6.1 Spark SQL
一、从shark到Spark SQL
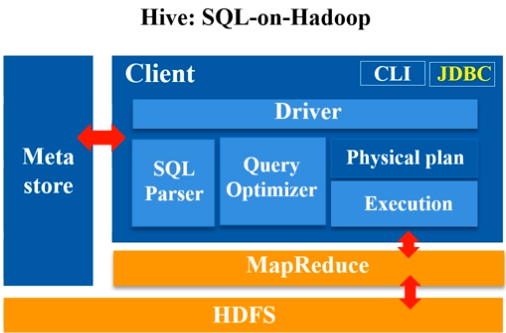
Hive能够把SQL程序转换成map-reduce程序
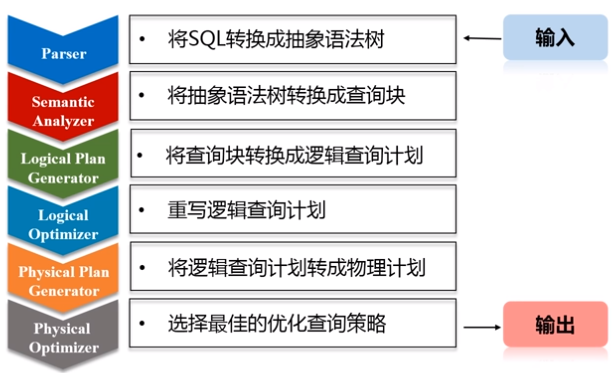
可以把Hadoop中的Hive看作是一个接口,主要起到了转换的功能,并没有实际存储数据。

Shark即Hive on Spark,为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作(shark相当于是hive的引进版,它把hive里的各种模块,基本上一五一十地照搬过来,就做了一个最底层的修改,hive是从最底层转成MapReduce程序,而到了shark,它的其他模块都没变,就把最底层翻译成spark应用程序。)
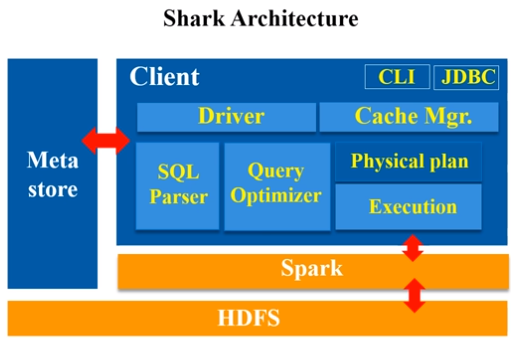 、
、
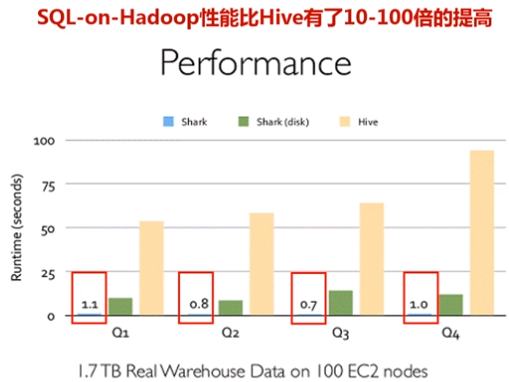
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高
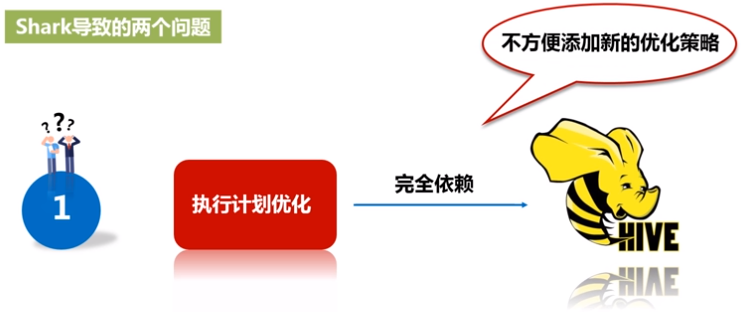
因为shark是基于hive修改的,会带来两个问题:
1)执行计划优化完全依赖于Hive,不方便添加新的优化策略;
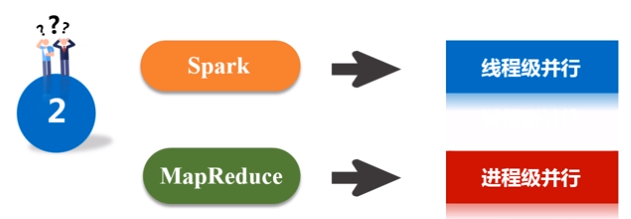
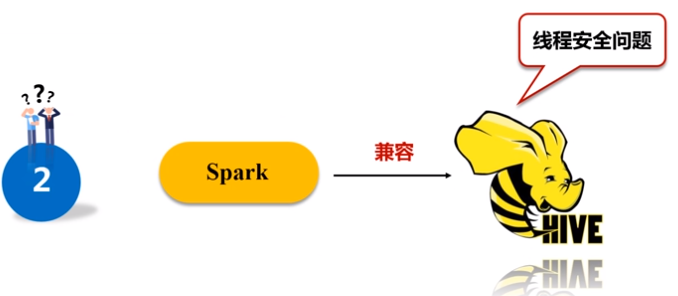
2)spark是线程级并行,MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
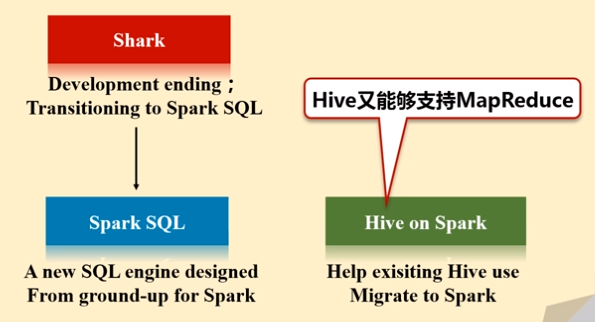
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark
- Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive
- Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎
二、Spark SQL设计
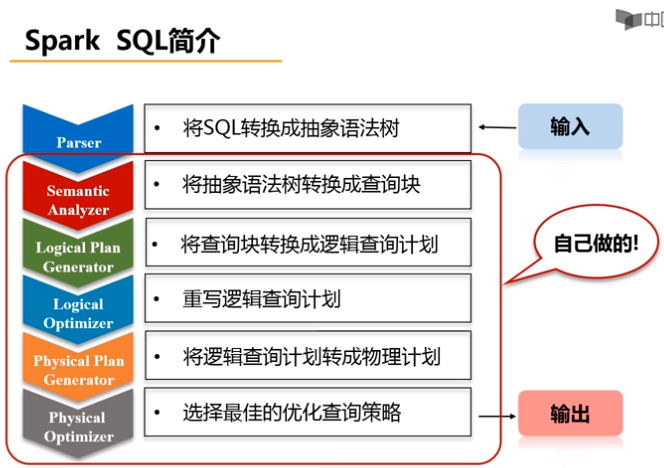
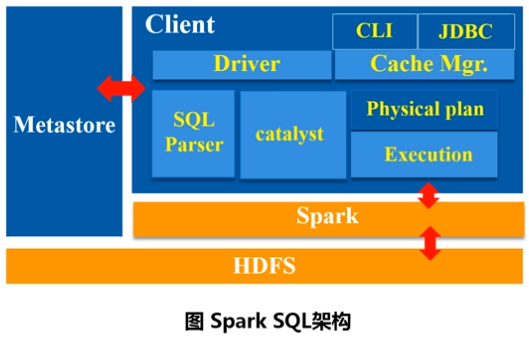
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。(Spark SQL除了沿用Parser(把SQL转换成抽象语法树)这一个模块外,其他模块全部自己定义。)


三、为什么推出Spark SQL

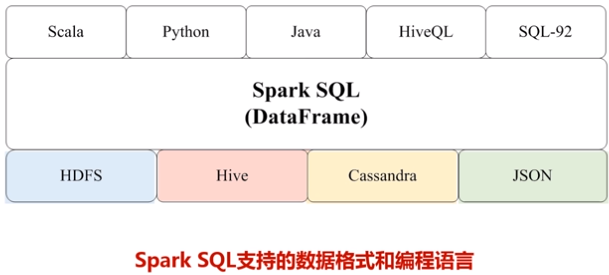
(1)关系型数据库中只存储了一部分的结构化数据,但是实际上现在要处理的相关数据类型不仅仅包括关系数据库,现在大数据时代90%的数据都是非结构化数据和半结构化数据,对于这种数据,不能用SQL语句分析。而spark SQL同时支持非结构化、半结构化、结构化数据分析。


(2)关系型数据库没有办法处理类似机器学习和图像处理的图结构数据
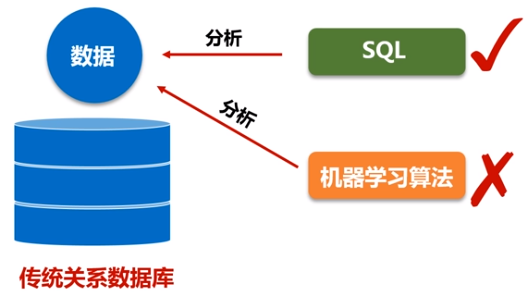
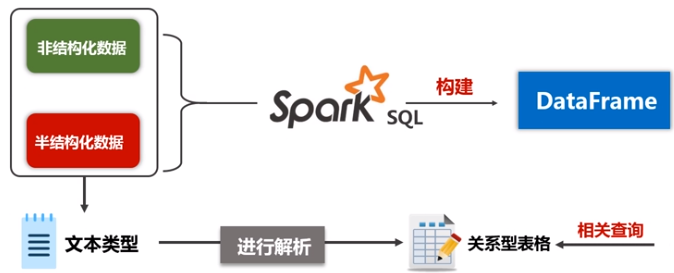
Spark SQL可以有效地把关系数据查询和复杂分析算法融合。

参考文献:
6.1 Spark SQL的更多相关文章
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL Example
Spark SQL Example This example demonstrates how to use sqlContext.sql to create and load a table ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- 基于Spark1.3.0的Spark sql三个核心部分
基于Spark1.3.0的Spark sql三个核心部分: 1.可以架子啊各种结构化数据源(JSON,Hive,and Parquet) 2.可以让你通过SQL,saprk内部程序或者外部攻击,通过标 ...
随机推荐
- 如何获取数据泵dm和dw进程的 Strace (Doc ID 1411563.1)
How To Get A Strace Of The Data Pump dm And dw Process(es) (Doc ID 1411563.1) APPLIES TO: Oracle Dat ...
- linux 的swap、swappiness及kswapd原理【转】
本文讨论的 swap基于Linux4.4内核代码 .Linux内存管理是一套非常复杂的系统,而swap只是其中一个很小的处理逻辑. 希望本文能让读者了解Linux对swap的使用大概是什么样子.阅读完 ...
- Win10家庭版激活方法
由于电脑换过主板,系统过了段时间显示未激活的状态,当时没注意随着主板口袋里的密匙,当作垃圾一起扔了,在网上试了几种方式,以下这个方法让我成功激活了系统 对开始菜单点击右键,选择Windows Powe ...
- 对于Python语音性能的一些个人见解
虽然运行速度慢是 Python 与生俱来的特点,大多数时候我们用 Python 就意味着放弃对性能的追求.但是,就算是用纯 Python 完成同一个任务,老手写出来的代码可能会比菜鸟写的代码块几倍,甚 ...
- optix之纹理使用
1.在OpenGL中生成纹理texture optix中的纹理直接使用OpenGL纹理的id,不能跨越OpenGL纹理,所以我们先在OpenGL环境下生成一张纹理. 这个过程就很熟悉了: void W ...
- Codeforces Round #594 (Div. 1) C. Queue in the Train 模拟
C. Queue in the Train There are
- golang数据结构之散哈希表(Hash)
hash.go package hash import ( "fmt" ) type Emp struct { ID int Name string Next *Emp } //第 ...
- 【STM32H7教程】第25章 STM32H7的TCM,SRAM等五块内存基础知识
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第25章 STM32H7的TCM,SRAM等五块内 ...
- 【Oracle】Oracle常用命令整理(持续更新中)
一些常用的操作命令记录 SQLPlus连接 sqlplus {username}/{password}@{ip}:{port}/{sid} 创建用户 create user testuser iden ...
- IT兄弟连 HTML5教程 HTML5的基本语法 了解HTML及运行原理
了解HTML HTML(HyperText Marked Language)即超文本标记语言,是一种用来制作超文本文档的简单标记语言.我们在浏览网页时看到的一些丰富的影像.文字.图片等内容都是通过HT ...