【数据压缩】LZ78算法原理及实现
在提出基于滑动窗口的LZ77算法后,两位大神Jacob Ziv与Abraham Lempel于1978年在发表的论文 [1]中提出了LZ78算法;与LZ77算法不同的是LZ78算法使用动态树状词典维护历史字符串。
1. 原理
压缩
LZ78算法的压缩过程非常简单。在压缩时维护一个动态词典Dictionary,其包括了历史字符串的index与内容;压缩情况分为三种:
- 若当前字符c未出现在词典中,则编码为
(0, c); - 若当前字符c出现在词典中,则与词典做最长匹配,然后编码为
(prefixIndex,lastChar),其中,prefixIndex为最长匹配的前缀字符串,lastChar为最长匹配后的第一个字符; - 为对最后一个字符的特殊处理,编码为
(prefixIndex,)。
如果对于上述压缩的过程稍感费解,下面给出三个例子。例子一,对于字符串“ABBCBCABABCAABCAAB”压缩编码过程如下:
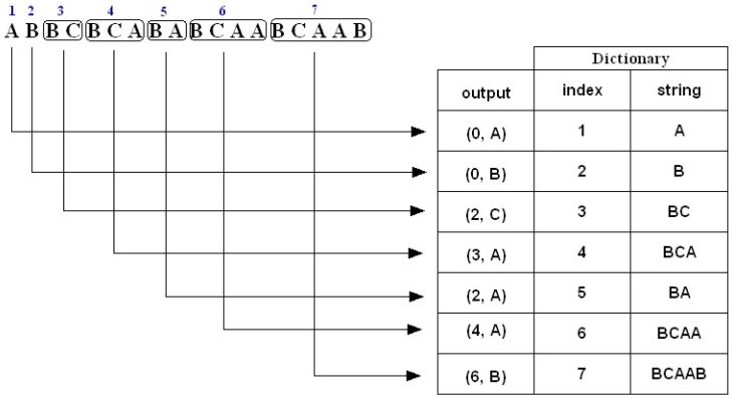
1. A is not in the Dictionary; insert it
2. B is not in the Dictionary; insert it
3. B is in the Dictionary.
BC is not in the Dictionary; insert it.
4. B is in the Dictionary.
BC is in the Dictionary.
BCA is not in the Dictionary; insert it.
5. B is in the Dictionary.
BA is not in the Dictionary; insert it.
6. B is in the Dictionary.
BC is in the Dictionary.
BCA is in the Dictionary.
BCAA is not in the Dictionary; insert it.
7. B is in the Dictionary.
BC is in the Dictionary.
BCA is in the Dictionary.
BCAA is in the Dictionary.
BCAAB is not in the Dictionary; insert it.
例子二,对于字符串“BABAABRRRA”压缩编码过程如下:
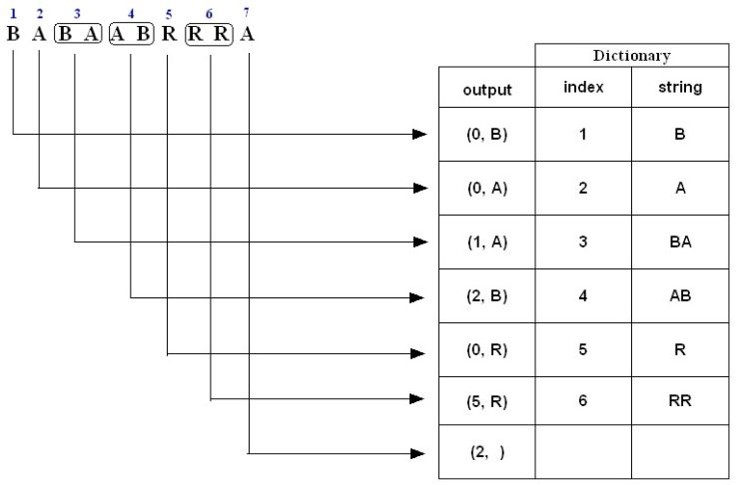
1. B is not in the Dictionary; insert it
2. A is not in the Dictionary; insert it
3. B is in the Dictionary.
BA is not in the Dictionary; insert it.
4. A is in the Dictionary.
AB is not in the Dictionary; insert it.
5. R is not in the Dictionary; insert it.
6. R is in the Dictionary.
RR is not in the Dictionary; insert it.
7. A is in the Dictionary and it is the last input character; output a pair
containing its index: (2, )
例子三,对于字符串“AAAAAAAAA”压缩编码过程如下:
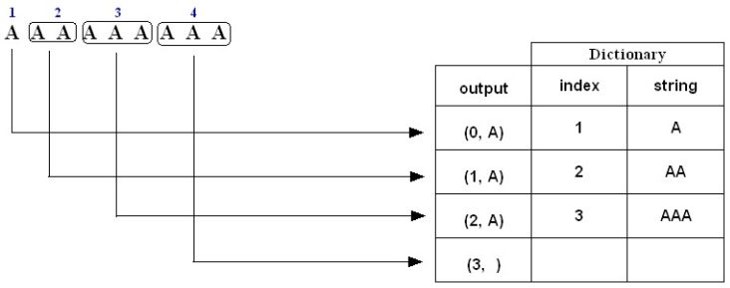
1. A is not in the Dictionary; insert it
2. A is in the Dictionary
AA is not in the Dictionary; insert it
3. A is in the Dictionary.
AA is in the Dictionary.
AAA is not in the Dictionary; insert it.
4. A is in the Dictionary.
AA is in the Dictionary.
AAA is in the Dictionary and it is the last pattern; output a pair containing its index: (3, )
解压缩
解压缩能更根据压缩编码恢复出(压缩时的)动态词典,然后根据index拼接成解码后的字符串。为了便于理解,我们拿上述例子一中的压缩编码序列(0, A) (0, B) (2, C) (3, A) (2, A) (4, A) (6, B)来分解解压缩步骤,如下图所示:

前后拼接后,解压缩出来的字符串为“ABBCBCABABCAABCAAB”。
LZ系列压缩算法
LZ系列压缩算法均为LZ77与LZ78的变种,在此基础上做了优化。
- LZ77:LZSS、LZR、LZB、LZH;
- LZ78:LZW、LZC、LZT、LZMW、LZJ、LZFG。
其中,LZSS与LZW为这两大阵容里名气最响亮的算法。LZSS是由Storer与Szymanski [2]改进了LZ77:增加最小匹配长度的限制,当最长匹配的长度小于该限制时,则不压缩输出,但仍然滑动窗口右移一个字符。Google开源的Snappy压缩算法库大体遵循LZSS的编码方案,在其基础上做了一些工程上的优化。
2. 实现
Python 3.5实现LZ78算法:
# -*- coding: utf-8 -*-
# A simplified implementation of LZ78 algorithm
# @Time : 2017/1/13
# @Author : rain
def compress(message):
tree_dict, m_len, i = {}, len(message), 0
while i < m_len:
# case I
if message[i] not in tree_dict.keys():
yield (0, message[i])
tree_dict[message[i]] = len(tree_dict) + 1
i += 1
# case III
elif i == m_len - 1:
yield (tree_dict.get(message[i]), '')
i += 1
else:
for j in range(i + 1, m_len):
# case II
if message[i:j + 1] not in tree_dict.keys():
yield (tree_dict.get(message[i:j]), message[j])
tree_dict[message[i:j + 1]] = len(tree_dict) + 1
i = j + 1
break
# case III
elif j == m_len - 1:
yield (tree_dict.get(message[i:j + 1]), '')
i = j + 1
def uncompress(packed):
unpacked, tree_dict = '', {}
for index, ch in packed:
if index == 0:
unpacked += ch
tree_dict[len(tree_dict) + 1] = ch
else:
term = tree_dict.get(index) + ch
unpacked += term
tree_dict[len(tree_dict) + 1] = term
return unpacked
if __name__ == '__main__':
messages = ['ABBCBCABABCAABCAAB', 'BABAABRRRA', 'AAAAAAAAA']
for m in messages:
pack = compress(m)
unpack = uncompress(pack)
print(unpack == m)
3. 参考资料
[1] Ziv, Jacob, and Abraham Lempel. "Compression of individual sequences via variable-rate coding." IEEE transactions on Information Theory 24.5 (1978): 530-536.
[2] Storer, James A., and Thomas G. Szymanski. "Data compression via textual substitution." Journal of the ACM (JACM) 29.4 (1982): 928-951.
[3] Welch, T. A. "A Technique for High-Performance Data Compression." Computer 17.17(1984):8-19.
[4] Jauhar Ali, Unit31_LZ78.ppt.
[5] guyb, 15-853:Algorithms in the Real World - Data Compression III.
【数据压缩】LZ78算法原理及实现的更多相关文章
- 【数据压缩】LZ77算法原理及实现
1. 引言 LZ77算法是采用字典做数据压缩的算法,由以色列的两位大神Jacob Ziv与Abraham Lempel在1977年发表的论文<A Universal Algorithm for ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- RSA算法原理
一直以来对linux中的ssh认证.SSL.TLS这些安全认证似懂非懂的.看到阮一峰博客中对RSA算法的原理做了非常详细的解释,看完之后茅塞顿开,关于RSA的相关文章如下 RSA算法原理(一) RSA ...
- LruCache算法原理及实现
LruCache算法原理及实现 LruCache算法原理 LRU为Least Recently Used的缩写,意思也就是近期最少使用算法.LruCache将LinkedHashMap的顺序设置为LR ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- OpenGL学习进程(13)第十课:基本图形的底层实现及算法原理
本节介绍OpenGL中绘制直线.圆.椭圆,多边形的算法原理. (1)绘制任意方向(任意斜率)的直线: 1)中点画线法: 中点画线法的算法原理不做介绍,但这里用到最基本的画0<=k ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
随机推荐
- Mvc 导出 Excel
Mvc 导出 Excel 之前接触过Webform,winfrom 的导出Excel方法 ,优点:省事.缺点:服务器必须安装Office 这几天做项目 和 大牛学习了一下 新的方法,自己加以总结.希望 ...
- AJAX入门——工作原理
同步和异步交互,了解互动 对于一个样本:一般B/S模式(同步) AJAX技术(异步) * 同步: 提交请求->等待server处理->处理完成返回 ...
- ZA7783:MIPI转LVDS/MIPI转RGB888/RGB转LVDS
在消费类电子越来越白热化阶段.好多设计project师已经開始慢慢关注到成本控制,小金在这里就给大家带来一颗转接IC.希望能帮助贵公司控制成本.当然性能也是可靠的,已经好多产品设计了. 多多不吝赐教 ...
- 手机网站keyup解决方案
模糊搜索keyup无效,解决方案如下 //手机网站解决keyup的方法 $(function () { $('#repairsearch').bind('focus', filter_time); } ...
- 关于WCF的一些知识点
首先,WCF和WebService一些区别1,WCF支持多中通信协议,http/https tcp/udp/msmq.命名管道,对等网,消息可达性,事物流等.2,WCF可以与ASP.NET集成,共享同 ...
- C#自带组件
C#自带组件 在项目正式上线后,如果出现错误,异常,崩溃等情况 我们往往第一想到的事就是查看日志 所以日志对于一个系统的维护是非常重要的 贯穿所有的日志系统 日志系统,往往是贯穿一个程序的所有代码的; ...
- Ninject是一款.Net平台下的开源依赖注入框架
Ninject是一款.Net平台下的开源依赖注入框架.按照官方说法,它快如闪电.超级轻量,且充分利用了.Net的最新语法,使用Lambda表达式代替Xml文件完成类型绑定.Ninject结构精巧,功能 ...
- mvc项目如何在IIS7.5
mvc项目如何在IIS7.5上发布的 1.在vs中打开你要发布的项目,右键属性找到发布 2.弹出发布web对话框,选择<新建配置文件...> 在弹出的对话框中输入一个配置文件名称,后确定 ...
- Glue4Net简单部署基于win服务的Socket程序
smark 专注于高并发网络和大型网站架规划设计,提供.NET平台下高吞吐的网络通讯应用技术咨询和支持 Glue4Net简单部署基于win服务的Socket程序 在写一些服务应用的时候经常把要它部署到 ...
- c#中解决winform中控件不能输入汉字的办法
设置控件的ImeMode属性 如: textBox.ImeMode = System.Windows.Forms.ImeMode.On; 其中枚举有如下值: