利用python 学习数据分析 (学习一)
内容学习自:
Python for Data Analysis, 2nd Edition
就是这本
纯英文学的很累,对不对取决于百度翻译了
前情提要:
各种方法贴:
https://www.cnblogs.com/baili-luoyun/p/10250177.html
本内容主要讲的是
数组和矢量的计算
一: 创建数组
传入内容(序列化对象),转化成数组
np.array()
1:单维数组 (和列表没什么两样)
单维数组
# data1 = [6, 7, 8, 9, 10, 1, 2]
# arr1 =np.array(data1)
# print(arr1)
>>>>
[ 6 7 8 9 10 1 2]
2:多维数组
data2 =[[1,2,3,4],[5,6,7,8]]
arr2 =np.array(data2)
l =arr2.shape #返回维度
print(arr2)
print(l)
>>>>>
[[1 2 3 4]
[5 6 7 8]]
(2, 4)
3:系统内置函数np.arange(横,纵)
data3 =np.arange(1,15)
print(data3)
>>>>>
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
4:生成对角线数组
data4 =np.eye(3,3)
print(data4) >>>
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
二:数组之间的运算(矢量化运算可以直接参与赋值)
1:矢量可以直接参运算
* 乘法 lis =[[1,2,3],[4,5,6]]
data1 =np.array(lis)
print(data1)
#矢量化运算可以直接参与运算
l2 =data1*data1
print(l2) -减法
l3 =data1+data1
print(l3) >>>>>
[[1 2 3]
[4 5 6]]
[[ 1 4 9]
[16 25 36]]
[[ 2 4 6]
[ 8 10 12]]
2:数组与标量之间可以直接传递到数组的每个内容
l4 =1/data1
print(l4) >>>>
[[1. 0.5 0.33333333]
[0.25 0.2 0.16666667]]
3:数组相同维度的比较(维度不同则报错)
data2 =np.array([[3,2,1],[6,5,4]])
l4 =data1>data2
print(l4)
>>>> [[False False True]
[False False True]]
三:数组的切片和索引
1:一维数组
print(arr1[1])
print(arr1[4])
print(arr1[:4])
arr1[1]=888 #给对应索引位置换值
print(arr1)
arr1[:] =55 # 给所有索引位置换值
print(arr1)
>>>>>
2
5
[1 2 3 4]
[ 1 888 3 4 5]
[55 55 55 55 55]
2:多维数组:
arr2d =np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
print(arr2d)
print(arr2d[3]) #多维数组索引是一维数组
print(arr2d[1][2]) #一维数组以后切牌获得单个值
arr2d[0]=42 #多维数组单独索引赋值,则整个一维数组都换值
arr2d[0][0] =55
print(arr2d) # 把多为数组都拆开单独赋值获得内容
l =arr2d[0:2] #多维数组切片,可以
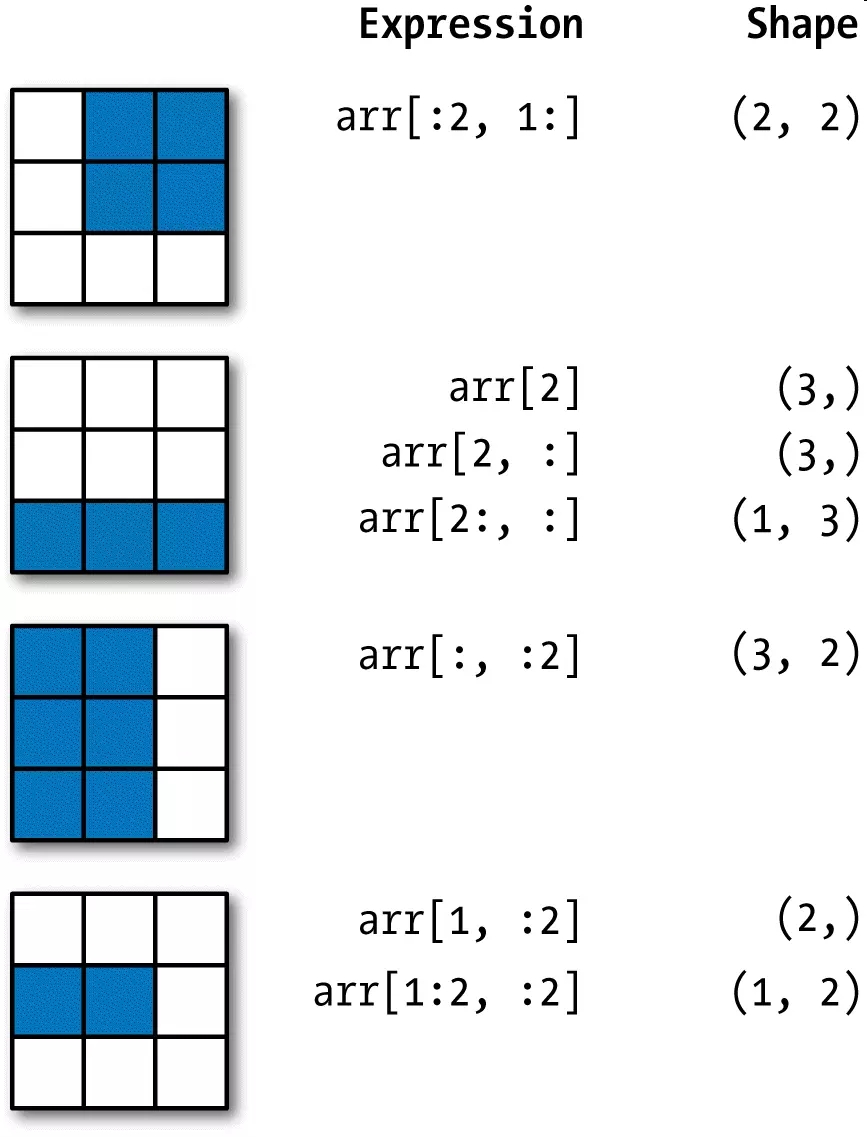
l =arr2d[:2,2] #切完之后再,进行小切 l =arr2d[:2,1:] #获取前二行后两列
l =arr2d[2,:2]
l1 =arr2d[1,:2] #获取第二个前两列
l =arr2d[:3,:2] #获取前三行前两列
l =arr2d[:,:1] #多维数组,索引从1开始
print(l)
>>>
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[10 11 12]
6
[[55 42 42]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[[55]
[ 4]
[ 7]
[10]]
五:布尔型索引
names =np.array(['bob','bob','bob','bob','bob','apple','alan','sele'])
data =np.random.randn(8,4)
# names =='bob'
print(names=='bob') #字符串也可以进行比较返回一个bool值
print(names)
>>>>
[ True True True True True False False False]
['bob' 'bob' 'bob' 'bob' 'bob' 'apple' 'alan' 'sele']
print(data)
print(data[names =='bob']) #有两个bob 所以返回行 #布尔型索数组长度,需要等于布尔型索引长度,
>>>>>
[[-0.3316016 1.78918492 -1.59222587 0.21469427]
[ 1.55247352 1.14508726 -0.68673629 -0.42648069]
[-0.95385141 -0.1938747 0.22302977 -1.25419395]
[ 0.09290589 0.26875941 -0.34120567 1.67205517]
[ 1.17781667 -0.83402007 -2.64528669 -0.70822941]
[ 0.34199013 1.81982055 0.60103061 0.39070584]
[-1.20352138 0.7618197 -1.29754963 1.19821404]
[ 0.84278983 -0.60723742 -0.73442051 -0.87391669]]
[[-0.3316016 1.78918492 -1.59222587 0.21469427]
[ 1.55247352 1.14508726 -0.68673629 -0.42648069]
[-0.95385141 -0.1938747 0.22302977 -1.25419395]
[ 0.09290589 0.26875941 -0.34120567 1.67205517]
[ 1.17781667 -0.83402007 -2.64528669 -0.70822941]]
print(data[names =='bob',2:]) #获取之后也可以切片
print(names!='bob')
print(data[~(names =='bob')])
>>>>>>>>>>
[[-1.05528931 -0.19176188]
[-1.55590721 0.43000376]
[ 1.3635074 0.75722279]
[ 2.80719722 0.3907232 ]
[ 0.3805182 -1.30951587]]
[False False False False False True True True]
[[ 0.64999255 -1.40220795 -0.11081563 0.51079912]
[ 1.24400895 -1.81700713 -0.24652383 1.20494275]
[-1.53308854 1.09828319 1.32899806 -0.86707369]]
利用python 学习数据分析 (学习一)的更多相关文章
- "利用python进行数据分析"学习记录01
"利用python进行数据分析"学习记录 --day01 08/02 与书相关的资料在 http://github.com/wesm/pydata-book pandas 的2名字 ...
- Python: 利用Python进行数据分析 学习记录
-----15:18 2016/10/14----- 1. import numpy as np;import pandas as pd values = pd.Series(np.random.no ...
- PYTHON学习(三)之利用python进行数据分析(1)---准备工作
学习一门语言就是不断实践,python是目前用于数据分析最流行的语言,我最近买了本书<利用python进行数据分析>(Wes McKinney著),还去图书馆借了本<Python数据 ...
- 利用python进行数据分析——(一)库的学习
总结一下自己对python常用包:Numpy,Pandas,Matplotlib,Scipy,Scikit-learn 一. Numpy: 标准安装的Python中用列表(list)保存一组值,可以用 ...
- $《利用Python进行数据分析》学习笔记系列——IPython
本文主要介绍IPython这样一个交互工具的基本用法. 1. 简介 IPython是<利用Python进行数据分析>一书中主要用到的Python开发环境,简单来说是对原生python交互环 ...
- 利用Python进行数据分析(第二版)电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1y1C0bJPkSn7Sv6Eq9G5_Ug 提取码:vscu <利用Python进行数据分析(第二版)>高清中文版 ...
- 利用Python进行数据分析 2017 第二版 项目代码
最近在学习<利用Python进行数据分析>,找到了github项目的地址, 英文版本,中文版本 (非常感谢翻译中文的作者). mark一下,方便后边学习查找.
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
- 利用python进行数据分析--(阅读笔记一)
以此记录阅读和学习<利用Python进行数据分析>这本书中的觉得重要的点! 第一章:准备工作 1.一组新闻文章可以被处理为一张词频表,这张词频表可以用于情感分析. 2.大多数软件是由两部分 ...
- 参考《利用Python进行数据分析(第二版)》高清中文PDF+高清英文PDF+源代码
第2版针对Python 3.6进行全面修订和更新,涵盖新版的pandas.NumPy.IPython和Jupyter,并增加大量实际案例,可以帮助高效解决一系列数据分析问题. 第2版中的主要更新了Py ...
随机推荐
- unity平行光太亮?物体发白?可能你使用了2个或多个平行光
unity平行光太亮?物体发白?可能你使用了2个或多个平行光 今天做项目时就遇到了这个问题,光亮得让物体发白 发现加载的场景 里面有个 平行光,删了就好了 要是感觉还是太亮,就把主平行光的Intens ...
- DOM 删除HTML元素
常用方法: <script> var parent=document.getElementById("div1"); var child=document.getEle ...
- Sketch插件新利器——使用Mockplus DS制作设计规范
Sketch,作为一款专为图标和界面设计而打造的优质矢量绘图工具,也是设计师们制作和完善公司企业内部设计规范系统不可或缺的设计工具. 然而,逐个导出和上传Sketch编辑优化的设计系统资源费时而费力. ...
- centos7 redis伪集群安装
安装gcc: yum install gcc -y 上传redis软件包到 /home下 解压: tar xf redis-3.2.11.tar.gz 进入 redis 目录 : cd r ...
- Oracle查看字符集
select * from nls_database_parameters where parameter like 'NLS%CHARACTERSET';
- tp5和gateworer集成
第一步:安装thinkpph程序包 第二步:切换到根目录,使用composer require workerman/gateway-worker 安装Linux版本的gateway.(前提是你服务器安 ...
- RocketMQ 自定义文件路径
一 .1. 修改store路径2. 修改logs路径3. 修改rmq_bk_gc.log路径4. 修改rmq_srv_gc.log路径二 .1. 获取正确的rocketmq 源码2. 地址:https ...
- 团体程序设计天梯赛L1-020 帅到没朋友 2017-03-22 17:46 72人阅读 评论(0) 收藏
L1-020. 帅到没朋友 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 当芸芸众生忙着在朋友圈中发照片的时候,总有一些人因为 ...
- Hdu1051 Wooden Sticks 2017-03-11 23:30 62人阅读 评论(0) 收藏
Wooden Sticks Problem Description There is a pile of n wooden sticks. The length and weight of each ...
- solr特点七:Plugins(扩展点)
http://wiki.apache.org/solr/SolrPlugins 在 Solr 1.3 中,扩展 Solr 以及配置和重新整理扩展变得十分简单.以前,您需要编写一个 SolrReques ...