python基础之递归、二分法
一 递归
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,
函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,
栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,
所以,递归调用的次数过多,会导致栈溢出)
注:栈遵循先进后出,先吃后拉原则。
递归能干得事,while True都能干。
查看和修改栈的大小:
>>> import sys
>>> sys.getrecursionlimit()
1000
>>>
>>> sys.setrecursionlimit(10000)
>>> sys.getrecursionlimit()
10000
>>>
递归初识:
part1:
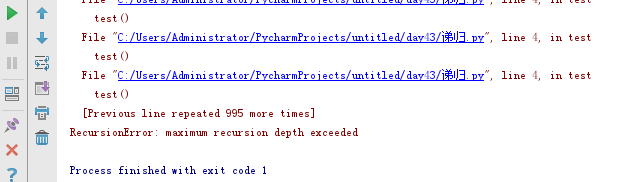
def test():
test()
test()
输出结果:
#part2:
#:有一个明确的结束条件
def test(n):
print(n)
n = n -1
if n >=1:
test(n)
test(5)
输出结果:

#part3
def calc(n):
print(n)
if int(n/2)==0:
return n
return calc(int(n/2))
print('********',calc(10))
输出结果:

#part4
# 5 = 5*4*3*2*1(实现阶乘)
def func(num):
if num==1:
return 1
if num>1:
return func(num-1)*num
k = func(5)
print(k)
输出结果:

分析过程:
"""
def func(num):
if num==:
return
if num>:
return func(num-)*num
k = func()
print(k) #最后k等于120 def func():
if ==:
return
if >:
return func()* #返回时func() 等于 , func()* def func():
if ==:
return
if >:
return func()* #返回时func() 等于 , func()* 等于 def func():
if ==:
return
if >:
return func()* #返回时func() 等于 , func()* 等于 def func():
if ==:
return
if >:
return func()* #返回时func() 等于 , func()* 等于 def func():
if ==:
return #最终得出结论func() 等于 ,开始返回
"""
使用实例:
猜年龄游戏:
小白问小黄年龄多少,小黄说比小蓝大两岁。又问小蓝年龄多少,小蓝说比小红大两岁。
又问小红年龄多少,小红说比小绿大两岁。又问小绿年龄多少,小绿说比小青大两岁。、
又问小青多大,小青说10岁了。问小黄现在多大?
分析:
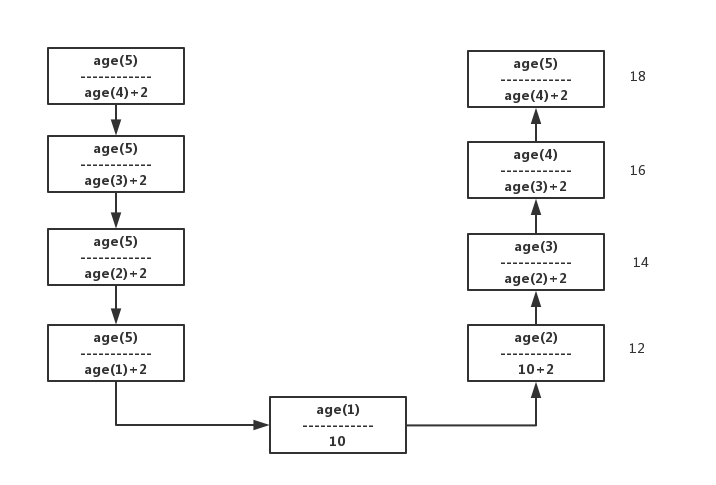
age(5)=age(4)+2 n=5 age(n)=age(n-1)+2
age(4)=age(3)+2 n=4 age(n)=age(n-1)+2
age(3)=age(2)+2 n=3 age(n)=age(n-1)+2
age(2)=age(1)+2 n=2 age(n)=age(n-1)+2
age(1)=10 n=1 age(n)=10
n=1 res=10
n>1 res=age(n-1)+2
答案:
def age(n):
if n == 1:
return 10
else:
return age(n-1)+2 print(age(5))
二 二分法
猜数字是否在列表内游戏:
# data=[]
# for i in range(1,100000,2):
# data.append(i) data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
# num=19
# i=0
# while True:
# if num == data[i]:
# print('find it')
# break
# i+=1 def search(num,data):
print(data)
if len(data) > 1:
#二分
mid_index=int(len(data)/2)
mid_value=data[mid_index]
if num > mid_value: #19>18
#num在列表的右边
data=data[mid_index:] #data[0:]-->[18]
search(num,data)
elif num < mid_value:
#num在列表的左边
data=data[:mid_index]
search(num,data)
else:
print('find it')
return
else:
if data[0] == num:
print('find it')
else:
print('not exists') # search(9527,data)
search(15,data)
# search(1,data)
python基础之递归、二分法的更多相关文章
- 十四. Python基础(14)--递归
十四. Python基础(14)--递归 1 ● 递归(recursion) 概念: recursive functions-functions that call themselves either ...
- python基础----递归函数(二分法、最大深度递归)
递归函数 定义:在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. #例子1 # age()=age()+ n= age(n)=age(n-)+ # age()=ag ...
- python之路--递归, 二分法
一 . 递归 自己调用自己, 递归的入口(参数) 和 出口(return), 树形结构的遍历. def func(): print("我是递归") func() func() ...
- python基础之递归,匿名,内置函数
递归函数: 什么是递归函数? 函数递归调用:在调用一个函数的过程中,又直接或间接地调用了该函数本身. 递归必须要有两个明确的阶段: ①递推:一层一层递归调用下去,强调:每进入下一层问题规模减少 ②回溯 ...
- python基础之递归,声明式编程,面向对象(一)
在函数内部,可以调用其他函数,如果一个函数在内部调用自身本身,这个函数就是递归函数.递归效率低,需要在进入下一次递归时保留当前的状态,解决方法是尾递归,即在函数的最后一步(而非最后一行)调用自己,但是 ...
- python基础-函数递归
函数递归 概念:直接或间接地重复调用函数本身,是一种函数嵌套调用的表现形式. 直接调用:在函数内部,直接调用函数本身 def foo(): print("这是foo函数") foo ...
- Python 基础之递归 递归函数 尾递归 斐波那契
1.递归函数 定义:自己调用自己的函数递:去归:回有去有回是递归#(1)简单的递归函数def digui(n): print(n) if n > 0: digui(n- ...
- 【python基础】第19回 多层,有参装饰器 递归 二分法
本章内容概要 1. 多层装饰器 2. 有参装饰器 3. 递归函数 4. 算法(二分法) 本章内容详解 1. 多层装饰器 1.1 什么是多层装饰器 多层装饰器是从下往上依次执行,需要注意的是,被装饰的函 ...
- Python基础(协程函数、内置函数、递归、模块和包)-day05
写在前面 上课第五天,打卡: 凭着爱,再回首: 一.协程函数(生成器:yield的表达式形式) 1.yield 的语句形式: yield 1 - 这种方式在 Python基础(函数部分)-day04 ...
随机推荐
- 其它系统与domino系统单点登录的实现方式
其它系统与domino系统单点登录的实现方式 [背景] 随着企业中业务不断增多,用户处理不同的业务则须要频繁的切换不同的系统进行操作.而用户则须要记住各个系统的username.password ...
- R语言绘图布局
在R语言中,par 函数可以设置图形边距,其中oma 参数设置outer margin, mar 参数设置margin, 这些边距有什么不同呢,通过box函数可以直观的看到 box 默认在当前图形绘制 ...
- php如何定时执行任务
PHP的实现决定了它没有Java和.Net这种AppServer的概念, 而http协议是一个无状态的协议, php只能被用户触发, 被调用, 调用后会自动退出内存, 没有常驻内存, 就没有办法准确的 ...
- hbase集群部分节点HRegionServer启动后自动关闭的问题
参考链接 http://f.dataguru.cn/thread-209058-1-1.html 我有4HRegionServer节点,1个master,其中3个是unbuntu 系统,2个节点是ce ...
- 如何用ChemDraw建立多中心结构
通过调整ChemDraw多中心机构的连接可绘制有意义的络合物结构,建立中心原子和络合配体后,利用多中心化学键连接上述结构即可.以下内容将具体介绍如何用ChemDraw建立多中心结构. 一.多中心键和多 ...
- 如何使用ChemDraw改变说明文本
作为一款全球领先的化学绘图工具,ChemDraw能够绘制各种复杂的结构方程式.ChemDraw软件还增加了新的绘图工具,能够方便化学领域的图形绘制.本教程将向大家讲解如何在ChemDraw中改变说明文 ...
- failed to push some refs to 'git@github.com:*/learngit.git'
https://jingyan.baidu.com/article/f3e34a12a25bc8f5ea65354a.html 出现错误的主要原因是github中的README.md文件不在本地代码目 ...
- 帝国CMS 列表模板list.var支持程序代码
1.增加模板时list.var模板需要勾选“使用程序代码”选项.如图: 2.直接添加PHP代码,不需要加<?和?>程序开始和结束标记. 3.字段值数组变量为$r,对应的字段变量为$r[字段 ...
- orcale_proceduie_function_两三栗
--获取部门树 procedure: create or replace procedure P_UTIL_TREE_ALL(P_APPL_NAME in VARCHAR2, P_HIERARCHY_ ...
- ios开发之--ZHPickView输出格式不出现 +0000
这样写就不会输出 +0000了 NSDate *select = [_datePicker date]; NSDateFormatter *dateFormatter = [[NSDateFormat ...