flume通过avro对接(汇总数据)
使用场景:
把多台服务器(flume generator)上面的日志汇总到一台或者几台服务器上面(flume collector),然后对接到kafka或者HDFS上

Flume Collector服务端
vim flume-server.properties
# agent1 name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 #set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # other node, slave to master
a1.sources.r1.type = avro
a1.sources.r1.bind = master
a1.sources.r1.port = # set sink to logger
a1.sinks.k1.type = logger a1.sources.r1.channels = c1
a1.sinks.k1.channel=c1
启动:
## Master
/usr/local/flume/bin/flume-ng agent –f flume-server.properties –name a1
Flume Generator客户端
vim flume-client.properties
# a1 name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 #set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = a1.sources.r1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/test.log # set sink1
#a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = master
a1.sinks.k1.port = a1.sources.r1.channels = c1
a1.sinks.k1.channel=c1
启动:
分别在slave1和slave2服务器上面启动
/usr/local/flume/bin/flume-ng agent –f flume-client.properties –name a1
启动之后,在slave1和slave2服务器上面分别执行以下操作:
#slave1
echo "wangzai slave1" > /root/test.log #slave2
echo "wangzai slave2" > /root/test.log
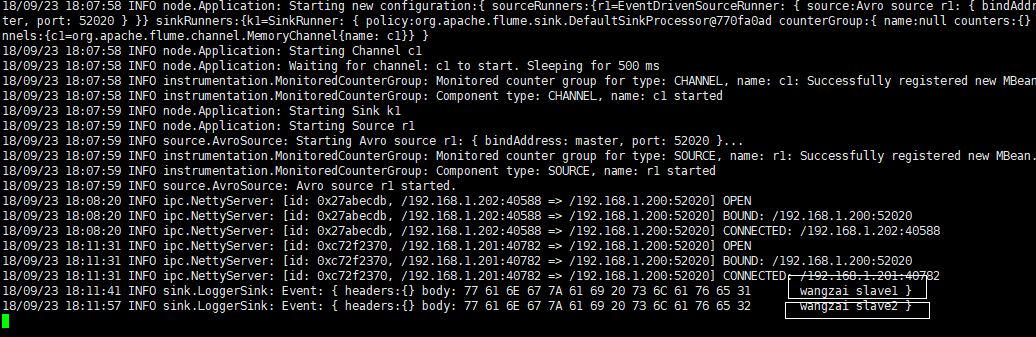
结果:
Master:
flume通过avro对接(汇总数据)的更多相关文章
- 将线上服务器生成的日志信息实时导入kafka,采用agent和collector分层传输,app的数据通过thrift传给agent,agent通过avro sink将数据发给collector,collector将数据汇集后,发送给kafka
记flume部署过程中遇到的问题以及解决方法(持续更新) - CSDN博客 https://blog.csdn.net/lijinqi1987/article/details/77449889 现将调 ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- SQLSERVER 使用 ROLLUP 汇总数据,实现分组统计,合计,小计
表结构: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, [Sex] [int] NOT NULL, ) NULL, ) NULL, , ) N ...
- 一个有趣的SQL Server 层级汇总数据问题
看SQL Server大V宋大侠的博客文章,发现了一个有趣的sql server层级汇总数据问题. 具体的问题如下: parent_id emp_id emp_nam ...
- Flume的Avro Sink和Avro Source研究之一: Avro Source
问题 : Avro Source提供了怎么样RPC服务,是怎么提供的? 问题 1.1 Flume Source是如何启动一个Netty Server来提供RPC服务. 由GitHub上avro-rpc ...
- SQL学习之汇总数据之聚集函数
一. 1.我们经常需要汇总数据而不用把他们实际检索出来,为此SQL提供了专门的函数,以便于分析数据和报表生成,这些函数的功能有: (1)确定表中行数(或者满足单个条件或多个条件或包含某个特定值的行数) ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
- MySQL汇总数据
汇总数据 有时,数据本身是不上台面的操作数据表.但在摘要表中的数据.例如 数据的一列的平均值.极大值.至少值等一下. 对于这些频繁使用的数据的处理的概要,MySQL它提供了一个函数来处理. SQL聚集 ...
- 介绍一种非常好用汇总数据的方式GROUPING SETS
介绍 对于任何人而言,用T-SQL语句来写聚会查询都是工作中重要的一环.我们大家也都很熟悉GROUP BY子句来实现聚合表达式,但是如果打算在一个结果集中包含多种不同的汇总结果,可能会比较麻烦.我将举 ...
随机推荐
- Linux 下配置网卡的别名即网卡子IP的配置
what 什么是ip别名?用windows的话说,就是为一个网卡配置多个ip.when 什么场合增加ip别名能派上用场?布网需要.多ip访问测试.特定软件对多ip的需要...and so on. ho ...
- 使用类/结构体时关于ZeroMomery用法错误
今天同事在写了如下结构体: typedef struct _tagInfo { std::list<int> lst; std::vector<int> nVec; } INF ...
- js中replace()方法
str.replace(/Microsoft/g, "W3School");//全局替换 str.replace(/Microsoft/, "W3School" ...
- openstack将本地实例迁移至ceph存储中
需求: 最近在openstack上线了ceph存储,创建虚拟机和云硬盘都基于ceph卷进行存储和创建,但是之前openstack用的是本地存储,创建的所有实例都在本地文件中,当实例重启之后,opens ...
- ThinkPHP的增删改查!
对表的操作: 增加:M('表名')->add($data); (可以是数组) 删除:M('表名')->delete($data); (不可以是数组,删除多个有另外的方法) 修改:M('表 ...
- U盘安装Win7系统,遇到硬盘鼠标键盘失灵等情况,如何安装U盘中加入USB3.0驱动的支持
U盘安装系统出现鼠标键盘不能使用,在intel六代处理器平台,安装过程中会出现安装原生镜像不能识别或者鼠标键盘不能使用等情况,可以参考以下方法进行. 风险提示:重装或升级系统会导致系统盘数据丢失,建议 ...
- jconsole远程连接超时问题解决方法
根据oracle网站上的文档,本地使用jconsole没有问题.但当我从windows连接到linux时(centos5.4)时,老是连接不上). 原因是Linux上JVM给jconsole的RMI配 ...
- 如何通过命令在Ubuntu中安装PyCharm
对于Ubuntu 16.10和Ubuntu 17.04,通过Ctrl + Alt + T打开终端,或通过从应用启动器搜索“terminal”,打开后,执行以下步骤: 安装: 1.通过命令添加PPA存储 ...
- ebay商品基本属性组合成数据表格式,可用上传到系统递交数据
该刊登表设计是利用VB写的,当时因为两个系统的数据不能直接对接,又copy并且组合SKU,一个表格一个表格填写,比较麻烦,还好刊登系统可以允许用excel表格上传数据 所以就下好模板,学了VB语言,在 ...
- 理论实践:循序渐进理解AWR细致入微分析性能报告
1. AWR 概述 Automatic Workload Repository(AWR) 是10g引入的一个重要组件.在里面存贮着近期一段时间内(默认是7天)数据库活动状态的详细信息. AWR 报告是 ...