036.集群网络-K8S网络模型及Linux基础网络
一 Kubernetes网络模型概述
1.1 Kubernetes网络模型
- 主要区别是后者的动态端口映射会引入端口管理的复杂性,而且访问者看到的IP地址和端口与服务提供者实际绑定的不同(因为NAT的缘故,它们都被映射成新的地址或端口了),这也会引起应用配置的复杂化。
- 同时,标准的DNS等名字解析服务也不适用了,甚至服务注册和发现机制都比较复杂,因为在端口映射情况下,服务自身很难知道自己对外暴露的真实的服务IP和端口,外部应用也无法通过服务所在容器的私有IP地址和端口来访问服务。
- 所有容器都可以在不用NAT的方式下同别的容器通信。
- 所有节点都可以在不用NAT的方式下同所有容器通信,反之亦然。
- 容器的地址和别人看到的地址是同一个地址。
二 Docker网络基础
2.1 网络命名空间
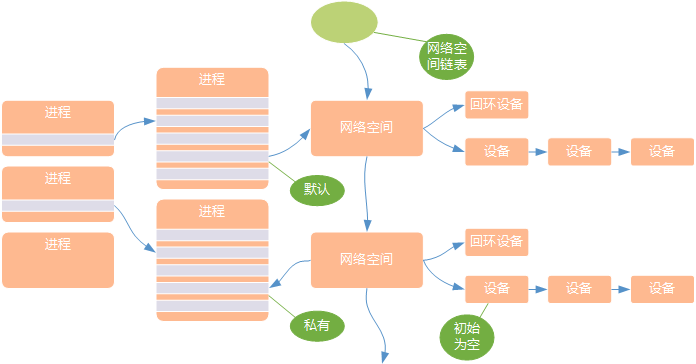
- 网络命名空间的实现

|
资源
|
含义
|
|
uts_ns
|
UTS为Unix Timessharing System的简称,包含内存名称、脚本、版本、底层体系结构等信息。
|
|
ipc_ns
|
所有与进程通信(IPC)有关的信心。
|
|
nmt_ns
|
当前装载的文件系统。
|
|
pid_ns
|
有关进程ID的信息。
|
|
user_ns
|
资源配额的信息。
|
|
net_ns
|
网络信息。
|
- 网络命名空间操作
1 [root@k8smaster01 ~]# ip netns add mytestns #创建命名空间
2 [root@k8smaster01 ~]# ip netns exec mytestns <command> #进入命名空间bash
3 [root@k8smaster01 ~]# ip netns exec mytestns bash #进入命名空间bash
4 [root@k8smaster01 ~]# exit #退出命名空间
5 [root@k8smaster01 ~]# ip link set <device> netns mytestns #转移设备
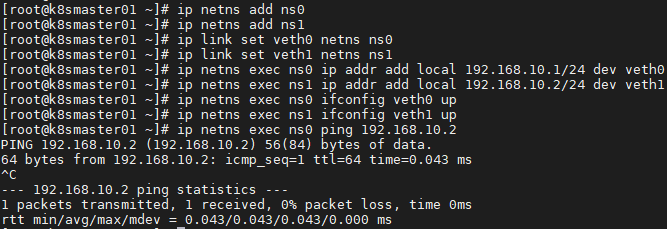
2.2 Veth设备对

- veth pair操作
1 [root@k8smaster01 ~]# ip link add veth0 type veth peer name veth1 #创建veth设备对
2 [root@k8smaster01 ~]# ip link show | grep veth #当前查看veth
3 [root@k8smaster01 ~]# ip netns add ns0
4 [root@k8smaster01 ~]# ip netns add ns1 #创建命名空间
5 [root@k8smaster01 ~]# ip link set veth0 netns ns0
6 [root@k8smaster01 ~]# ip link set veth1 netns ns1 #veth移入命名空间
7 [root@k8smaster01 ~]# ip netns exec ns0 ip link show #进入命名空间查看veth
8 [root@k8smaster01 ~]# ip netns exec ns0 ip addr add local 192.168.10.1/24 dev veth0
9 [root@k8smaster01 ~]# ip netns exec ns1 ip addr add local 192.168.10.2/24 dev veth1 #设置对应的IP
10 [root@k8smaster01 ~]# ip netns exec ns0 ifconfig veth0 up
11 [root@k8smaster01 ~]# ip netns exec ns1 ifconfig veth1 up #开启设备
12 [root@k8smaster01 ~]# ip netns exec ns0 ping 192.168.10.2 #连通性测试
1 [root@k8smaster01 ~]# ip netns exec ns0 ethtool -S veth0
2 NIC statistics:
3 peer_ifindex: 9
4 [root@k8smaster01 ~]# ip netns exec ns1 ip link | grep 9

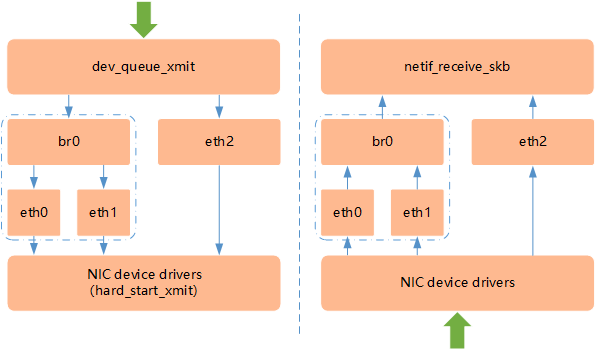
2.3 网桥
- Linux网桥的实现
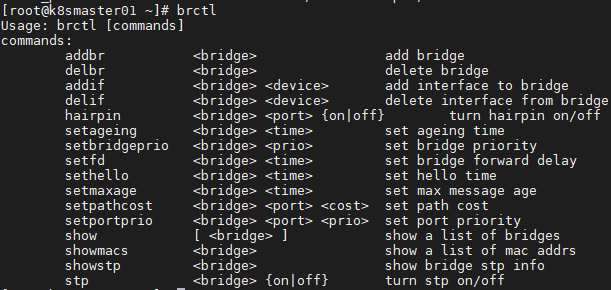
- 网桥的常用操作命令
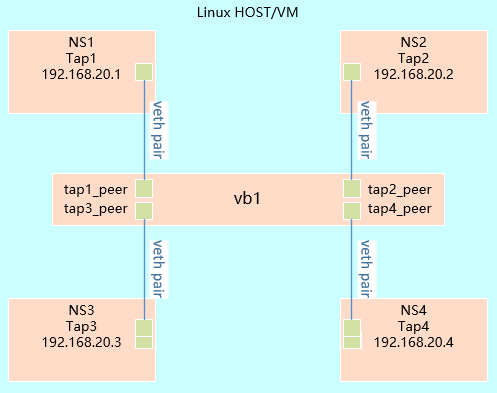
1 [root@k8smaster01 ~]# ip link add tap1 type veth peer name tap1_peer
2 [root@k8smaster01 ~]# ip link add tap2 type veth peer name tap2_peer
3 [root@k8smaster01 ~]# ip link add tap3 type veth peer name tap3_peer
4 [root@k8smaster01 ~]# ip link add tap4 type veth peer name tap4_peer
5 #创建veth pair
6 [root@k8smaster01 ~]# ip netns add ns1
7 [root@k8smaster01 ~]# ip netns add ns2
8 [root@k8smaster01 ~]# ip netns add ns3
9 [root@k8smaster01 ~]# ip netns add ns4
10 #创建namespace
11 [root@k8smaster01 ~]# ip link set tap1 netns ns1
12 [root@k8smaster01 ~]# ip link set tap2 netns ns2
13 [root@k8smaster01 ~]# ip link set tap3 netns ns3
14 [root@k8smaster01 ~]# ip link set tap4 netns ns4
15 #tap和namespace关联
16 [root@k8smaster01 ~]# brctl addbr br1 #创建桥
17 [root@k8smaster01 ~]# brctl addif br1 tap1_peer
18 [root@k8smaster01 ~]# brctl addif br1 tap2_peer
19 [root@k8smaster01 ~]# brctl addif br1 tap3_peer
20 [root@k8smaster01 ~]# brctl addif br1 tap4_peer
21 #把相应的tap添加至bright中
22 [root@k8smaster01 ~]# ip netns exec ns1 ip addr add local 192.168.20.1/24 dev tap1
23 [root@k8smaster01 ~]# ip netns exec ns2 ip addr add local 192.168.20.2/24 dev tap2
24 [root@k8smaster01 ~]# ip netns exec ns3 ip addr add local 192.168.20.3/24 dev tap3
25 [root@k8smaster01 ~]# ip netns exec ns4 ip addr add local 192.168.20.4/24 dev tap4
26 #配置相应IP地址
27 [root@k8smaster01 ~]# ip link set br1 up
28 [root@k8smaster01 ~]# ip link set tap1_peer up
29 [root@k8smaster01 ~]# ip link set tap2_peer up
30 [root@k8smaster01 ~]# ip link set tap3_peer up
31 [root@k8smaster01 ~]# ip link set tap4_peer up
32 [root@k8smaster01 ~]# ip netns exec ns1 ip link set tap1 up
33 [root@k8smaster01 ~]# ip netns exec ns2 ip link set tap2 up
34 [root@k8smaster01 ~]# ip netns exec ns3 ip link set tap3 up
35 [root@k8smaster01 ~]# ip netns exec ns4 ip link set tap4 up
36 #将bright和tap设置为up
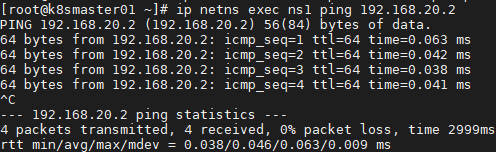
37 [root@k8smaster01 ~]# ip netns exec ns1 ping 192.168.20.2 #互ping
2.4 iptables和Netfilter
- iptables规则
- filter:实现防火墙功能;
- nat:实现NAT功能;
- mangle:实现流量整形。
- iptables-save: 按照命令的方式打印iptables的内容。
- iptables-vnL: 以另一种格式显示Netfilter表的内容。
- Netfilter规则
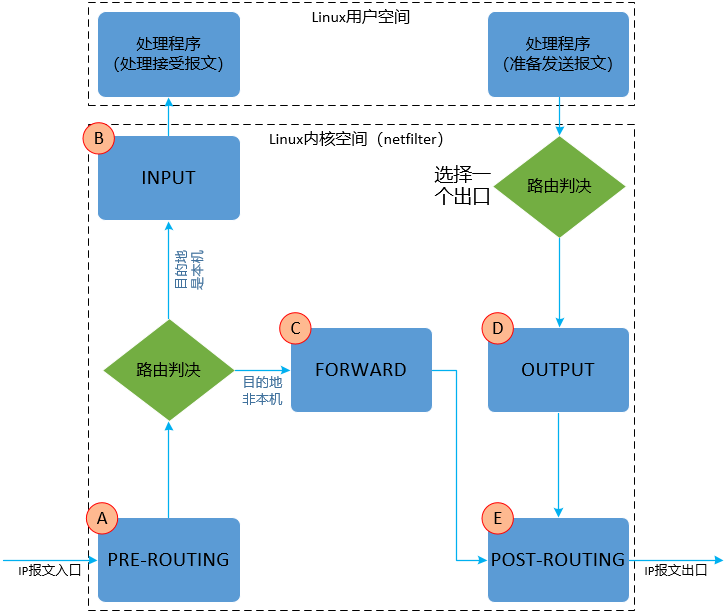
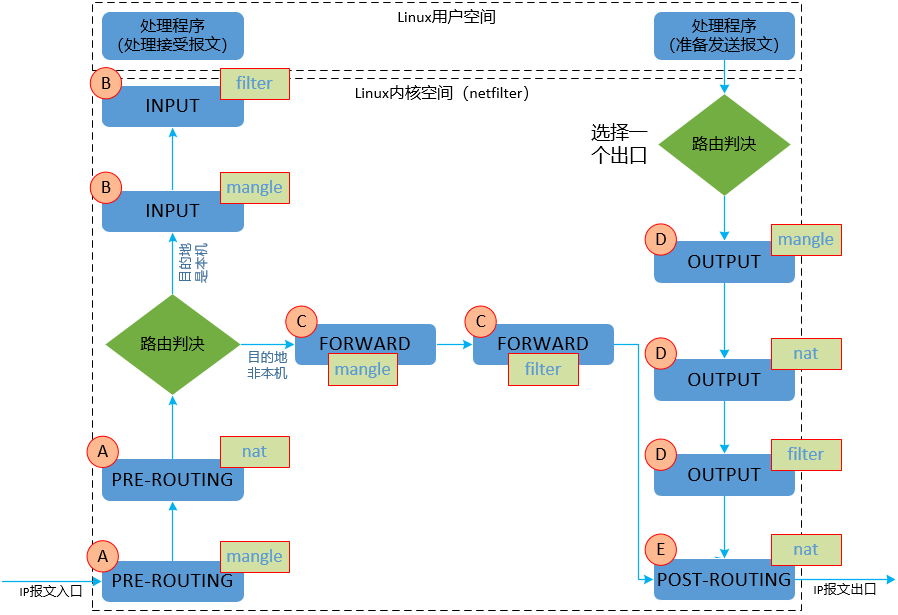
- PREROUTING:报文进入网络接口尚未进入路由之前的时刻;
- INPUT:路由判断是本机接收的报文,准备从内核空间进入到用户空间的时刻;
- FORWARD:路由判断不是本机接收的报文,需要路由转发,路由转发的那个时刻;
- OUTPUT:本机报文需要发出去 经过路由判断选择好端口以后,准备发送的那一刻 ;
- POSTROUTING:FORWARD/OUTPUT 已经完成,报文即将出网络接口的那一刻 。
|
表名
|
时刻点
|
|
mangle
|
PREROUTING, INPUT, FORWARD, OUTPUT
|
|
nat
|
PREROUTING, OUTPUT, POSTROUTING
|
|
filter
|
INPUT, FORWARD, OUTPUT
|
2.5 路由
- 目的IP地址:此字段表示目标的IP地址。这个IP地址可以是某主机的地址,也可以是一个网络地址。如果这个条目包含的是一个主机地址,那么它的主机ID将被标记为非零;如果这个条目包含的是一个网络地址,那么它的主机ID将被标记为零。
- 下一跳路由器的IP地址:若并非最终目的的路由器,则该条目给出的下一个路由器的地址用来转发在相应接口接收到的IP数据报文。
- 标志:这个字段提供了另一组重要信息,例如,目的IP地址是一个主机地址还是一个网络地址。此外,从标志中可以得知下一个路由器是一个真实路由器还是一个直接相连的接口。
- 网络接口规范:为一些数据报文的网络接口规范,该规范将与报文一起被转发。
- 路由表的创建
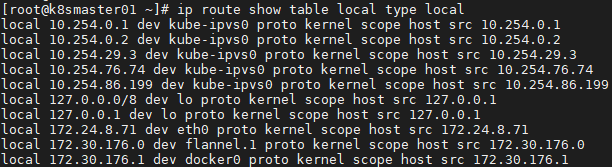
- 路由表的查看
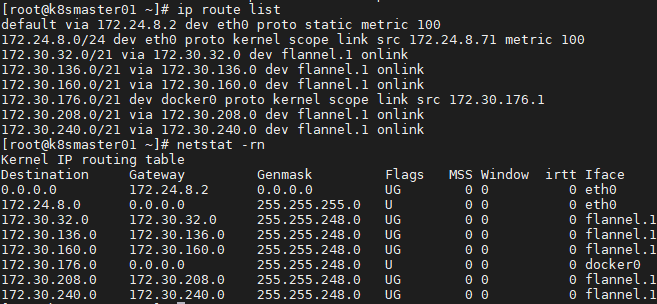
036.集群网络-K8S网络模型及Linux基础网络的更多相关文章
- Linux学习笔记(9)linux网络管理与配置之一——Linux基础网络命令与学习大纲(0)
大纲目录 0.常用linux基础网络命令 1.配置主机名 2.配置网卡信息与IP地址 3.配置DNS客户端 4.配置名称解析顺序 5.配置路由与默认网关 6.双网卡绑定 [1] ping [2]net ...
- Linux基础网络配置
目录 Linux基础网络配置 参考 IP配置 Route配置 DNS指向 ss命令 *网络排查工具 Linux基础网络配置
- 038.集群网络-K8S网络实现
一 Kubernetes网络实现 1.1 Kubernetes网络优势 在实际的业务场景中,业务组件之间的关系十分复杂,微服务的理念更是让应用部署的粒度更加细小和灵活.为了支持业务应用组件的通信,Ku ...
- 040.集群网络-CNI网络模型
一 CNM网络模型 1.1 网络模型 生产环境中,跨主机容器间的网络互通已经成为基本要求,更高的要求包括容器固定IP地址.一个容器多个IP地址.多个子网隔离.ACL控制策略.与SDN集成等.目前主流的 ...
- 041.Kubernetes集群网络-K8S网络策略
一 Kubernetes网络策略 1.1 策略说明 为实现细粒度的容器间网络访问隔离策略,Kubernetes发布Network Policy,目前已升级为networking.k8s.io/v1稳定 ...
- Linux 基础网络设置
一.查看以及测试网络 查看及测试网络配置是管理Linux网络服务的第一步,本节将学习Linux系统中的网络查看以及测试命令.其中讲解的大多数命令以普通用户权限就可以完成操作,但是普通用户在执行&quo ...
- Linux基础: 网络命令和进程管理
netstat lsof ps pstree pkill/kill (了解jenkins git,排查环境) 查询服务器之间是否有链接(netstat -an) 某个服务是否启动(了解服务对应的 ...
- Linux基础网络设置
查看Linux网络参数 ifconfig—-查看网络接口 > [root@localhost ~]# ifconfig eth1 Link encap:Ethernet HWaddr 00:0C ...
- Linux基础网络搭建实验
一.实验目标 利用3台虚拟机,搭建vmnet2和vmnet3两个host-only网络,实现两个网络的互联 二.实验环境 内网 外网 网关 IP 192.168.0.10/24 202.3.4.1 ...
随机推荐
- log4j简单的使用
1.引入log4j.jar包 2.在类中使用 package com.donghai.log4j; import org.apache.log4j.Logger; public class LogTe ...
- jstl之核心标签
JSP 标准标签库(JSTL) JSP标准标签库(JSTL)是一个JSP标签集合,它封装了JSP应用的通用核心功能. JSTL支持通用的.结构化的任务,比如迭代,条件判断,XML文档操作,国际化标签, ...
- Ionic3学习笔记(十三)HttpClient 实现 HTTP 请求以及踩过的一些坑
本文为原创文章,转载请标明出处 目录 猫眼API HttpClient 实现 HTTP 请求 安装 HttpClientModule 模块 创建 provider 创建 page 一些坑 坑1: 未在 ...
- html中的select下拉框
<select name="effective"> <option value="">请选择</option> <op ...
- java 字符串转日期格式
/** * 字符串转日期格式 * */ public static Date date(String date_str) { try { Calendar zcal = Calendar.getIns ...
- ES6的模块暴露与模块引入
ES6的模块暴露和引入可以让我们实现模块化编程,以下列出ES6的几种模块暴露与引入的方式与区别. 1.ES6一共有三种模块暴露方法 多行暴露 模块1:module1.js //多行暴露 export ...
- python 有关堡垒机的那些事
堡垒机为了保证系统或服务器的安全性,防止运维和开发人员胡乱操作服务器,导致不必要的损失,使用堡垒机来完成对运维和开发人员的授权.用户统一登录堡垒机账号来操作系统或服务器.堡垒机等于成了生产系统的SSO ...
- js 创建对象的多种方式
参考: javascript 高级程序设计第三版 工厂模式 12345678910 function (name) { var obj = new Object() obj.name = name o ...
- Ruby爬虫header发送cookie,nokogiri解析html数据
之前用php写过一个爬虫,同样是获取局域网的网站数据,这次我使用相同的网络环境,更低的电脑配置,使用ruby来再次爬虫,惊人的发现ruby使用自带的类库net/http爬取速度要远远超过php的cur ...
- docker mysql5.7.16 中文乱码
有部分同学会遇到,在centos上Docker-MySQL没乱码,但是在fedora系统上的docker-mysql会有乱码问题,这兴许是docker-mysql的问题,这里的bug我们不去追究,这里 ...