pandas dataframe 读取 xlsx 文件
refer to:
https://medium.com/@kasiarachuta/reading-and-writingexcel-files-in-python-pandas-8f0da449cc48
dframe = pd.read_excel(“file_name.xlsx”)
dframe = pd.read_excel(“file_name.xlsx”, sheetname=”Sheet_name”)
dframe = pd.read_excel(“file_name.xlsx”, sheetname=number)
原文如下:
//////////////////////////////////////////////////////////////////////////////
Reading and writingExcel files in Python pandas
In data science, you are very likely to mostly work with CSV files. However, knowing how to import and export Excel files is also very useful.
In this post, a Kaggle dataset on 2016 US Elections was used (https://www.kaggle.com/benhamner/d/benhamner/2016-us-election/primary-results-sample-data/output). This dataset has been converted from a CSV file to an Excel file and two sheets have been added with votes for Hilary Clinton (HilaryClinton) and Donald Trump (DonaldTrump). The first sheet (All) contains the original dataset.
Reading Excel files
dframe = pd.read_excel(“file_name.xlsx”)
Reading Excel files is very similar to reading CSV files. By default, the first sheet of the Excel file is read.
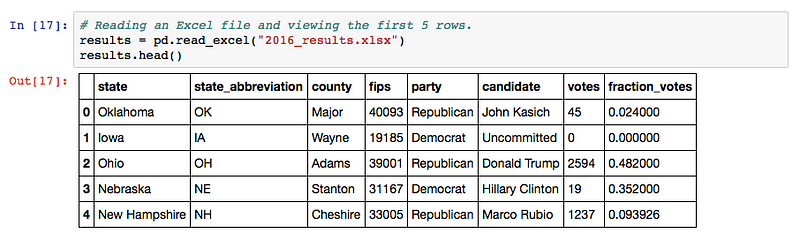
I’ve read an Excel file and viewed the first 5 rows
dframe = pd.read_excel(“file_name.xlsx”, sheetname=”Sheet_name”)
Passing the sheetname method allows you to read the sheet of the Excel file that you want. It is very handy if you know its name.

I picked the sheet named “DonaldTrump”
dframe = pd.read_excel(“file_name.xlsx”, sheetname=number)
If you aren’t sure what are the names of your sheets, you can pick them by their order. Please note that the sheets start from 0 (similar to indices in pandas), not from 1.

I read the second sheet of the Excel file
dframe = pd.read_excel(“file_name.xlsx”, header=None)
Sometimes, the top row does not contain the column names. In this case, you pass the argument of header=None.

The first row is not the header — instead, we get the column names as numbers
dframe = pd.read_excel(“file_name.xlsx”, header=n)
Passing the argument of header being equal to a number allows us to pick a specific row as the column names.

I pick the second row (i.e. row index 1 of the original dataset) as my column names.
dframe = pd.read_excel(“file_name.xlsx”, index_col=number)
You can use different columns for the row labels by passing the index_col argument as number.

I now use the county as the index column.
dframe = pd.read_excel(“file_name.xlsx”, skiprows=n)
Sometimes, you don’t want to include all of the rows. If you want to skip the first n rows, just pass the argument of skiprows=n.

Skipping the first two rows (including the header)
Writing an Excel file
dframe.to_excel(‘file_name.xlsx’)

I wrote an Excel file called results.xlsx from my results DataFrame
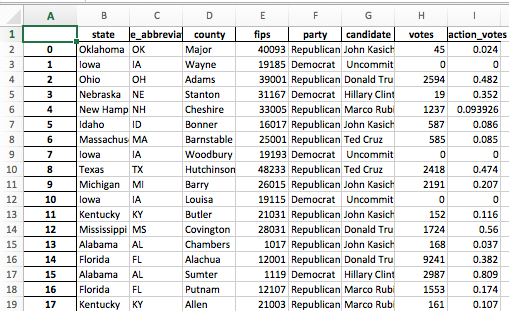
My exported Excel file
dframe.to_excel(‘file_name.xlsx’, index=False)
If you don’t want to include the index name (for example, here it is a number so it may be meaningless for future use/analysis), you can just pass another argument, setting index as False.

I don’t want index names in my Excel file
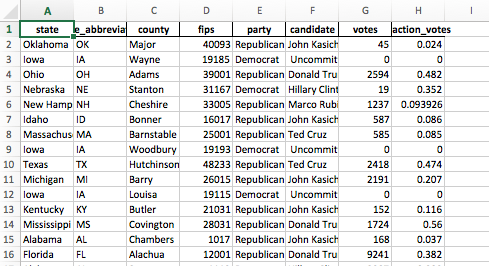
Excel file output with no index names
All of the code can be found on my GitHub: https://github.com/kasiarachuta/Blog/blob/master/Reading%20and%20writing%20Excel%20files.ipynb
pandas dataframe 读取 xlsx 文件的更多相关文章
- pandas-19 DataFrame读取写入文件的方法
pandas-19 DataFrame读取写入文件的方法 DataFrame有非常丰富的IO方法,比如DataFrame读写csv文件excel文件等等,操作很简单.下面在代码中标记出来一些常用的读写 ...
- 人工智能-机器学习之seaborn(读取xlsx文件,小提琴图)
我们不止可以读取数据库的内容,还可以读取xlsx文件的内容,这个库有在有些情况还是挺实用的 首先我们想读取这个文件的时候必须得现有个seaborn库 下载命令就是: pip install seab ...
- Python读取xlsx文件
Python读取xlsx文件 脚本如下: from openpyxl import load_workbook workbook = load_workbook(u'/tmp/test.xlsx') ...
- 读取xlsx文件的内容输入到xls文件中
package com.cn.peitest.excel; import java.io.File; import java.io.FileInputStream; import java.io.Fi ...
- C#读取xlsx文件Excel2007
读取Excel 2007的xlsx文件和读取老的.xls文件是一样的,都是用Oledb读取,仅仅连接字符串不同而已. 具体代码实例: public static DataTable GetExcelT ...
- C#基础知识之读取xlsx文件Excel2007
读取Excel 2007的xlsx文件和读取老的.xls文件是一样的,都是用Oledb读取,仅仅连接字符串不同而已. 具体代码实例: public static DataTable GetExcelT ...
- 使用POI读取xlsx文件,包含对excel中自定义时间格式的处理
package poi; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundExcepti ...
- pandas read_csv读取大文件的Memory error问题
今天在读取一个超大csv文件的时候,遇到困难:首先使用office打不开然后在python中使用基本的pandas.read_csv打开文件时:MemoryError 最后查阅read_csv文档发现 ...
- Pandas dataframe数据写入文件和数据库
转自:http://www.dcharm.com/?p=584 Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作,DataFr ...
随机推荐
- web前端基础补充
1 布局和事件 布局效果如下(标题和内容都居中,两边留空白) 布局代码如下 <!DOCTYPE html> <html lang="en"> <he ...
- Conductor
https://netflix.github.io/conductor/ High Level Architecture
- GreenOpenPaint的实现(四)放大缩小处理滚动事件
放大缩小看似简单,实际上还是比较复杂的.所以专门拿出来说明. 缩放这块,主要就是处理m_pDoc->m_scalefactor void CGreenOpenPaintView::OnButto ...
- QT+qtablewidget自定义表头【合并单元格】
1.把下列文件放在工程中[已上传到我的文件中] 2.代码 auto *headview = new HHeadViewClass(Qt::Horizontal, ui.tableWidget); he ...
- 5700刀打造3卡1080Ti深度学习机器【转】
本文转载自:https://www.jianshu.com/p/ca2e003bf77e 5700美刀,打造3x1080Ti实验室GPU深度学习机器 最近为公司搭建了一台实验用的深度学习主机,在网 ...
- openwrt编译系统生成ubi镜像的各变量解析
1.MKUBIFS_OPTS的作用 传递参数给mkfs.ubifs 2.MKUBIFS_OPTS传递了哪些参数? 传递了最小输入输出单元大小.逻辑擦除块大小.最大物理擦除块的个数,分别由选项-m.-e ...
- javascript之反柯里化(uncurrying)
在JavaScript中,当我们调用对象的某个方法时,其实不用去关心该对象原本是否被设计为拥有这个方法,这是动态类型语言的特点.可以通过反柯里化(uncurrying)函数实现,让一个对象去借用一个原 ...
- 流行得前端构建工具比较,以及gulp配置
前端现在三足鼎立的构建工具(不算比较老的ant,yeoman),非fis,grunt,gulp莫属了. fis用起来最简单,我打算自己得项目中使用一下fis. 先说一下gulp安装吧. 第一步:安装n ...
- 用jersey写简单Restful接口
1.在myeclipse中新建一个Dynamic Web Project 2.下载jar包,地址在这里 3.restful service代码 package com.qy; import javax ...
- charles工具过滤腾讯视频播放器广告
Charles是一个HTTP代理服务器,HTTP监视器,反转代理服务器,当程序连接Charles的代理访问互联网时,Charles可以监控这个程序发送和接收的所有数据.它允许一个开发者查看所有连接互联 ...