K-means聚类分析
一、原理
- 先确定簇的个数,K
- 假设每个簇都有一个中心点 centroid
- 将每个样本点划分到距离它最近的中心点所属的簇中
选择K个点做为初始的中心点
while()
{
将所有点分配个K个中心点形成K个簇
重新计算每个簇的中心点
if(簇的中心点不再改变)
break;
}
- 目标函数:定义为每个样本与其簇中心点的距离的 平方和(theSum of Squared Error, SSE)
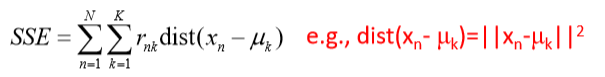
– μk 表示簇Ck 的中心点(或其它能代表Ck的点)
– 若xn被划分到簇Ck则rnk=1,否则rnk= 0
• 目标:找到簇的中心点μk及簇的划分rnk使得目标 函数SSE最小

- 初始中心点通常是随机选取的(收敛后得到的是局部最优解)
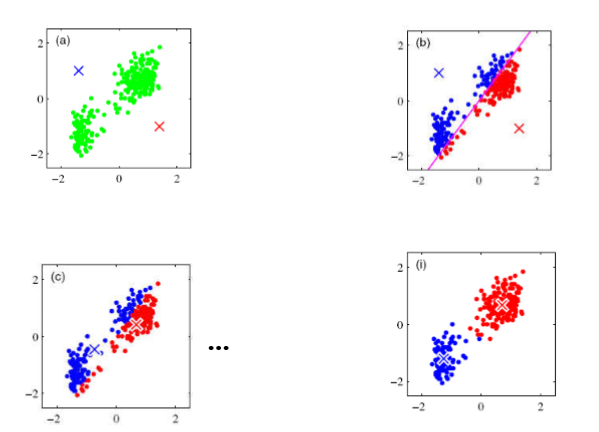
不同的中心点会对聚类结果产生不同的影响:
1、
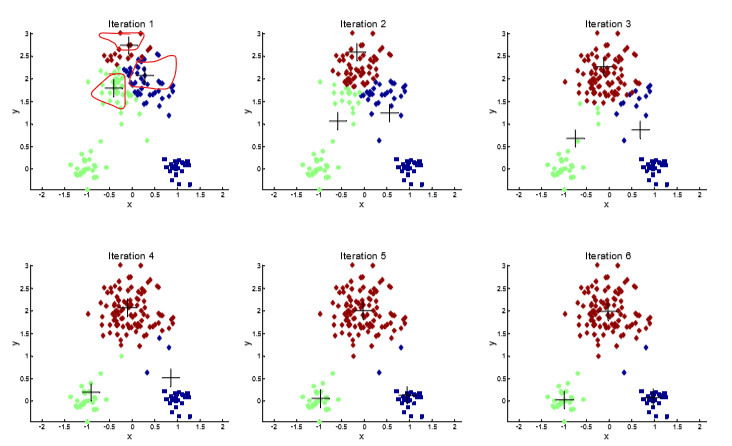
2、
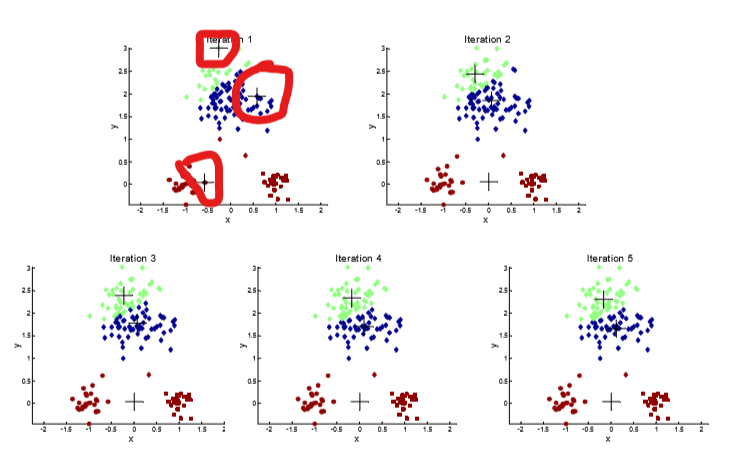
此时你一定会有疑问:如何选取"较好的"初始中心点?
- 凭经验选取代表点
- 将全部数据随机分成c类,计算每类重心座位初始点
- 用“密度”法选择代表点
- 将样本随机排序后使用前c个点作为代表点
- 从(c-1)聚类划分问题的解中产生c聚类划分问题的代表点
结论:若对数据不够了解,可以直接选择2和4方法
- 需要预先确定K
Q:如何选取K
SSE一般随着K的增大而减小
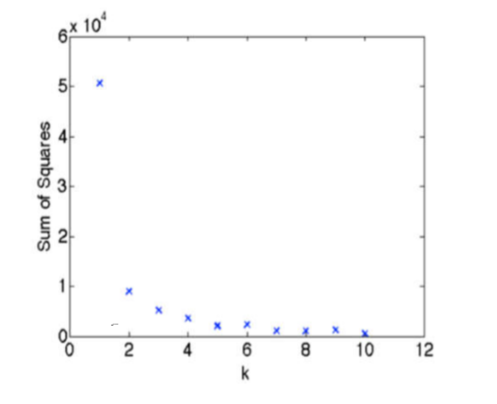
A:emmm你多尝试几次吧,看看哪个合适。斜率改变最大的点比如k=2
总结:
简单的来说,K-means就是假设有K个簇,然后通过上面找初始点的方法,找到K个初始点,将所有的数据分为K个簇,然后一直迭代,在所有的簇里面找到找到簇的中心点μk及簇的划分rnk使得目标函数SSE最小或者中心点不变之后,迭代完成。成功把数据分为K类。
预告:下一篇博文讲K-means代码实现
K-means聚类分析的更多相关文章
- SPSS聚类分析:K均值聚类分析
SPSS聚类分析:K均值聚类分析 一.概念:(分析-分类-K均值聚类) 1.此过程使用可以处理大量个案的算法,根据选定的特征尝试对相对均一的个案组进行标识.不过,该算法要求您指定聚类的个数.如果知道, ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- R 语言实战-Part 5-1笔记
R 语言实战(第二版) part 5-1 技能拓展 ----------第19章 使用ggplot2进行高级绘图------------------------- #R的四种图形系统: #①base: ...
- Python使用RMF聚类分析客户价值
投资机构或电商企业等积累的客户交易数据繁杂.需要根据用户的以往消费记录分析出不同用户群体的特征与价值,再针对不同群体提供不同的营销策略. 用户分析指标 根据美国数据库营销研究所Arthur Hughe ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- SPSS与聚类分析
1.进行K均值聚类分析时需要线标准化处理,抛弃量纲差异,比如说数值型变量有的以千记有的以百分数记.2.层次聚类就是先把每个样本都看成一个独立的类:聚类特征(Clustering Feature, CF ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- R数据挖掘 第一篇:聚类分析(划分)
聚类是把一个数据集划分成多个子集的过程,每一个子集称作一个簇(Cluster),聚类使得簇内的对象具有很高的相似性,但与其他簇中的对象很不相似,由聚类分析产生的簇的集合称作一个聚类.在相同的数据集上, ...
随机推荐
- 一文带你深入了解 Lambda 表达式和方法引用
前言 尽管目前很多公司已经使用 Java8 作为项目开发语言,但是仍然有一部分开发者只是将其设置到 pom 文件中,并未真正开始使用.而项目中如果有8新特性的写法,例如λ表达式.也只是 Idea Al ...
- Flutter 首页必用组件NestedScrollView
老孟导读:昨天Flutter 1.17版本重磅发布,新的版本主要是优化性能.修复bug,有人觉得此版本毫无亮点,但也从另一方面体现了Flutter目前针对移动端已经较为完善,想了解具体内容,文末有链接 ...
- POJ3169(差分约束:转载)
转载自mengxiang000000传送门 Layout Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10278 Ac ...
- 树的最小支配集 E - Cell Phone Network POJ - 3659 E. Tree with Small Distances
E - Cell Phone Network POJ - 3659 题目大意: 给你一棵树,放置灯塔,每一个节点可以覆盖的范围是这个节点的所有子节点和他的父亲节点,问要使得所有的节点被覆盖的最少灯塔数 ...
- 字典树变形 A - Gaby And Addition Gym - 101466A
A - Gaby And Addition Gym - 101466A 这个题目是一个字典树的变形,还是很难想到的. 因为这题目每一位都是独立的,不会进位,这个和01字典树求最大的异或和是不是很像. ...
- 基本Linux命令(上)
Linux的难点在于我们需要记忆大量的命令及参数.如有问题请批评指正,在下感激不尽. Linux的命令都是在shell下使用的,也就是我们常说的终端(Terminal).包 ...
- CC2530应用——按键控制灯光状态变化
独立新建工程并编写.编译代码,实现按键控制灯光闪烁状态的变换,实现以下任务要求:[1]程序开始运行:D4灯闪烁,D3.D5.D6灯熄灭.[2]按下模块上的SW1按键松开后,实现D5.D6灯轮流闪烁.[ ...
- Spring Cloud学习 之 Spring Cloud Hystrix(使用详解)
文章目录 创建请求命令: 定义服务降级: 异常处理: 异常传播: 异常获取: 命令名称,分组以及线程池划分: 创建请求命令: Hystrix命令就是我们之前说的HystrixCommand,它用来 ...
- Python爬虫丨大众点评数据爬虫教程(1)
大众点评数据获取 --- 基础版本 大众点评是一款非常受普罗大众喜爱的一个第三方的美食相关的点评网站. 因此,该网站的数据也就非常有价值.优惠,评价数量,好评度等数据也就非常受数据公司的欢迎. 今天就 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目
首先,默认咱们已经有了.net core 3.1的开发环境,如果你没有,快去下载... https://dotnet.microsoft.com/download 由于项目是基于abp vNext开发 ...