SVM——支持向量机(完整)
最基本的SVM(Support Vector Machine)旨在使用一个超平面,分离线性可分的二类样本,其中正反两类分别在超平面的一侧。SVM算法则是要找出一个最优的超平面。
线性可分SVM
优化函数定义
给定一个特征空间线性可分的数据集:
$T = \{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$
特征分布类似下图:
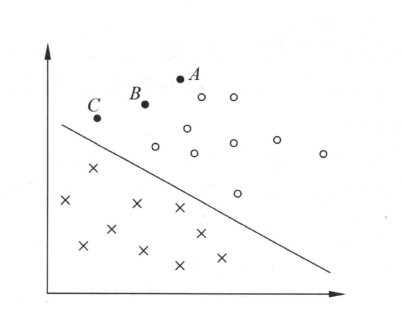
如上图,当特征空间为二维时,超平面就是比二维空间第一维度的直线。任意维超平面定义如下(其中$x$是$n$维特征向量,$w,b$是超平面系数):
$wx+b = 0$
对于正例应有$wx_i+b > 0$,反例应有$wx_i+b < 0$,也就是说,如果分类正确,应有:
$y_i(wx_i+b)> 0$
从直观上看,最优超平面,应该是在将所有样本都正确分类的基础上,使与之距离最近的样本点的距离最大化。点到面的距离公式中学学过
$\displaystyle \frac{|wx+b|}{|| w ||}$
综上,优化的问题用数学方式表达:
$\displaystyle\max\limits_{w,b}\min\limits_{i}(\frac{y_i(wx_i+b)}{||w||})$
或者
$\begin{align*} &\max\limits_{w,b}\;\gamma \\ &\;\text{s.t.}\;\;\;y_i(\frac{w}{||w||}x_i+\frac{b}{||w||})\ge \gamma,\;\;i=1,2,...,N \end{align*}$
其中$\gamma$为最小距离。令$ \hat{\gamma}=\gamma||w|| $,即所谓“函数距离”,上式可变为:
$\begin{align*} &\max\limits_{w,b}\;\frac{\hat{\gamma}}{||w||} \\ &\;\text{s.t.}\;\;\;y_i(wx_i+{b})\ge \hat{\gamma },\;\;i=1,2,...,N\end{align*}$
$\hat{\gamma}$没有被$||w||$规范化,因此大小与$||w||$有关。而$w,b$等比例变化时,超平面并没有变。因此,可以固定$||w||=1$,最大化$\hat{\gamma}$,即:
$\begin{align*} &\max\limits_{w,b}\;\hat{\gamma}\\ &\;\text{s.t.}\;\;\;y_i(wx_i+{b})\ge \hat{\gamma },\;\;i=1,2,...,N\end{align*}$
或者固定$\hat{\gamma}=1$,最小化$||w||$,也就是:
$\begin{align*} &\min\limits_{w,b}\;\frac{1}{2}||w||^2 \\ &\;\text{s.t.}\;\;\;y_i(wx_i+{b})\ge 1,\;\;i=1,2,...,N\end{align*}$
通常是最小化$||w||$。这是一个凸二次规划问题,即待优化的函数$\frac{1}{2}||w||^2$是二次函数,不等式约束条件$1-y_i(wx_i+{b})\le 0$为可微凸函数(注意!小于等于0要求凸函数,如果大于等于0就要求是凹函数了)。
对偶算法
上述带约束优化满足原始问题最优值与对偶问题最优值取等的条件,因此可以使用拉格朗日对偶性(点击链接)将原始优化问题转换为其对偶问题求解。原始问题的拉格朗日函数为:
$\displaystyle \begin{gather}L(w,b,\alpha) = \frac{1}{2}||w||^2- \sum\limits_{i=1}^{N}\alpha_iy_i(wx_i+b)+\sum\limits_{i=1}^{N}\alpha_i,\,\,\alpha\ge 0 \label{}\end{gather}$
因此原始问题为:
$\displaystyle \begin{gather} \min\limits_{w,b}\max\limits_{\alpha\ge 0 }L(w,b,\alpha) \label{}\end{gather}$
则对偶问题为:
$\displaystyle \begin{gather}\max\limits_{\alpha\ge 0 } \min\limits_{w,b}L(w,b,\alpha) \label{}\end{gather}$
由KKT条件1式令梯度为0,计算对偶问题内部的$\min$函数
$\begin{aligned} &\nabla_wL(w,b,\alpha) = w-\sum\limits_{i=1}^{N}\alpha_iy_ix_i=0 \\ &\nabla_bL(w,b,\alpha) = -\sum\limits_{i=1}^{N}\alpha_iy_i=0 \\ \end{aligned}$
得
$\begin{gather} &w = \sum\limits_{i=1}^{N}\alpha_iy_ix_i \\ &\sum\limits_{i=1}^{N}\alpha_iy_i=0 \label{}\end{gather}$
代入$(3)$式,经过计算,对偶问题变为:
$\begin{gather} \begin{array}{lcl} \min\limits_{\alpha}\displaystyle\frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_ix_j)-\sum\limits_{i=1}^{N}\alpha_i \\ \begin{aligned} \text{s.t.}\;&\sum\limits_{i=1}^{N}\alpha_iy_i=0\\ &\alpha_i\ge 0,i = 1,2,...,N \end{aligned} \end{array} \end{gather}$
这样,只需先优化对偶问题,计算出最优的$\alpha^*$,再代入$(4)$式即可算出最优$w^*$。对于$b$,因为至少有一个$\alpha_j^*>0$(如果全都为0,由$(4)$式有$w=0$,不符合约束),对应KKT条件2式
$\alpha_i(y_i(wx_i+b)-1)=0$
于是有
$y_j(w^*x_j+b^*)-1=0$
实际上这个$x_j$就是与超平面最近的的样本,也就是所谓的支持向量。另外也说明了这个优化问题的解一定在不等式约束的边界上,而不在其内部。于是,提取$b^*$并代入$(4)$式,得:
$\begin{gather}\displaystyle b^* = y_j-\sum\limits_{i=1}^{N}\alpha_i^*y_i(x_ix_j)\end{gather}$
综上,计算最优$w^*,b^*$的操作就是:先$(6)$式算出$\alpha^*$,再代入$(4),(7)$式算出$w^*,b^*$。
但是$(6)$实际上并不好算,当样本量一大,$\alpha$需要分类讨论的情况数以指数级上升(即每个$\alpha$是否为0),后面介绍开销小的算法。
线性SVM
参数计算
有时样本会有特异点,不能保证每个样本都满足不等式约束。因此修改上面的“硬间隔最大化”为“软间隔最大化”,则线性可分SVM变为线性SVM。即添加一个松弛变量$\xi$,允许原来的不等式约束不一定严格满足,当然在优化函数中也要把这一损失加上,乘上惩罚参数$C$。得到如下最优化问题:
$\begin{gather} \begin{array}{lcl} \min\limits_{w,b,\xi}\;\displaystyle\frac{1}{2}||w||^2+C\sum\limits_{i=1}^{N}\xi_i \\ \begin{aligned} \text{s.t.}\;\;\;&y_i(wx_i+{b})\ge 1-\xi_i,\;\;i=1,2,...,N\\ &\xi_i\ge 0,\;\;i=1,2,...,N\\ \end{aligned} \end{array}\end{gather}$
显然待优化函数与不等式约束都是凸函数(仿射函数也是凸函数)。因此同样符合KKT条件,可以对偶化计算。拉格朗日函数为:
$ \begin{aligned} \displaystyle L(w,b,\xi,\alpha,\mu) =& \frac{1}{2}||w||^2+C\sum\limits_{i=1}^{N}\xi_i-\sum\limits_{i=1}^{N}\alpha_i(y_i(wx_i+b)-1+\xi_i)-\sum\limits_{i=1}^{N}\mu_i\xi_i,\\ &\text{where}\;\;\alpha_i\ge 0,\mu_i\ge 0 \end{aligned} $
则原始问题变为:
$ \min\limits_{w,b,\xi}\max \limits_{\alpha\ge 0 ,\mu \ge 0}L(w,b,\xi,\alpha,\mu) $
其对偶问题为:
$\begin{gather} \max \limits_{\alpha\ge 0 ,\mu \ge 0}\min\limits_{w,b,\xi}L(w,b,\xi,\alpha,\mu) \end{gather}$
由KKT条件1式令梯度为0,计算对偶问题内部$\min$函数,得:
\begin{align} &\nabla_wL(w,b,\xi,\alpha,\mu) = w-\sum\limits_{i=1}^{N}\alpha_iy_ix_i=0 \\ &\nabla_bL(w,b,\xi,\alpha,\mu) = -\sum\limits_{i=1}^{N}\alpha_iy_i=0 \notag\\ &\nabla_{\xi_i}L(w,b,\xi,\alpha,\mu) = C-\alpha_i-\mu_i=0 \notag \end{align}
代入$(9)$式,对偶问题变为:
\begin{gather} \begin{array}{lcl} \min\limits_{\alpha}\displaystyle\frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_ix_j)-\sum\limits_{i=1}^{N}\alpha_i \\ \begin{aligned} \text{s.t.}\;&\sum\limits_{i=1}^{N}\alpha_iy_i=0\\ &0\le\alpha_i\le C,\;\;i = 1,2,...,N \end{aligned} \end{array} \end{gather}
其中$\alpha_i\le C$是由于$C-\alpha_i=\mu_i\ge0 $。类似地,接下来的操作就是:
1、算出$(11)$式的最优$\alpha^*$。
2、$\alpha^*$代入$(10)$式计算$w^*$。
3、找出满足$\alpha_j^*$满足$0<\alpha_j^*<C$。
此时$\mu_j^* = C-\alpha_j^*>0$,由KKT条件2式,有$\mu_j^*\xi_j^*=0$,因此$\xi_j^*=0$。
同样地,由KKT2式,有$\alpha_j^*(y_j(w^*x_j+b^*)-1+\xi_j^*)=0$,因$\alpha_j^*>0$,于是有:
$\displaystyle b^* = y_j-\sum\limits_{i=1}^{N}\alpha_i^*y_i(x_ix_j)$
支持向量
在线性SVM中,因为有松弛变量$\xi$,不等式约束取等时样本不一定在其类别的边界上。上面只讨论了使用小于$C$的$\alpha_j^*$,下面做个总结:
1、若$\alpha_i^* = 0$ ,则$\xi_i = 0$ ,分类正确,$x_i$在分离间隔边界的外侧;
2、若$0<\alpha_i^* < C$ ,则$\xi_i = 0$ ,分类正确,支持向量$x_i$恰好落在间隔边界上;
3、若$\alpha_i^* = C,0<\xi_i<1$ ,则分类正确,$x_i$在间隔边界与分离超平面之间;
4、若$\alpha_i^* = C,\xi_i=1$,则分类错误,$x_i$在分离超平面上;
5、若$\alpha_i^* = C,\xi_i>1$,则分类错误,$x_i$位于分离超平面误分一侧。
其中2~5都是支持向量。
合页损失函数
线性SVM还有另一种等价的优化目标函数:
$\begin{gather}\displaystyle \min\limits_{w,b}\sum\limits_{i=1}^{N}\left[1-y_i(wx_i+b)\right]_++\lambda||w||^2\end{gather}$
其中
$[z]_+= \left\{ \begin{aligned} &z,\;\;z>0 \\ &0,\;\;z\le0 \end{aligned} \right.$
感觉可以直接梯度下降。
等价性证明
令$(12)$中
$\left[1-y_i(wx_i+b)\right]_+=\xi_i$
则
1、有$\xi_i\ge 0$(一个不等式约束成立);
2、当$1-y_i(wx_i+b)>0$时,可得$y_i(wx_i+b)=1-\xi_i$;
3、当$1-y_i(wx_i+b)\le0$时,$\xi_i=0$,有$y_i(wx_i+b)\ge1-\xi_i$。
综合2、3,不论$1-y_i(wx_i+b)$如何取值,总有$y_i(wx_i+b)\ge1-\xi_i$(另一个不等式约束成立)。
于是$(12)$可写成:
\begin{array}{lcl} \min\limits_{w,b,\xi}\displaystyle\sum\limits_{i=1}^{N}\xi_i+\lambda||w||^2\\ \begin{aligned} \text{s.t.}\;\;\;&y_i(wx_i+{b})\ge 1-\xi_i,\;\;i=1,2,...,N\\ &\xi_i\ge 0,\;\;i=1,2,...,N\\ \end{aligned} \end{array}
然后优化项常系数权重改一下就和$(8)$一模一样了。
非线性SVM
对于特征分布是非线性的样本,需要将非线性可分特征映射到另一个空间(维度不变或变高都可),变成线性可分特征。然后才能用线性SVM来优化参数。如图下左图到右图:
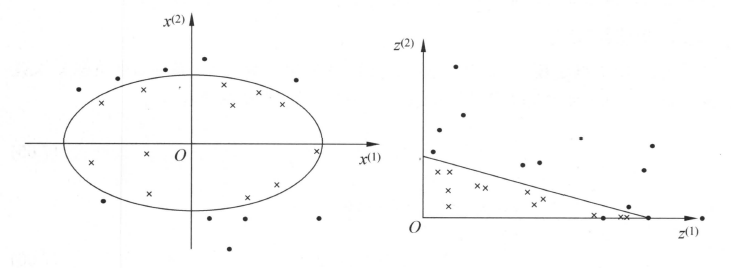
理论上需要定义确定的映射函数将输入映射成线性可分的特征,实际上这一中间环节可以隐去。下面说明这一方法。
核技巧
定义从输入空间到特征空间的映射$\phi(x):\mathcal{X}\to \mathcal{H}$,观察线性可分SVM的对偶问题和最终的判别函数,里面关于样本特征之间的运算都是内积。因此映射后的线性可分的样本特征要做的同样是内积。定义这一内积为:
$K(x,z)=<\phi(x),\phi(z)>$,后面内积直接用$\phi(x)\phi(z)$表示
样本的维度比较小还好,比如上图的二维,可以直接想出一个映射,但是当维度很高时就很难想了。因此想到,可以跳过定义映射,直接定义这个$K(x,z)$,称之为核函数。那么什么样的核函数一定可以表示成两个映射后的向量的内积呢?这样的核函数叫做正定核。
正定核的充要条件
设$K:\mathcal{X}\times\mathcal{X}\to R$为对称函数,则$K(x ,z) $为正定核函数的充要条件是:
对任意$x_i \in \mathcal{X}, i=1, 2,..., n, K(x, z) $对应的Gram 矩阵
$ \left[ \begin{matrix} K(x_1,x_1)&\cdots&K(x_1,x_n)\\ \vdots&&\vdots\\ K(x_n,x_1)&\cdots&K(x_n,x_n)\\ \end{matrix} \right]\succeq 0$
$\succeq 0$表示半正定。具体证明请看《统计学习方法》P136~139
常用正定核
多项式核函数:
$K(x,z)=(xz+1)^p$
高斯核函数:
$\displaystyle K(x,z)=\exp(-\frac{||x-z||^2}{2\sigma^2})$
使用核函数后,待优化的对偶问题变为:
$ \begin{array}{lcl} \min\limits_{\alpha}\displaystyle\frac{1}{2}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum\limits_{i=1}^{N}\alpha_i \\ \begin{aligned} \text{s.t.}\;&\sum\limits_{i=1}^{N}\alpha_iy_i=0\\ &0\le\alpha_i\le C,\;\;i = 1,2,...,N \end{aligned} \end{array} $
分类决策函数变为:
$\displaystyle f(x) = \text{sign}\left(\sum\limits_{i=1}^{N}\alpha^*_iy_iK(x_i,x)+b^*\right)=\text{sign}\left(\sum\limits_{i\in S}\alpha^*_iy_iK(x_i,x)+b^*\right)$
即原来的直接内积$x_ix$变成了先映射后内积的$K(x_i,x)$。其中$S$为支持向量集合($\alpha$不为0的样本集合,即2.2支持向量中的2~5)。
然而,选择合适的正定核以使输入映射成线性可分还需要作其它的努力。。。。。。。。。。
SMO算法
正如前面所说,在对偶问题中,$\alpha$需要分类讨论的情况数随着样本量的增大以指数级上升(即每个$\alpha$是否为0),SMO(sequential minimal optimization)算法可以加快对偶问题的优化。它采用迭代的方式,每次将待优化问题分离出一个小问题求解,最终求解原问题。
具体流程
初始化
初始化所有的$\alpha_i$为常数(通常为0),此时这些$\alpha_i$满足对偶问题的两个不等式约束:
$\begin{gather}&\sum\limits_{i=1}^{N}\alpha_iy_i=0\\ &0\le\alpha_i\le C,\;\;i = 1,2,...,N\\ \label{}\end{gather}$
实际上就是满足KKT条件的1和4,因为$(13)$是条件1使梯度为0得出的,$(14)$是条件1和4共同得到的。但是,它们并不一定同时满足KKT条件的2和3(因为原问题没有等式约束,所以没有条件5):
$\begin{gather}\displaystyle\alpha_i(1-\xi_i-y_i(\sum\limits_{j=1}^N\alpha_jy_jK_{ji}+b))=0\label{}\end{gather}$
$\begin{gather}\displaystyle1-\xi_i-y_i(\sum\limits_{j=1}^N\alpha_jy_jK_{ji}+b)\le0\label{}\end{gather}$
也就是:
$\begin{gather}y_i(\sum\limits_{j=1}^N\alpha_jy_jK_{ji}+b)\left\{\begin{aligned}&\ge1,\;\;\alpha_i=0\\&=1,\;\;0<\alpha_i<C\\&\le1,\;\;\alpha_i=C\\\end{aligned}\right.\label{}\end{gather}$
如果条件2和3也都满足的话,就迭代结束,也就达到最终的解了。其中每次迭代都会保持$(13),(14)$两个约束成立。
迭代优化
每次迭代,选出最“不好”的两个$\alpha$来进行优化,固定剩下的$N-2$个$\alpha$(这样的操作有点像小批量梯度下降)。如何才算“不好”的$\alpha$放后面讲,因为选择$\alpha$基于优化的效率,为了说明效率所在,所以先说优化。
不失一般性,假设选择的两个变量是$\alpha_1,\alpha_2$。则这个子问题可以写为(最小化中将与$\alpha_1,\alpha_2$无关的项去了):
$\begin{array}{lcl} \begin{aligned} \min\limits_{\alpha_i,\alpha_2}W(\alpha_1,\alpha_2) = &\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2-\\ &(\alpha_1+\alpha_2)+y_1\alpha_1\sum\limits_{i=3}^Ny_i\alpha_iK_{i1}+y_2\alpha_2\sum\limits_{i=3}^Ny_i\alpha_iK_{i2} \\ \end{aligned}\\ \begin{aligned} \text{s.t.}\;\;&\alpha_1y_1+\alpha_2y_2 = -\sum\limits_{i=3}^Ny_i\alpha_i = \varsigma\\ &0\le\alpha_i\le C,\;\;\;i=1,2 \end{aligned} \end{array}$
由$(13)$式,$\alpha_1$又可以被$\alpha_2$表达,于是这个子优化就变为一个带约束的一元二次函数最值问题,初中生的题目。主要操作就是先用导数求出二次函数的驻点,如果在约束内就为最终解,在约束外就选约束中与之较近的端点为解。尽管这么简单,但是为了后面的选择,还是要推导一下。约束可以在二维坐标系中表示出来:
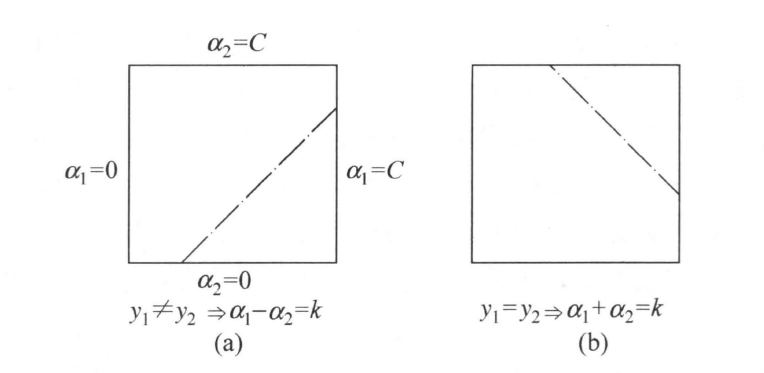
因为$y_1,y_2$绝对值为1,所以只要关于它们的符号进行分类。分成两种情况,$y_1\ne y_2$和$y_1=y_2$,于是可取的点分别如上图a、b中斜线所示。设$\alpha_2$取值为$[L,H]$,则当$y_1\ne y_2$时
$L=\max(0,\alpha_2-\alpha_1),H=\min(C,C+\alpha_2-\alpha_1)$
你可能会有为什么不用$\varsigma$而用$\alpha_2-\alpha_1$来算的疑问。这是因为每次迭代都保持$(13)$的成立,因此直接用$\alpha_2-\alpha_1$方便,而$\varsigma$需要算$N-2$个求和。又因为计算时利用了$(13),(14)$,所以这样算出来的$\alpha_1,\alpha_2$依然能维持$(13),(14)$的成立。当$y_1=y_2$时
$L=\max(0,\alpha_2+\alpha_1-C),H=\min(C,\alpha_2+\alpha_1)$
然后就是简单的先替换$\alpha_1$,再求导等于0,整理后得到:
$(K_{11}+K_{22}-2K_{12})\alpha_2^*=(K_{11}+K_{22}-2K_{12})\alpha_2+y_2(E_1-E_2)$
其中
\begin{gather} \displaystyle E_i=\left(\sum\limits_{j=1}^N\alpha_iy_iK(x_j,x_i)+b\right)-y_i \label{} \end{gather}
$E_i$理解为预测函数对$x_i$的预测值与其真实标签$y_i$之差。再定义
$ \eta = K_{11}+K_{22}-2K_{12}$
$\eta$理解为$x_1,x_2$映射到特征空间中的向量之间的距离(距离二范的平方),于是
$\begin{gather}\displaystyle\alpha_2^*=\alpha_2+\frac{y_2(E_1-E_2)}{\eta}\label{}\end{gather}$
然后更新$\alpha_2,\alpha_1$:
$ \alpha_2^{update}= \left\{ \begin{aligned} &H,&\alpha_2^*>H\\ &\alpha_2^*,&L\le\alpha_2^*\le H\\ &L,&\alpha_2^*<L\\ \end{aligned} \right. $
$\alpha_1^{update} = (\varsigma - \alpha_2^{update}y_2)y_1 = \alpha_1+y_1y_2(\alpha_2-\alpha_2^{update})$
最后还有$(18)$的$b$的计算,《统计学习方法》对$b$的计算感觉没有说清楚。
在我理解,这个$b$的更新就是用更新后的$\alpha_1$或$\alpha_2$,看哪个在$(0,C)$区间,就用KKT条件2式即$(15)$直接计算$b$;如果两个$\alpha$都是0或$C$,则取依然用$(15)$计算两个$b$,取这两个$b$的平均值。
我的疑问是:首先,更新完$\alpha_1,\alpha_2$后,$\alpha_1,\alpha_2$是否保证满足$(15),(16)$式呢,也就是没说明能不能用$(15)$来算$b$?其次,假设它们更新完后满足$(15),(16)$式,但是如果$\alpha_1,\alpha_2$都不在$(0,C)$区间为什么还能用$(15)$来算$b$呢?最后,书中只说了更新$b$,刚开始的$b$初始化为多少呢?
变量的选择
变量的选择就是先遍历所有的$\alpha_i$,查看哪个$\alpha_i$违反$(17)$最严重,作为待更新的$\alpha_1$;然后再选择使$(19)$中的$|E_1-E_2|$最大的$\alpha_2$,以使$\alpha_2$变化最大。
SVM——支持向量机(完整)的更多相关文章
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- Python实现SVM(支持向量机)
Python实现SVM(支持向量机) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end ...
- SVM支持向量机的基本原理
SVM支持向量机的基本原理 对于很多分类问题,例如最简单的,一个平面上的两类不同的点,如何将它用一条直线分开?在平面上我们可能无法实现,但是如果通过某种映射,将这些点映射到其它空间(比如说球面上等), ...
- 6-11 SVM支持向量机2
SVM支持向量机的核:线性核.进行预测的时候我们需要把正负样本的数据装载在一起,同时我们label标签也要把正负样本的数据全部打上一个label. 第四步,开始训练和预测.ml(machine lea ...
- 6-10 SVM支持向量机1
都是特征加上分类器.还将为大家介绍如何对这个数据进行训练.如何训练得到这样一组数据. 其实SVM支持向量机,它的本质仍然是一个分类器.既然是一个分类器,它就具有分类的功能.我们可以使用一条直线来完成分 ...
- SVM 支持向量机算法-实战篇
公号:码农充电站pro 主页:https://codeshellme.github.io 上一篇介绍了 SVM 的原理和一些基本概念,本篇来介绍如何用 SVM 处理实际问题. 1,SVM 的实现 SV ...
- paper 25 :SVM支持向量机是什么意思?
转载来源:https://www.zhihu.com/question/21094489 作者:余洋链接:https://www.zhihu.com/question/21094489/answer/ ...
- SVM(支持向量机)算法
第一步.初步了解SVM 1.0.什么是支持向量机SVM 要明白什么是SVM,便得从分类说起. 分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向 ...
- SVM支持向量机
支持向量机(Support Vector Machine,SVM)是效果最好的分类算法之中的一个. 一.线性分类器: 一个线性分类器就是要在n维的数据空间中找到一个超平面,通过这个超平面能够把两类数据 ...
随机推荐
- 配置secondarynamenode主机名masters
1.配置hadoop的secondarynamenode,配置内容如下 node2 本文转自 素颜猪 51CTO博客,原文链接:http://blog.51cto.com/suyanzhu/19592 ...
- UDT的Sender和Receiver
Sender算法 数据结构和变量: Sender's Loss List:发送方的loss list用来存储丢失包的序列号,序列号来自于两个地方,一是receiver通过NAK包反馈回来,二是超时事件 ...
- 使用PHP-Beast加密你的PHP源代码
PHP-Beast是一个PHP源码加密的模块,其使用DES算法加密,用户可以自定义加密的key来加密源代码. 1. PHP-Beast的安装 $ wget https://github.com/lie ...
- python(面向对象-类封装调用)
一.面对对象思想 (1)大家肯定听过 Python 中”一切皆对象“的说法,但可能并不了解它的具体含义,只是在学习的时候听说 Python 是面向对象的编程语言,本节将向大家详细介绍 Python 面 ...
- 5分钟入门pandas
pandas是在数据处理.数据分析以及数据可视化上都有比较多的应用,这篇文章就来介绍一下pandas的入门.劳动节必须得劳动劳动 1. 基础用法 以下代码在jupyter中运行,Python 版本3. ...
- Flutter 打包Android APK 笔记与事项
获取一个KEY 首先要获取 你的 打包应用的一个 key ,这一步其实和 在AndroidStudio 上打包 APK 一样,都是要注册一个本地的 key,key 其实也就是 jks文件啦. 如果已经 ...
- SpringBoot + MybatisPlus3.x 代码生成
主要参考另外两篇博文,这里表示感谢 参考一(mybatisplus3.x分页) : https://www.jianshu.com/p/2ec9337dc2b0 参考二(mybatisplus2.x升 ...
- G. 神圣的 F2 连接着我们 线段树优化建图+最短路
这个题目和之前写的一个线段树优化建图是一样的. B - Legacy CodeForces - 787D 线段树优化建图+dij最短路 基本套路 之前这个题目可以相当于一个模板,直接套用就可以了. 不 ...
- spring内嵌jetty容器,实现main方法启动web项目
Jetty 是一个开源的servlet容器,它为基于Java的web容器,例如JSP和servlet提供运行环境.Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布.开发人员可以将 ...
- Oracle触发器之替代触发器
替代触发器 替代视图增删改操作.视图可以认为成逻辑上的一张表,类似于把一个sql语句的执行结果永久的像表存储到数据 库中,视图一般用来做查询. 创建视图的语法: create view 视图名称 as ...