓存
可以使用sqlSession.clearCache()方法手动清理缓存
@org.junit.Test
public void tes1(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.listById(1);
System.out.println(user);
sqlSession.clearCache();
System.out.println("===================");
User user2 = mapper.listById(1);
System.out.println(user2);
System.out.println(user==user2);
}

通过debug模式,可以看到类似map的方式存储的。
二级缓存
定义
全局缓存,一级缓存作用域太低,所以诞生了二级缓存。
基于namespace级别的缓存,一个命名空间对应一个二级缓存(其实就是1个Mapper1个缓存)
工作机制:
一个会话(SqlSession)查询一条数据,该数据放在当前会话的一级缓存种。
当前会话关闭了,该数据会保存到二级缓存种。
新的会话查询信息,就可以从二级缓存获取内容。
不同的Mapper查出的数据放在自己的缓存种。
要开启缓存,首先要在主配置文件中显式的定义开启全局缓存:
之所以说是“显式”的开启,是因为默认是开启的,但是如果想使用二级缓存,最好写上。
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
要使用二级缓存,只要直接在Mapper.xml中增加:
<cache/>
缓存机制也可以在这里面配置
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
eviction- 清除策略,可用的清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象,默认的清除策略。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
flushInterval-刷新间隔,60000 是60s
size-存储上线,最多存储512 个引用
readOnly-属性可以被设置为 true 或 false,默认是false
true-只能读,其实就是1级缓存中演示的,取多次对象的时候会给同一个地址的对象。
false-允许写,就是自动复制一个对象,而且是通过序列化复制的,因此要实现序列化接口。(见最后拓展)

type-可以通过实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。
<cache type="com.domain.something.MyCustomCache"/>
定义的MyCustomCache要实现Cache接口
演示
Mapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.rzp.dao.UserMapper">
<!--使用二级缓存-->
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true" />
<select id="listById" resultType="user" >
select * from user where id = #{id}
</select> <update id="updateUser" parameterType="user">
update user set name=#{name},pwd=#{pwd} where id = #{id}
</update>
</mapper>
测试方法
@org.junit.Test
public void tes2(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.listById(1);
System.out.println(user);
sqlSession.close();
System.out.println("===================");
SqlSession sqlSession2 = MybatisUtils.getSqlSession();
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
User user2 = mapper2.listById(1);
sqlSession2.close();
System.out.println(user2);
System.out.println(user==user2);
}
很明显,只查询了一次,第二个SqlSessioin没有取资源

拓展-序列化
上一个例子中,如果把readOnly设置成false
<cache readOnly="false" />
就会产生IO异常,提示这个实体类没有被序列化
Cause: java.io.NotSerializableException: com.rzp.pojo.User
这个时候只要在实体类里面继承序列化接口就可以了
public class User implements Serializable {
private int id;
private String name;
private String pwd;
}
而且查出来的对象是复制出来的,而不是同一个地址的对象(测试方法和上面一样)

序列化的定义
对象序列化是一个用于将对象状态转换为字节流的过程,因为字节流才能将保存到磁盘文件中(持久化)或通过网络发送到任何其他程序;从字节流创建对象的相反的过程称为反序列化。
对象的存储必须要序列化,这里的存储和数据库的存储不一样,数据库是存储这个对象里属性的值,而不是这个对象。
而把对象序列化只需要在实体类里继承序列化接口
public class User implements Serializable {
...
}
这个接口是空的,其实是一个声明,告诉JVM这个类可以进行序列化。
并不是所有类都可以序列化的:
https://baijiahao.baidu.com/s?id=1633305649182361563&wfr=spider&for=pc
Mybatis缓存的基本流程
开始查询,看二级缓存中是否有数据。
二级缓存没有,看一级缓存中是否有数据。
一级也没有,查询数据库。
把查询得到的数据放在一级缓存中。
一级缓存结束,再放到二级缓存中。
Ecaches
是一种广泛使用的开源Java分布式缓存,主要面向通用缓存
导入依赖
<!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache -->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.0</version>
</dependency>
在resource里面配置ehcache.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!--
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="./tmpdir/Tmp_EhCache"/>
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
<!--
defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。
-->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统当机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
-->
</ehcache>
MyBatis(十):Mybatis缓存的重要内容的更多相关文章
- mybatis学习(十)——缓存介绍
与Hibernate一样,MyBatis 也提供了一级缓存和二级缓存的支持. 1.一级缓存:(本地缓存)SqlSession级别的缓存,默认一直开启的 , 与数据库同一次会话期间的数据会放到本地缓存中 ...
- Spring Boot + Mybatis + Redis二级缓存开发指南
Spring Boot + Mybatis + Redis二级缓存开发指南 背景 Spring-Boot因其提供了各种开箱即用的插件,使得它成为了当今最为主流的Java Web开发框架之一.Mybat ...
- Mybatis的二级缓存注意点
--声明:一下内容都不一定是正确的,只是自己测试的结果,请自己的动手操作得出自己的结论 1.开启Mybatis的二级缓存,不仅要在SqlMapConfig.xml中进行开启总开关,还要在对应的XXXM ...
- mybatis学习 十一 缓存
1. 应用程序和数据库交互的过程是一个相对比较耗时的过程2. 缓存存在的意义:让应用程序减少对数据库的访问,提升程序运行效率3. MyBatis 中默认 SqlSession 缓存(一级缓存)开启 同 ...
- sping整合redis,以及做mybatis的第三方缓存
一.spring整合redis Redis作为一个时下非常流行的NOSQL语言,不学一下有点过意不去. 背景:学习Redis用到的框架是maven+spring+mybatis(框架如何搭建这边就不叙 ...
- 认识Mybatis的一二级缓存
认识Mybatis的一二级缓存 一次完整的数据库请求,首先根据配置文件生成SqlSessionFactory,再通过SqlSessionFactory开启一次SqlSession,在每一个SqlSes ...
- Mybatis中的缓存管理
目录 Mybatis中的缓存管理 查询缓存工作原理: 配置缓存: 默认配置: 使用二级缓存: 刷新缓存过程: 配置EHcache 产生脏数据 使用原则: Mybatis中的缓存管理 查询缓存工作原理: ...
- 【Mybatis】MyBatis之缓存(七)
MyBatis缓存介绍 Mybatis 使用到了两种缓存:一级缓存(本地缓存.local cache)和二级缓存(second level cache). 一级缓存:基于PerpetualCache ...
- 缓存机制总结(JVM内置缓存机制,MyBatis和Hibernate缓存机制,Redis缓存)
一.JVM内置缓存(值存放在JVM缓存中) 我们可以先了解一下Cookie,Session,和Cache Cookie:当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cooki ...
随机推荐
- drf呼啦圈
呼啦圈 1.1 表结构设计 不会经常变化的值放在内存:choices形式,避免跨表性能低. 分表:如果表中列太多/大量内容可以选择水平分表 表自关联 from django.db import mod ...
- JavaScript 基础知识汇总目录
一.标签.代码结构.现代模式.变量.数据类型.类型转换 GO 二.运算符.值的比较.交互.条件运算符.逻辑运算符 GO 三.循环 while 和 for .switch语句.函数.函数表达式和箭头函数 ...
- Spring 多数据源配置(转)
转载自:https://www.cnblogs.com/digdeep/p/4512368.html 同一个项目有时会涉及到多个数据库,也就是多数据源.多数据源又可以分为两种情况: 1)两个或多个数据 ...
- 【Weiss】【第04章】二叉搜索树例程
[二叉搜索树] 随机生成时平均深度为logN,平均插入.删除和搜索时间都是O(logN). 可能存在的问题是数据不均衡,使树单边生长,极端情况下变成类似链表,最坏插入.删除.搜索时间O(N) 写这个例 ...
- [C#] 命令总线模式
1 高内聚.低耦合 虽然已经毕业很多年了,但依然总是能记得,<软件工程>这门课的老师总是强调 "高内聚,低耦合". 这些年,在架构方面的技术发展方向,目标就是不断的拆分 ...
- 【开发工具 docker】值得学习的应用容器引擎docker安装
概述: Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何 ...
- idea 新建java类自动补充创建人,创建时间,版本等..
1.先进入 File 2.进入 Editor 找到 File and Code Templates 并点击 3.右侧点击 lncludes 4.第二项 File Header /** * @aut ...
- hdu1226超级密码 bfs
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/1226/ 题目大意是:寻找一个五百位之内的C进制密码,该密码是N的正整数倍,而且只能用给定的数构成密码,求这样的密 ...
- Java第十三周实验作业
实验十三 图形界面事件处理技术 实验时间 2018-11-22 1.实验目的与要求 (1) 掌握事件处理的基本原理,理解其用途: 事件源:能够产生事件的对象都可以成为事件源,如文本框.按钮等,一个事 ...
- 【i春秋综合渗透测试】《我很简单,请不要欺负我》
第2题:获取目标网站管理员的密码 扫到了后台(/admin),本来想用sqlmap跑一下,但是随便试了个弱口令(admin888)就进去了... 第3题: getshell 配置插马:登录后台 ...