Tomcat系列(二)- EndPoint源码解析
在上一节中我们描述了Tomcat的整体架构,
我们知道了Tomcat分为两个大组件,一个连接器和一个容器。
而我们这次要讲的 EndPoint的组件就是属于连接器里面的。
它是一个通信的端点,就是负责对外实现TCP/IP协议。
EndPoint是个接口,
它的具体实现类就是 AbstractEndpoint,而 AbstractEndpoint具体的实现类就有 AprEndpoint、 Nio2Endpoint、 NioEndpoint。
AprEndpoint:对应的是APR模式,简单理解就是从操作系统级别解决异步IO的问题,大幅度提高服务器的处理和响应性能。但是启用这种模式需要安装一些其他的依赖库。Nio2Endpoint:利用代码来实现异步IONioEndpoint:利用了JAVA的NIO实现了非阻塞IO,Tomcat默认启动是以这个来启动的,而这个也是我们的讲述重点。
NioEndpoint中重要的组件
我们知道 NioEndpoint的原理还是对于Linux的多路复用器的使用,而在多路复用器中简单来说就两个步骤。
1. 创建一个Selector,在它身上注册各种Channel,然后调用select方法,等待通道中有感兴趣的事件发生。
2. 如果有感兴趣的事情发生了,例如是读事件,那么就将信息从通道中读取出来。
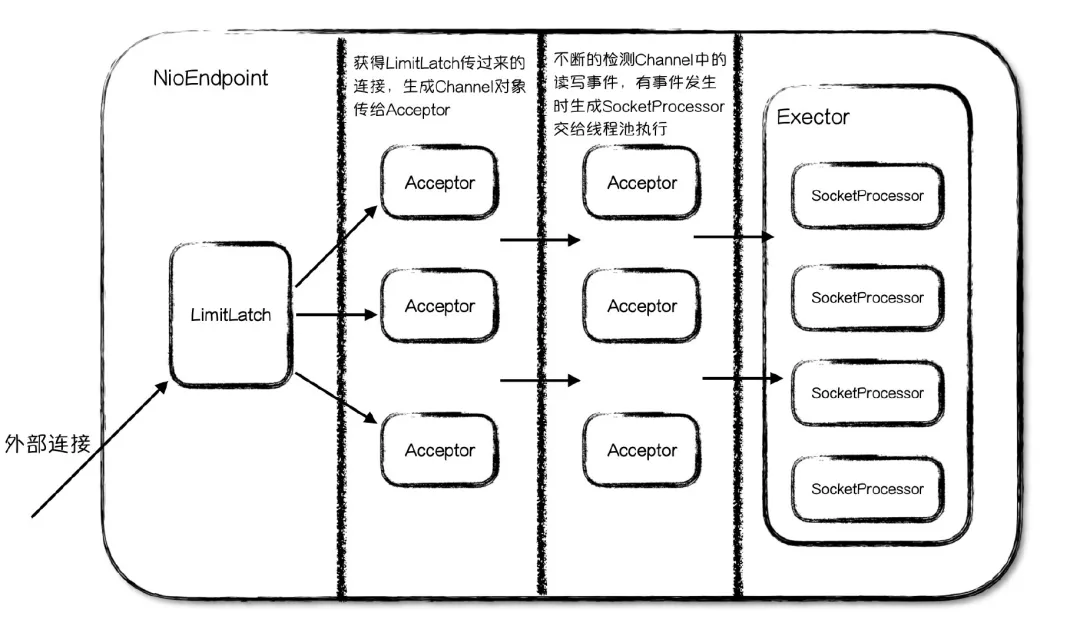
而 NioEndpoint为了实现上面这两步,用了五个组件来。
这五个组件是 LimitLatch、 Acceptor、 Poller、 SocketProcessor、 Executor
/** * Threads used to accept new connections and pass them to worker threads. */ protected List<Acceptor<U>> acceptors; /** * counter for nr of connections handled by an endpoint */ private volatile LimitLatch connectionLimitLatch = null; /** * The socket pollers. */ private Poller[] pollers = null; // 内部类 SocketProcessor /** * External Executor based thread pool. */ private Executor executor = null;
我们可以看到在代码中定义的这五个组件。具体这五个组件是干嘛的呢?
LimitLatch:连接控制器,负责控制最大的连接数Acceptor:负责接收新的连接,然后返回一个Channel对象给PollerPoller:可以将其看成是NIO中Selector,负责监控Channel的状态SocketProcessor:可以看成是一个被封装的任务类Executor:Tomcat自己扩展的线程池,用来执行任务类
用图简单表示就是以下的关系
接下来我们就来分别的看一下每个组件里面关键的代码
LimitLatch
我们上面说了 LimitLatch主要是用来控制Tomcat所能接收的最大数量连接,如果超过了此连接,那么Tomcat就会将此连接线程阻塞等待,等里面有其他连接释放了再消费此连接。
那么 LimitLatch是如何做到呢?我们可以看 LimitLatch这个类
public class LimitLatch {
private static final Log log = LogFactory.getLog(LimitLatch.class);
private class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 1L;
public Sync() {}
@Override
protected int tryAcquireShared(int ignored) {
long newCount = count.incrementAndGet();
if (!released && newCount > limit) {
// Limit exceeded
count.decrementAndGet();
return -1;
} else {
return 1;
}
}
@Override
protected boolean tryReleaseShared(int arg) {
count.decrementAndGet();
return true;
}
}
private final Sync sync;
private final AtomicLong count;
private volatile long limit;
private volatile boolean released = false;
}
我们可以看到它内部实现了 AbstractQueuedSynchronizer,AQS其实就是一个框架,实现它的类可以自定义控制线程什么时候挂起什么时候释放。
limit参数就是控制的最大连接数。
我们可以看到 AbstractEndpoint调用 LimitLatch的 countUpOrAwait方法来判断是否能获取连接。
public void countUpOrAwait() throws InterruptedException {
if (log.isDebugEnabled()) {
log.debug("Counting up["+Thread.currentThread().getName()+"] latch="+getCount());
}
sync.acquireSharedInterruptibly(1);
}
AQS是如何知道什么时候阻塞线程呢?即不能获取连接呢?
这些就靠用户自己实现 AbstractQueuedSynchronizer自己来定义什么时候获取连接,什么时候释放连接了。
可以看到Sync类重写了 tryAcquireShared和 tryReleaseShared方法。
在 tryAcquireShared方法中定义了一旦当前连接数大于了设置的最大连接数,那么就会返回 -1表示将此线程放入AQS队列中等待。
Acceptor
Acceptor是接收连接的,我们可以看到 Acceptor实现了 Runnable接口,那么在哪会新开启线程来执行 Acceptor的run方法呢?
在 AbstractEndpoint的 startAcceptorThreads方法中。
protected final void startAcceptorThreads() {
int count = getAcceptorThreadCount();
acceptors = new Acceptor[count];
for (int i = 0; i < count; i++) {
acceptors[i] = createAcceptor();
String threadName = getName() + "-Acceptor-" + i;
acceptors[i].setThreadName(threadName);
Thread t = new Thread(acceptors[i], threadName);
t.setPriority(getAcceptorThreadPriority());
t.setDaemon(getDaemon());
t.start();
}
}
可以看到这里可以设置开启几个 Acceptor,默认是一个。
而一个端口只能对应一个 ServerSocketChannel,那么这个 ServerSocketChannel在哪初始化呢?我们可以看到在 Acceptor<U>acceptor=newAcceptor<>(this);
这句话中传入了this进去,那么应该是由 Endpoint组件初始化的连接。
在 NioEndpoint的 initServerSocket方法中初始化了连接。

这里面我们能够看到两点
1. 在bind方法中的第二个参数表示操作系统的等待队列长度,即Tomcat不再接受连接时(达到了设置的最大连接数),但是在操作系统层面还是能够接受连接的,此时就将此连接信息放入等待队列,那么这个队列的大小就是此参数设置
2. ServerSocketChannel被设置成了阻塞的模式,也就是说是以阻塞方式接受连接的。
或许会有疑问。在平时的NIO编程中Channel不是都要设置成非阻塞模式吗?
这里解释一下,如果是设置成非阻塞模式那么就必须设置一个 Selector不断的轮询,但是接受连接只需要阻塞一个通道即可。

这里需要注意一点,每个 Acceptor在生成 PollerEvent对象放入 Poller队列中时都是随机取出 Poller对象的,
所以 Poller中的 Queue对象设置成了 SynchronizedQueue<PollerEvent>,因为可能有多个 Acceptor同时向此 Poller的队列中放入 PollerEvent对象。
具体代码可以看如下,
public Poller getPoller0() {
int idx = Math.abs(pollerRotater.incrementAndGet()) % pollers.length;
return pollers[idx];
}
什么是操作系统级别的连接呢?
在TCP的三次握手中,系统通常会每一个LISTEN状态的Socket维护两个队列,一个是半连接队列(SYN):
这些连接已经收到客户端SYN;另一个是全连接队列(ACCEPT):
这些链接已经收到客户端的ACK,完成了三次握手,等待被应用调用accept方法取走使用。
所有的 Acceptor共用这一个连接,在 Acceptor的 run方法中,放一些重要的代码。
public void run(){
// Loop until we receive a shutdown command
while(endpoint.isRunning()){
try{
//如果到了最大连接数,线程等待
endpoint.countUpOrAwaitConnection();
U socket = null;
try{
//调用accept方法获得一个连接
socket = endpoint.serverSocketAccept();
}catch(Exception ioe){
// 出异常以后当前连接数减掉1
endpoint.countDownConnection();
}
// 配置Socket
if(endpoint.isRunning() && !endpoint.isPaused()){
// setSocketOptions() will hand the socket off to
// an appropriate processor if successful
if(!endpoint.setSocketOptions(socket)){
endpoint.closeSocket(socket)
}
} else {
endpoint.destroySocket(socket);
}
}
}
}
里面我们可以得到两点
1. 运行时会先判断是否到达了最大连接数,如果到达了那么就阻塞线程等待,里面调用的就是 LimitLatch组件判断的。
2. 最重要的就是配置socket这一步了,是 endpoint.setSocketOptions(socket)这段代码

其实里面重要的就是将 Acceptor与一个 Poller绑定起来,然后两个组件通过队列通信,每个Poller都维护着一个 SynchronizedQueue队列, ChannelEvent放入到队列中,然后 Poller从队列中取出事件进行消费。
Poller
我们可以看到 Poller是 NioEndpoint的内部类,而它也是实现了 Runnable接口,可以看到在其类中维护了一个Quene和Selector,定义如下。
所以本质上 Poller就是 Selector。
private Selector selector; private final SynchronizedQueue<PollerEvent> events =new SynchronizedQueue<>();
重点在其run方法中,这里删减了一些代码,只展示重要的。

其中主要的就是调用了 events()方法,就是不断的查看队列中是否有 Pollerevent事件,如果有的话就将其取出然后把里面的 Channel取出来注册到该 Selector中,然后不断轮询所有注册过的 Channel查看是否有事件发生。
SocketProcessor
我们知道 Poller在轮询 Channel有事件发生时,就会调用将此事件封装起来,然后交给线程池去执行。
那么这个包装类就是 SocketProcessor。
而我们打开此类,能够看到它也实现了 Runnable接口,用来定义线程池 Executor中线程所执行的任务。
那么这里是如何将 Channel中的字节流转换为Tomcat需要的 ServletRequest对象呢?其实就是调用了 Http11Processor来进行字节流与对象的转换的。
Executor
Executor其实是Tomcat定制版的线程池。我们可以看它的类的定义,可以发现它其实是扩展了Java的线程池。
public interface Executor extends java.util.concurrent.Executor, Lifecycle
在线程池中最重要的两个参数就是核心线程数和最大线程数,正常的Java线程池的执行流程是这样的。
1. 如果当前线程小于核心线程数,那么来一个任务就创建一个线程。
2. 如果当前线程大于核心线程数,那么就再来任务就将任务放入到任务队列中。所有线程抢任务。
3. 如果队列满了,那么就开始创建临时线程。
4. 如果总线程数到了最大的线程数并且队列也满了,那么就抛出异常。
但是在Tomcat自定义的线程池中是不一样的,通过重写了 execute方法实现了自己的任务处理逻辑。
1. 如果当前线程小于核心线程数,那么来一个任务就创建一个线程。
2. 如果当前线程大于核心线程数,那么就再来任务就将任务放入到任务队列中。所有线程抢任务。
3. 如果队列满了,那么就开始创建临时线程。
4. 如果总线程数到了最大的线程数,再次获得任务队列,再尝试一次将任务加入队列中。
5. 如果此时还是满的,就抛异常。
差别就在于第四步的差别,原生线程池的处理策略是只要当前线程数大于最大线程数,那么就抛异常,而Tomcat的则是如果当前线程数大于最大线程数,就再尝试一次,如果还是满的才会抛异常。
下面是定制化线程池 execute的执行逻辑。
public void execute(Runnable command, long timeout,TimeUnit unit){
submittedCount.incrementAndGet();
try{
super.execute(command);
}catch(RejectedExecutionException rx){
if(super.getQueue() instanceof TaskQueue){
//获得任务队列
final TaskQueue queue = (TaskQueue)super.getQueue();
try{
if(!queue.force(command,timeout,unit)){
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
}catch(InterruptedException x){
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
}else{
submittedCount.decrementAndGet();
throw rx;
}
}
}
在代码中,我们可以看到有这么一句 submittedCount.incrementAndGet();
为什么会有这句呢?我们可以看看这个参数的定义。
简单来说这个参数就是定义了任务已经提交到了线程池中,但是还没有执行的任务个数。
private final AtomicInteger submittedCount = new AtomicInteger(0);
为什么会有这么一个参数呢?
我们知道定制的队列是继承了 LinkedBlockingQueue,而 LinkedBlockingQueue队列默认是没有边界的。
于是我们就传入了一个参数, maxQueueSize给构造的队列。
但是在Tomcat的任务队列默认情况下是无限制的,那么这样就会出一个问题,如果当前线程达到了核心线程数,则开始向队列中添加任务,那么就会一直是添加成功的。
那么就不会再创建新的线程。那么在什么情况下要新建线程呢?
线程池中创建新线程会有两个地方,一个是小于核心线程时,来一个任务创建一个线程。另一个是超过核心线程并且任务队列已满,则会创建临时线程。
那么如何规定任务队列是否已满呢?如果设置了队列的最大长度当然好了,但是Tomcat默认情况下是没有设置,所以默认是无限的。所以Tomcat的 TaskQueue继承了 LinkedBlockingQueue,重写了 offer方法,在里面定义了什么时候返回false。

这就是 submittedCount的意义,目的就是为了在任务队列长度无限的情况下,让线程池有机会创建新的线程。
总结
上面的知识有部分是看着李号双老师的深入拆解Tomcat总结的,又结合着源码深入了解了一下,当时刚看文章的时候觉得自己都懂了,但是再深入源码的时候又会发现自己不懂。
所以知识如果只是看了而不运用,那么知识永远都不会是自己的。
通过Tomcat连接器这一小块的源码学习,除了一些常用知识的实际运用,例如AQS、锁的应用、自定义线程池需要考虑的点、NIO的应用等等。
还有总体上的设计思维的学习,模块化设计,和如今的微服务感觉很相似,将一个功能点内部分为多种模块,这样无论是在以后替换或者是升级时都能游刃有余。
Tomcat系列(二)- EndPoint源码解析的更多相关文章
- 死磕 java同步系列之ReentrantLock源码解析(二)——条件锁
问题 (1)条件锁是什么? (2)条件锁适用于什么场景? (3)条件锁的await()是在其它线程signal()的时候唤醒的吗? 简介 条件锁,是指在获取锁之后发现当前业务场景自己无法处理,而需要等 ...
- Mybatis 系列8-结合源码解析select、resultMap的用法
[Mybatis 系列10-结合源码解析mybatis 执行流程] [Mybatis 系列9-强大的动态sql 语句] [Mybatis 系列8-结合源码解析select.resultMap的用法] ...
- Mybatis 系列6-结合源码解析节点配置:objectFactory、databaseIdProvider、plugins、mappers
[Mybatis 系列10-结合源码解析mybatis 执行流程] [Mybatis 系列9-强大的动态sql 语句] [Mybatis 系列8-结合源码解析select.resultMap的用法] ...
- Mybatis 系列3-结合源码解析properties节点和environments节点
[Mybatis 系列10-结合源码解析mybatis 执行流程] [Mybatis 系列9-强大的动态sql 语句] [Mybatis 系列8-结合源码解析select.resultMap的用法] ...
- 死磕 java同步系列之CyclicBarrier源码解析——有图有真相
问题 (1)CyclicBarrier是什么? (2)CyclicBarrier具有什么特性? (3)CyclicBarrier与CountDownLatch的对比? 简介 CyclicBarrier ...
- 死磕 java同步系列之Phaser源码解析
问题 (1)Phaser是什么? (2)Phaser具有哪些特性? (3)Phaser相对于CyclicBarrier和CountDownLatch的优势? 简介 Phaser,翻译为阶段,它适用于这 ...
- 死磕 java同步系列之StampedLock源码解析
问题 (1)StampedLock是什么? (2)StampedLock具有什么特性? (3)StampedLock是否支持可重入? (4)StampedLock与ReentrantReadWrite ...
- 死磕 java同步系列之Semaphore源码解析
问题 (1)Semaphore是什么? (2)Semaphore具有哪些特性? (3)Semaphore通常使用在什么场景中? (4)Semaphore的许可次数是否可以动态增减? (5)Semaph ...
- 死磕 java同步系列之ReentrantReadWriteLock源码解析
问题 (1)读写锁是什么? (2)读写锁具有哪些特性? (3)ReentrantReadWriteLock是怎么实现读写锁的? (4)如何使用ReentrantReadWriteLock实现高效安全的 ...
- Mybatis 系列10-结合源码解析mybatis 的执行流程
[Mybatis 系列10-结合源码解析mybatis 执行流程] [Mybatis 系列9-强大的动态sql 语句] [Mybatis 系列8-结合源码解析select.resultMap的用法] ...
随机推荐
- 2019-10-16:渗透测试,基础学习,burpsuit学习,爆破的四种方式学习
Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程.所有工具都共享一个请求,并能处理对应的HTTP 消息 ...
- Tomcat安装和使用
1.Tomcat简介 Tomcat是Apache开源组织下的开源免费的中小型Web应用服务器,支持javaEE中的servlet和jsp规范. 2.Windows版安装和使用 下载地址:http:// ...
- Java包package之间调用问题-cmd运行窗口编译运行
问题:在使用了java包机制(package)后,编译出现错误:找不到或无法加载主类 xxx 的错误提示信息(各种编译不通过) 先给演示结果: 编译:javac -d classes src/a/He ...
- spring奇怪异常记录(会逐渐记录)
1 严重: Context initialization failedorg.springframework.beans.factory.BeanCreationException: Error cr ...
- 【Android - 控件】之可悬浮列表StickyHeadersRecyclerView
这是timehop的GitHub上发表的一个控件框架,大家可以去参考它的[GitHub]. 这里先贴出GitHub上提供的效果图: 要使用这个框架,我们需要首先导入它的依赖: compile 'com ...
- Centos Linux下使用Metasploit渗透android
.newline{display:block}.katex .base{position:relative;white-space:nowrap;width:min-content}.katex .b ...
- Python正则表达式,看完这篇文章就够了...#华为云·寻找黑马程序员#【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- ef6+mysql的bug
entityFramework6在mysql数据库下,用linq进行排序会出现一个bug. Expression<Func<blog, bool>> expr_filter=p ...
- iOS 自定义TabBarController
转自:http://blog.csdn.net/xn4545945/article/details/35994863 一.自定义的思路 iOS中的TabBarController确实已经很强大了,大部 ...
- imageView的使用
转自:http://www.runoob.com/ios/att-ios-ui-imageview.html 图像视图用于显示单个图像或动画序列的图像. 重要的属性 image highlighted ...