基于Doc2vec训练句子向量
目录
一.Doc2vec原理
二.代码实现
三.总结
一.Doc2vec原理
前文总结了Word2vec训练词向量的细节,讲解了一个词是如何通过word2vec模型训练出唯一的向量来表示的。那接着可能就会想到,有没有什么办法能够将一个句子甚至一篇短文也用一个向量来表示呢?答案是肯定有的,构建一个句子向量有很多种方法,今天我们接着word2vec来介绍下Doc2vc,看下Doc2vec是怎么训练一个句子向量的。
许多机器学习算法需要的输入是一个固定长度的向量,当涉及到短文时,最常用的固定长度的向量方法是词袋模型(bag-of-words)。尽管它很流行,但是词袋模型存在两个主要的缺点:一个是词袋模型忽略词序,如果两个不同的句子由相同的词但是顺序不同组成,词袋模型会将这两句话定义为同一个表达;另一个是词袋模型忽略了句法,这样训练出来的模型会造成类似‘powerful‘,‘strong’和‘Paris’的距离是相同的,而其实‘powerful’应该相对于’Paris‘距离’strong‘更近才对。
Doc2vec又叫Paragraph Vector是Tomas Mikolov基于word2vec模型提出的,其具有一些优点,比如不用固定句子长度,接受不同长度的句子做训练样本,Doc2vec是一个无监督学习算法,该算法用于预测一个向量来表示不同的文档,该模型的结构潜在的克服了词袋模型的缺点。
Doc2vec模型是受到了word2vec模型的启发,word2vec里预测词向量时,预测出来的词是含有词义的,比如上文提到的词向量’powerful’会相对于’Paris’离’strong‘距离更近,在Doc2vec中也构建了相同的结构。所以Doc2vec克服了词袋模型中没有语义的去缺点。假设现在存在训练样本,每个句子是训练样本。和word2vec一样,Doc2vec也有两种训练方式,一种是PV-DM(Distributed Memory Model of paragraph vectors)类似于word2vec中的CBOW模型,如图一:
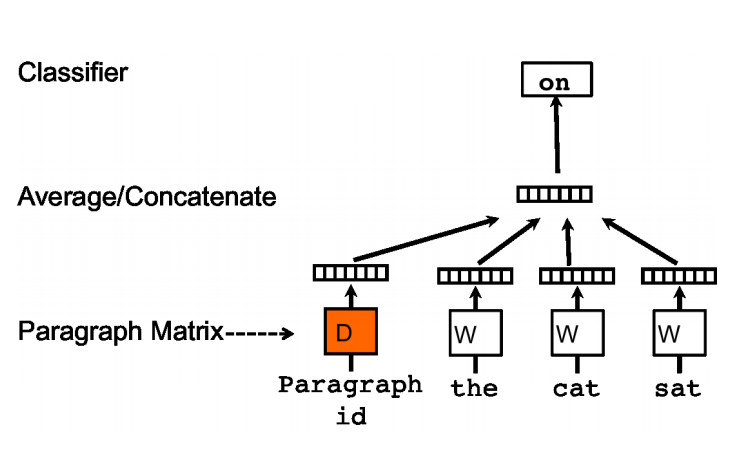
另一种是PV-DBOW(Distributed Bag of Words of paragraph vector类似于Word2vec中的skip-gram模型,如图二:
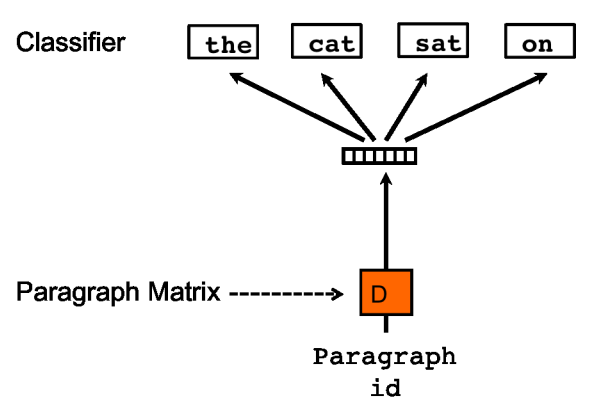
在Doc2vec中,每一句话用唯一的向量来表示,用矩阵D的某一列来代表。每一个词也用唯一的向量来表示,用矩阵W的某一列来表示。以PV-DM模型为例,如图三:
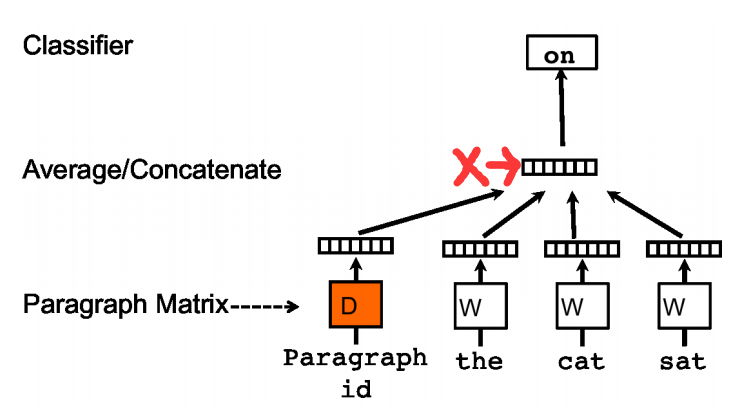
每次从一句话中滑动采样固定长度的词,取其中一个词作预测词,其他的作输入词。输入词对应的词向量word vector和本句话对应的句子向量Paragraph vector作为输入层的输入,将本句话的向量和本次采样的词向量相加求平均或者累加构成一个新的向量X,进而使用这个向量X预测此次窗口内的预测词。
Doc2vec相对于word2vec不同之处在于,在输入层,增添了一个新的句子向量Paragraph vector,Paragraph vector可以被看作是另一个词向量,它扮演了一个记忆,词袋模型中,因为每次训练只会截取句子中一小部分词训练,而忽略了除了本次训练词以外该句子中的其他词,这样仅仅训练出来每个词的向量表达,句子只是每个词的向量累加在一起表达的。正如上文所说的词袋模型的缺点,忽略了文本的词序问题。而Doc2vec中的Paragraph vector则弥补了这方面的不足,它每次训练也是滑动截取句子中一小部分词来训练,Paragraph Vector在同一个句子的若干次训练中是共享的,所以同一句话会有多次训练,每次训练中输入都包含Paragraph vector。它可以被看作是句子的主旨,有了它,该句子的主旨每次都会被放入作为输入的一部分来训练。这样每次训练过程中,不光是训练了词,得到了词向量。同时随着一句话每次滑动取若干词训练的过程中,作为每次训练的输入层一部分的共享Paragraph vector,该向量表达的主旨会越来越准确。Doc2vec中PV-DM模型具体的训练过程和word2vec中的CBOW模型训练方式相同,在之前我写的基于Word2vec训练词向量(一)里有详细介绍,这里就不在重复。
训练完了以后,就会得到训练样本中所有的词向量和每句话对应的句子向量,那么Doc2vec是怎么预测新的句子Paragraph vector呢?其实在预测新的句子的时候,还是会将该Paragraph vector随机初始化,放入模型中再重新根据随机梯度下降不断迭代求得最终稳定下来的句子向量。不过在预测过程中,模型里的词向量还有投影层到输出层的softmax weights参数是不会变的,这样在不断迭代中只会更新Paragraph vector,其他参数均已固定,只需很少的时间就能计算出带预测的Paragraph vector。
二.代码实现
在python中使用gensim包调用Doc2vec方便快捷,在这简单演示下,gensim下Doc2vec详细的参数不在此详细阐述。本次的数据是之前比赛中公开的旅游数据集,里边每一条都是游客对于景点的评价。具体的Doc2vec训练Paragraph vector步骤如下:
1.导包:导入必要的包,其中的jieba是为了给文本进行分词。
2.导入数据集,提取Discuss列(该列是用户评价的内容)。
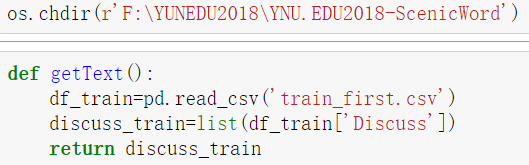

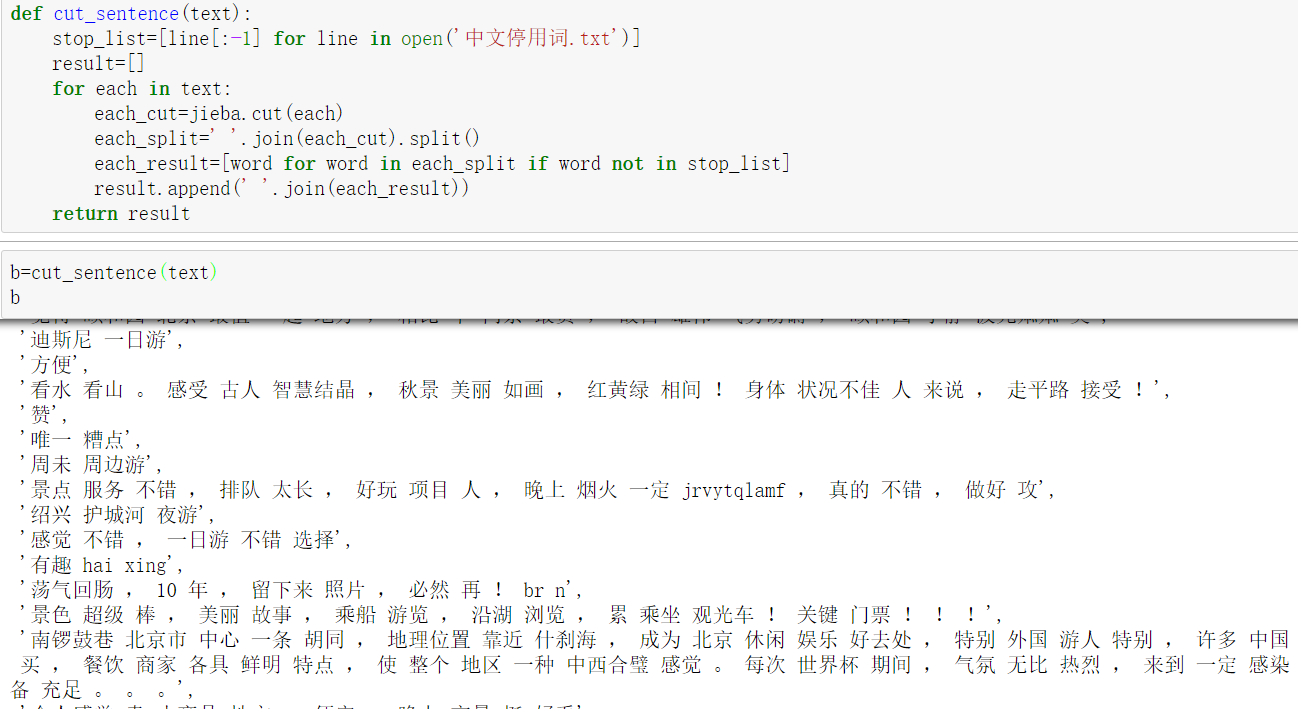
3.将提取好的Discuss列中的内容进行分词,并去除停用词。
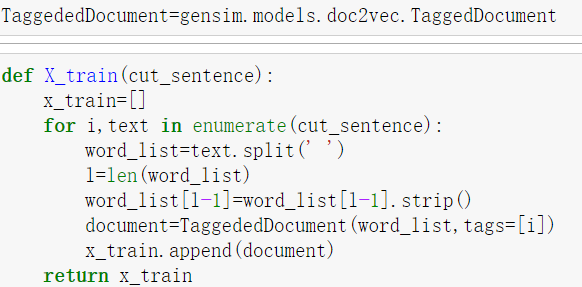
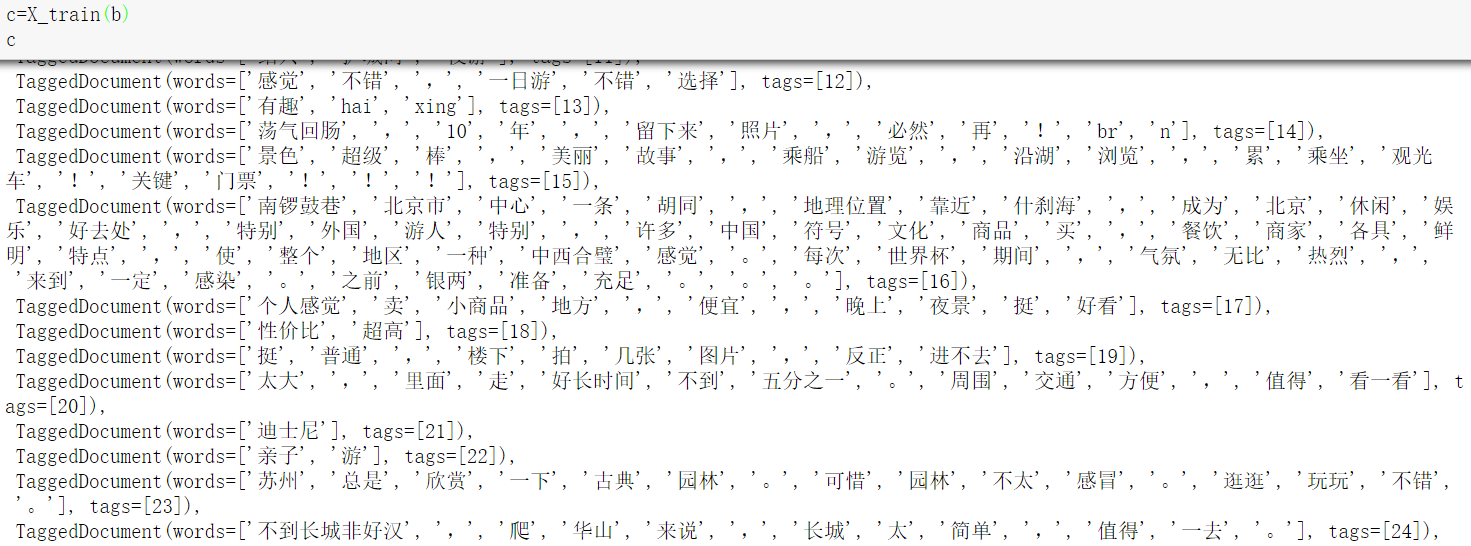
4.改变成Doc2vec所需要的输入样本格式,由于gensim里Doc2vec模型需要的输入为固定格式,输入样本为:[句子,句子序号],这里需要用gensim中Doc2vec里的TaggedDocument来包装输入的句子。
5.加载Doc2vec模型,并开始训练。

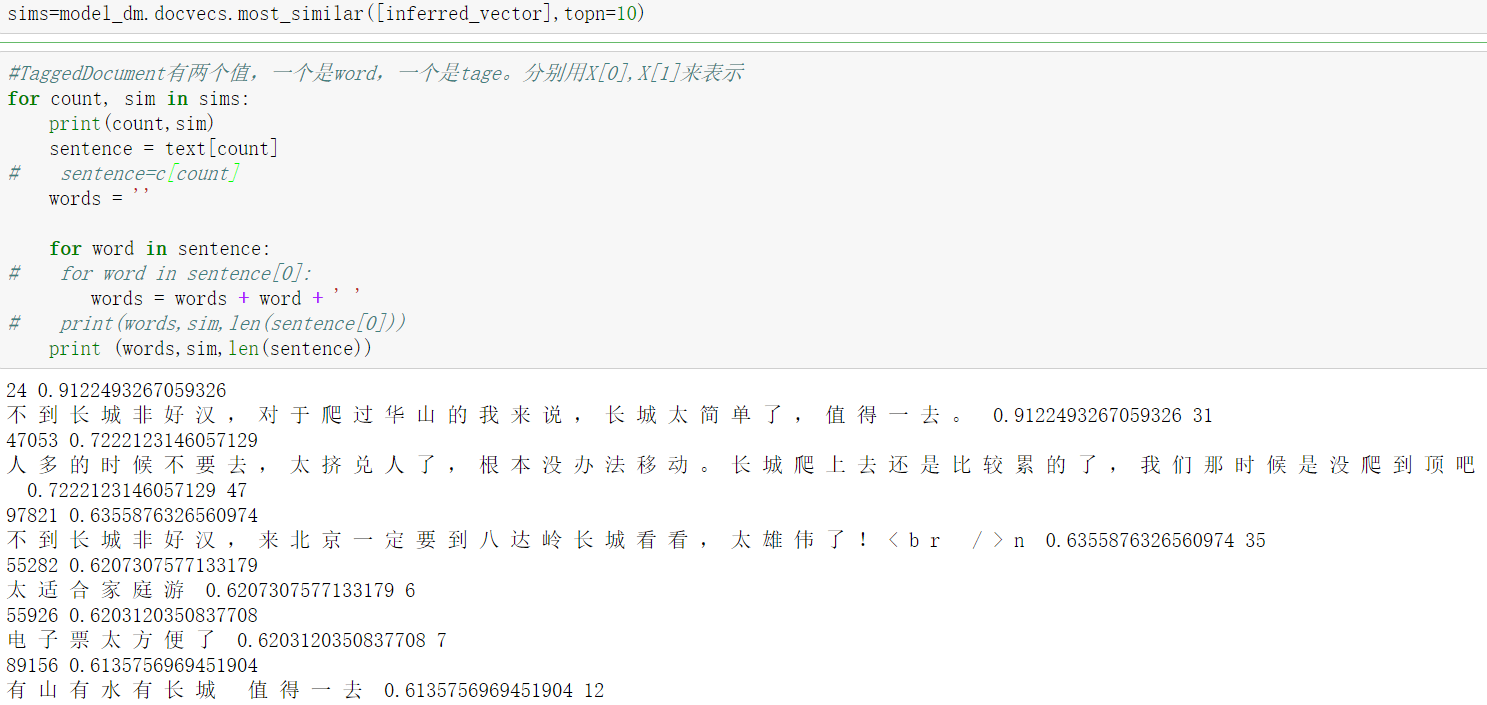
6.模型训练完毕以后,就可以预测新的句子的向量Paragraph vector了,这里用gensim里infer_vector()预测新的句子,这里根据经验,alpha(学习步长)设置小一些,迭代次数设置大一些。找到训练样本中与这个句子最相近的10个句子。可以看到训练出来的结果与测试的新句子是有关联的。

三.总结
Doc2vec是基于Word2vec基础上构建的,相比于Word2vec,Doc2vec不仅能训练处词向量还能训练处句子向量并预测新的句子向量。Doc2vec模型结构相对于Word2vec,不同点在于在输入层上多增加了一个Paragraph vector句子向量,该向量在同一句下的不同的训练中是权值共享的,这样训练出来的Paragraph vector就会逐渐在每句子中的几次训练中不断稳定下来,形成该句子的主旨。这样就训练出来了我们需要的句子向量。在预测新的句子向量时,是需要重新训练的,此时该模型的词向量和投影层到输出层的soft weights参数固定,只剩下Paragraph vector用梯度下降法求得,所以预测新句子时虽然也要放入模型中不断迭代求出,相比于训练时,速度会快得多。本次使用的数据集为情感分析,且大多数样本偏向于好评,样本内容比较单一,所以训练出来的结果都是偏向于哪里好玩,好不好这类的意思,对于一些特定的问题之类的句子准确性还没有验证,目前用于情感分析还是可以的。下次会尝试使用新的数据集,调试参数看是否会取得更好的结果。
基于Doc2vec训练句子向量的更多相关文章
- 基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/ 一.基于Hierarchical Softmax的word2vec模型的缺点 上篇说了Hi ...
- 基于word2vec训练词向量(一)
转自:https://blog.csdn.net/fendouaini/article/details/79905328 1.回顾DNN训练词向量 上次说到了通过DNN模型训练词获得词向量,这次来讲解 ...
- 将句子表示为向量(下):基于监督学习的句子表示学习(sentence embedding)
1. 引言 上一篇介绍了如何用无监督方法来训练sentence embedding,本文将介绍如何利用监督学习训练句子编码器从而获取sentence embedding,包括利用释义数据库PPDB.自 ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- NLP之基于Transformer的句子翻译
Transformer 目录 Transformer 1.理论 1.1 Model Structure 1.2 Multi-Head Attention & Scaled Dot-Produc ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- DNN模型训练词向量原理
转自:https://blog.csdn.net/fendouaini/article/details/79821852 1 词向量 在NLP里,最细的粒度是词语,由词语再组成句子,段落,文章.所以处 ...
- 词表征 3:GloVe、fastText、评价词向量、重新训练词向量
原文地址:https://www.jianshu.com/p/ca2272addeb0 (四)GloVe GloVe本质是加权最小二乘回归模型,引入了共现概率矩阵. 1.基本思想 GloVe模型的目标 ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
随机推荐
- C++走向远洋——37(工资类,2)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:salarly.cpp * 作者:常轩 * 微信公众号:Worl ...
- 6——PHP顺序结构&&字符串连接符
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 达拉草201771010105《面向对象程序设计(java)》第三周学习总结
达拉草201771010105«面向对象程序设计(java)»第三周学习总结 第一部分:实验部分 1.实验目的与要求 (1)进一步掌握Eclipse集成开发环境下java程序开发基本步骤: (2)熟 ...
- 一起了解 .Net Foundation 项目 No.12
.Net 基金会中包含有很多优秀的项目,今天就和笔者一起了解一下其中的一些优秀作品吧. 中文介绍 中文介绍内容翻译自英文介绍,主要采用意译.如与原文存在出入,请以原文为准. Cecil Cecil 是 ...
- sql01
1.简介 2.外键 1)主键: 3.表间关联与外键 上面的两个表格通过厂家编号联系在一起,彼此相对独立.厂家编号就称为外键.厂家编号是厂家表的主键. 4.SQL 1)数据库登录 服务器名称选择:①机器 ...
- 基础JavaScript练习(二)总结
任务目的 学习与实践JavaScript的基本语法.语言特性 练习使用JavaScript实现简单的排序算法 任务描述 基于上一任务 限制输入的数字在10-100 队列元素数量最多限制为60个,当超过 ...
- 第三篇:Linux的基本操作与文件管理(纯命令行模式下)(下)
接上篇介绍完软件的管理(查询.删除.安装)之后,本篇将介绍Linux的文件和目录的管理. 如何浏览Linux的目录(文件夹),就像Windows一样,我们平时需要打开各个目录,去里面找一找曾经悄悄存储 ...
- bug的前世今生
项目上发现的产品bug,若本地有问题,那就是漏测 1.提到产品bug系统 2.需要追踪,要么是漏测,要么是改出来的问题,漏测的需要补充到测试点里 项目上发现的产品bug,若本地没问题,那就是项目上的产 ...
- Simulink仿真入门到精通(六) Simulink模型保存为图片
6.1 截图保存方式 Ctrl+Alt+A 6.2 拷贝试图方式 Edit→Copy Current View to Clipboard 6.3 saveas函数 用于保存figure或者simuli ...
- win10安装docker 和 splash
参考链接1:https://www.cnblogs.com/321lxl/p/9536616.html 参考链接2:https://blog.csdn.net/qq_18831501/article/ ...