开窗函数_ROW_NUMBER() / RANK() / DENSE_RANK() / NTILE() ------4个排名函数训练_1
排名函数(训练,其实从SQL2005时就已经被引入)
/*
SQL Server 2012从零开始学_7.8 排序函数
*/ --DROP TABLE fruits
GO
Create table fruits(
s_id int,
f_name char(20)
) insert into fruits(s_id,f_name)
values('','apple'),
('','blackberry'),
('','cherry'),
('','orange'),
('','banana'),
('','grape'),
('','coconut'),
('','apricot'),
('','berry'),
('','lemon'),
('','melon'),
('','blackberry') select * from fruits
查询结果:
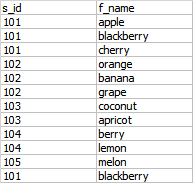
-----------------------------------------------------------
--ROW_NUMBER() --添加序号
select row_number() over (order by s_id asc) as rowid,s_id,f_name
from fruits
GO
-----------------------------------------------------------
--RANK() 排序(对关联数据字段的值相同数据,则名次相同,隐形计算用了 sum(RankID))
SELECT rank() over (order by s_id asc) as RankID,S_ID,f_name
FROM fruits; ----注意知识点,到第1个RankID=5时,ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
-----------------------------------------------------------
--DENSE_RANK() --排名,只是排名不跳顺序号(用递增号)
SELECT DENSE_RANK() OVER(ORDER BY s_id) as DENSEID,s_id,f_name
FROM fruits
-----------------------------------------------------------
--NTILE()
SELECT NTILE(5) OVER (ORDER BY s_id asc) as NTILEID,s_id,f_name
FROM fruits
-----------------------------------------------------------
SELECT NTILE(4) OVER (ORDER BY s_id ASC) AS NTILEID,s_id,f_name
FROM fruits;
-----------------------------------------------------------
--再将上面的组合到一起便于对比理解NTILE()
--函数是将有序分区中的行分发到指定个数的组中,各个组有编号,编号从1开始,类似'分区'一样 ,分为几个区,一个区会有多少个。
SELECT S_ID,f_name,
row_number() over (order by s_id asc) as rowid,
rank() over (order by s_id asc) as RankID,
DENSE_RANK() OVER(ORDER BY s_id) as DENSEID,
NTILE(5) OVER (ORDER BY s_id asc) as NTILEID,
NTILE(4) OVER (ORDER BY s_id asc) as NTILEID1, --分成4组,刚好能被12整除,每组3个,12条记录 = 4组 * 3条/组
NTILE(6) OVER (ORDER BY s_id asc) as NTILEID2, --分成6组,刚好能被12整除,每组2个,12条记录 = 6组 * 2条/组
NTILE(7) OVER (ORDER BY s_id asc) as NTILEID3
FROM fruits;
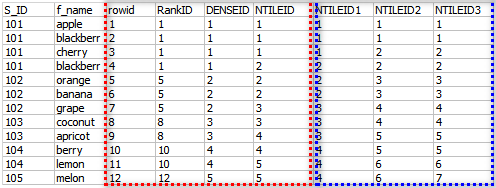
--红色虚线框中分别说明了函数的用法(将它们当做排序来理解,其次理解为排序后开窗):
ROW_NUMBER() ------>只是添加一个递增行序号
RANK() ------>排序(结合S_ID列来看),并列的名次(在S_ID不相同时,跳号)
DENSE_RANK() ------>排序(结合S_ID列来看),并列的名次(在S_ID不相同时,不跳号)
NTILE() ------>似乎理解,还不好讲解出来,但后面排序组要比前面的要小或相同
NTILEID1, NTILEID2, NTILEID3(只是试用了NTILE + ID作为了标题列头)
------------------------------------------------------------------------------------------------------------------------
下面是CTE、及窗口函数的示例
问题: 酒店每天要对在同一时间段内服务房间最多的一名服务生进行奖励。表 19-1 列出了一天中酒店服务生所服务的房间号和服务时间。
只要第 2 个房间的服务开始时间小于或等于第 1 个房间,并且结束时间大于第 1个房间的开始时间
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
/*
学习本篇的目的: 窗口函数(学习前先来做这个例子)
*/ CREATE TABLE Waiters
(
room_id int,
waiter_name char(20),
start_time datetime,
end_time datetime
);
INSERT INTO Waiters VALUES
(1,'张岚','2009-02-01 11:30','2009-02-01 13:30'),
(2,'张岚','2009-02-01 11:40','2009-02-01 13:15'),
(3,'孙静','2009-02-01 11:45','2009-02-01 14:20'),
(4,'孙静','2009-02-01 11:39','2009-02-01 13:20'),
(5,'孙静','2009-02-01 11:49','2009-02-01 14:16'),
(6,'孙静','2009-02-01 10:37','2009-02-01 11:00'),
(3,'孙静','2009-02-01 17:45','2009-02-01 18:20'),
(4,'孙静','2009-02-01 17:39','2009-02-01 18:25'),
(5,'孙静','2009-02-01 17:49','2009-02-01 18:36'),
(6,'孙静','2009-02-01 17:37','2009-02-01 18:40'); ---------------------------------------------------------
select datediff(dd,'2020-05-21','2020-05-12')
---------------------------------------------------------
SELECT MAX(room_id) FROM Waiters select COUNT(*) as tally FROM Waiters
---------------------------------------------------------
SELECT * FROM Waiters
--显示服务房间最多的数量
select --W1.waiter_name,
--W1.start_time,
--W1.end_time,
MAX(W1.room_id) as room_id from Waiters as W1
group by w1.waiter_name
order by w1.waiter_name
---------------------------------------------------------
--显示了服务房间的最大数量
select w1.waiter_name,
--w1.start_time,
--w1.end_time,
MAX(W1.room_id) as room_id from Waiters as w1
inner join Waiters as w2
on w1.waiter_name = w2.waiter_name
group by w1.waiter_name
order by w1.waiter_name
---------------------------------------------------------
--------------------------------------------------------
--显示每个人的服务的房间号、开始时间、结束时间
SELECT * FROM Waiters select w1.waiter_name,
w1.start_time,
w1.end_time,
MAX(W1.room_id) as room_id,
COUNT(*) as tally
from Waiters as w1
inner join Waiters as w2
on w1.waiter_name = w2.waiter_name
and w2.start_time <= w1.end_time --->>>此处理解错误,应该是: and w2.start_time <= w1.start_time
and w2.end_time > w1.start_time
group by w1.waiter_name,w1.start_time,w1.end_time,w1.room_id
order by w1.waiter_name,w1.start_time,room_id
---------------------------------------------------------
--
SELECT W1.waiter_name,
W1.start_time,
W1.end_time,
MAX(W1.room_id) AS room_id,
COUNT(*) AS tally
FROM Waiters AS W1
INNER JOIN Waiters AS W2
ON W1.waiter_name = W2.waiter_name
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
GROUP BY W1.waiter_name, W1.start_time, W1.end_time, W1.room_id
ORDER BY W1.waiter_name, W1.start_time, room_id; ---------------------------------------------------------
--得出同一时间服务房间数量最多的个数
select T1.waiter_name,MAX(T1.TALLY) as Tally
FROM
(SELECT W1.waiter_name,
W1.start_time,
W1.end_time,
COUNT(*) AS tally
FROM Waiters AS W1
INNER JOIN Waiters AS W2
ON W1.waiter_name = W2.waiter_name
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
GROUP BY W1.waiter_name, W1.start_time, W1.end_time) AS T1
GROUP BY T1.waiter_name;
---------------------------------------------------------
with T1(waiter_name,start_time,end_time,tally)
AS
(
SELECT W1.waiter_name,
W1.start_time,
W1.end_time,
COUNT(*) AS tally
FROM Waiters AS W1
INNER JOIN Waiters AS W2
ON W1.waiter_name = W2.waiter_name
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
GROUP BY W1.waiter_name, W1.start_time, W1.end_time
)
select waiter_name,MAX(tally)
from T1
group by T1.waiter_name; ---------------------------------------------------------
--使用CTE,这个是书本内容,自己独立写一次看看
WITH T1 (waiter_name, start_time, end_time, tally) -- 定义 CTE 表达式的名称和列
AS
(
SELECT W1.waiter_name,
W1.start_time,
W1.end_time,
COUNT(*) AS tally
FROM Waiters AS W1
INNER JOIN Waiters AS W2
ON W1.waiter_name = W2.waiter_name
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
GROUP BY W1.waiter_name, W1.start_time, W1.end_time
)
SELECT waiter_name, MAX(tally) AS tally
FROM T1
GROUP BY T1.waiter_name;
---------------------------------------------------------
--窗口函数使用前的预习
select waiter_name,start_time as ts
from Waiters select waiter_name,start_time as ts,+1 as type --如果是开始时间,则 type设置 为 1
from Waiters select waiter_name,end_time as ts,-1 as type --如果是结束时间,则 type设置 为 -1
from Waiters select *,
sum(type) over(partition by waiter_name order by ts,type)
---------------------------------------------------------
--
WITH T1 AS
(
SELECT waiter_name, start_time AS ts, +1 AS type
FROM Waiters
UNION ALL
SELECT waiter_name, end_time, -1 AS type
FROM Waiters
),
T2 AS
(
SELECT *, SUM(type) OVER(PARTITION BY waiter_name
ORDER BY ts, type
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
FROM T1
)
SELECT * FROM T2 --------------------------------------------------------- --窗口函数使用
with T1 as
(
select waiter_name,start_time as ts,+1 as type
from Waiters Union all select waiter_name,end_time as ts,-1 as type
from Waiters
),
T2 as
(
SELECT *, SUM(type) OVER(PARTITION BY waiter_name --sum(type),相当于在求和
ORDER BY ts, type
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt --此处cnt修改成另外一个别名便于理解: CountX
FROM T1
)
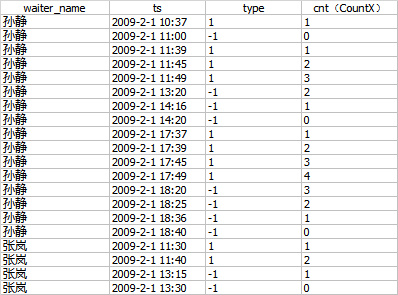
select * from T2
运行结果:
---------------------------------------------------------
--最终完整的SQL WITH T1 AS
(
SELECT waiter_name, start_time AS ts, 1 AS type
FROM Waiters
UNION ALL
SELECT waiter_name, end_time, -1 AS type
FROM Waiters
),
T2 AS
(
SELECT *, SUM(type) OVER(PARTITION BY waiter_name
ORDER BY ts, type
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
FROM T1
)
SELECT waiter_name, MAX(cnt) AS tally
FROM T2
GROUP BY waiter_name;
运行结果:
waiter_name tally
孙静 4
张岚 2
---------------------------------------------------------
--------------------------------------------------------- ---------------------------------------------------------
参考书目《SQL Server 2012从零开始学》7.8 排序函数
《锋利的SQL_第2版_张洪举_王晓文_著》
开窗函数_ROW_NUMBER() / RANK() / DENSE_RANK() / NTILE() ------4个排名函数训练_1的更多相关文章
- SQL Server中排名函数row_number,rank,dense_rank,ntile详解
SQL Server中排名函数row_number,rank,dense_rank,ntile详解 从SQL SERVER2005开始,SQL SERVER新增了四个排名函数,分别如下:1.row_n ...
- SQL Server:排名函数row_number,rank,dense_rank,ntile详解
1.Row_Number函数 row_number函数大家比较熟悉一些,因为它的用途非常的广泛,我们经常在分页与排序中用到它,它的功能就是在每一行中生成一个连续的不重复的序号 例如: select S ...
- ROW_NUMBER()/RANK()/DENSE_RANK()/ntile() over()
ROW_NUMBER()/RANK()/DENSE_RANK()/ntile() over() 今天女票问我SqlServer的四种排序,当场写了几句Sql让她了解,现把相关Sql放上来. 首先, ...
- 知方可补不足~row_number,rank,dense_rank,ntile排名函数的用法
回到目录 这篇文章介绍SQL中4个很有意思的函数,我称它的行标函数,它们是row_number,rank,dense_rank和ntile,下面分别进行介绍. 一 row_number:它为数据表加一 ...
- SQL-OVER与四种排名函数:ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()
1 SELECT orderid,custid,val, ROW_NUMBER() OVER(ORDER BY val) AS rownum, RANK() OVER(ORDER BY val) AS ...
- SQL Server - 四种排序, ROW_NUMBER() /RANK() /DENSE_RANK() /ntile() over()
>>>>英文版 (更简洁易懂)<<<< 转载自:https://dzone.com/articles/difference-between-rownum ...
- SqlServer四种排序:ROW_NUMBER()/RANK()/DENSE_RANK()/ntile() over()
首先,我们创建一些测试数据. if OBJECT_ID('Tempdb.dbo.#Tmp') is not null drop table #Tmp create table #Tmp ( name ...
- 好用的排名函数~ROW_NUMBER(),RANK(),DENSE_RANK() 三兄弟
排名函数三兄弟,一看名字就知道,都是为了排名而生!但是各自有各自的特色!以下一个例子说明问题!(以下栗子没有使用Partition By 的关键字,整个结果集进行排序) RANK 每个值一个排名,同样 ...
- sqlserver 中row_number,rank,dense_rank,ntile排名函数的用法
1.row_number() 就是行号 2.rank:类似于row_number,不同之处在于,它会对order by 的字段进行处理,如果这个字段值相同,那么,行号保持不变 3.dense_rank ...
随机推荐
- strut2登陆注册验证码
1. 生成图片和验证码 package com.jmu.code; import java.awt.Color; import java.awt.Font; import java.awt.Graph ...
- C语言基础知识(四)——位操作
一.进制基础知识 1.通常,1字节(Byte)包含8位(bit).C语言用字节表示储存系统字符集所需的大小. 2.对于一个1字节8位的二进制数,最右边(第0位)是最低阶位,最左边(第1位)是最高阶位, ...
- java中碰到的异常
mapper接口中找不到相应方法 解决:配置xml读取路径错误 org.apache.ibatis.binding.BindingException: Invalid bound statement ...
- Js 改变时间格式输出格式
朋友看到的方法,非js原生的 自己封装到 function date2str(x,y) { var z={y:x.getFullYear(),M:x.getMonth()+1,d:x.getDate( ...
- 【图像处理】利用C++编写函数,绘制灰度图像直方图
1. 简介 利用OpenCV读取图像,转换为灰度图像,绘制该灰度图像直方图.点击直方图,控制台输出该灰度级像素个数. 2. 原理 (1) 实现原理较为简单,主要利用了OpenCV读取图像,并转换为灰度 ...
- 软件攻城狮究级装B指南
引言 装B于无形,随性而动,顺道而行,待霸业功成之时,你会发现:装B是牛B最好的的试金石. -- SuperDo 第一章.人间兵器(准备工具) <论语·魏灵公>:“工欲善其事,必先利其器. ...
- Rocket - debug - Example: Write Memory
https://mp.weixin.qq.com/s/on1LugO9fTFJstMes3T2Xg 介绍riscv-debug的使用实例:使用三种方法写内存. 1. Using System Bus ...
- 使用turtle库绘制同心圆
import turtle as t t.pensize(3) t.setup(600,600,50,50) t.pencolor("yellow") t.penup() t.pe ...
- Java实现 蓝桥杯 算法训练 第五次作业:字符串排序
试题 算法训练 第五次作业:字符串排序 问题描述 输入一个小写字符串,按从小到大的顺序输出. 输入格式 bcaed 输出格式 abcde 顶格输出,中间没有空格 样例输入 一个满足题目要求的输入范例. ...
- (Java实现) 细胞
细胞 Time Limit : 3000/1000ms (Java/Other) Memory Limit : 65535/32768K (Java/Other) Total Submission(s ...