RabbitMQ实战应用技巧
1. RabbitMQ实战应用技巧
1.1. 前言
由于项目原因,之后会和RabbitMQ比较多的打交道,所以让我们来好好整理下RabbitMQ的应用实战技巧,尽量避免日后的采坑
1.2. 概述
RabbitMQ有几个重要的概念:虚拟主机,交换机,队列和绑定
- 虚拟主机:一个虚拟主机持有一组交换机、队列和绑定,我们可以从虚拟主机层面的颗粒度进行权限控制
- 交换机:Exchange用于转发消息,它并不存储消息,如果没有Queue队列绑定到Exchange,它会直接丢弃掉生产者发来的数据。
交换机还有个关联的重要概念:路由键,消息转发到哪个队列根据路由键决定 - 绑定:就是绑定交换机和队列,它是多对多的关系,也就是说多个交换机可以绑同一个队列,也可以一个交换机绑多个队列
1.3. 交换机
交换机有四种类型的模式Direct, topic, Headers and Fanout
1.3.1. Direct Exchage
Direct模式使用的是RabbitMQ的默认交换机,也是最简单的模式,适合比较简单的场景
如下图所示,使用Direct模式,我们需要创建不同的队列,而默认交换机则通过Routing key路由键的值来决定转发到哪个队列,可以看到,路由键绑定队列是可以指定多个的
1.3.2. Topic Exchange
Topic模式主要是根据通配符匹配,也就类似于模糊匹配,当这种匹配模式和路由键匹配后交换机就能转发消息到指定队列
- 路由键为一串字符串,由句号(
.)隔开,比如a.b.c - (
*)代表指定位置一个单词,(#)代表零个或者多个单词,比如a.*.b.#,表示a和b中间随意填个单词,b后面可以跟n个单词,比如a.x.b.c.d.e
Topic模式和Direct模式的区别在于交换机需要自己指定,路由键支持模糊匹配,例如:
rabbitTemplate.convertAndSend("topicExchange","a.x.b.d", " hello world!");
1.3.3. Headers Exchage
Headers也是根据规则匹配,但它不是根据路由键了,headers有个自定义匹配规则,它将匹配键值设在了消息的headers属性上,当这些键值对有一对或者全部匹配时,消息才会被投递到对应队列,这种模式效率相对较低,一般不推荐使用
1.3.4. Fanout Exchange
Fanout即为大名鼎鼎的广播模式了,它不需要管路由键,会把消息发给绑定它的全部队列,就算配置了路由键也会被忽略
1.4. 复杂情况
- 首先我们Direct模式,一个生产者一个消费者的情况,也就对应了一个发送者和一个队列A接收,这是没有疑问的,发送什么接收什么
- 当Direct模式,一个生产者发消息,开启多个消费者也就是多个相同queue,此时消息由多个消费者均匀分摊,不会重复消费(前提ack正常)
- 当Topic模式,一个交换机绑定两个队列,路由键有重叠关系,如下代码,此时指定路由键
topic.message发送消息,队列queueMessage和queueMessages都能接收到相同消息,也就是说,topic模式可以实现类似于广播模式的形式,甚至更加灵活,它能否转发到消息由路由键决定。 - 相比于Fanout模式,我们如果要对消费者队列分组发送,我们需要指定不同的路由键;而Fanout模式则需要指定不同的交换机和队列绑定,实际使用结合实际情况
@Configuration
public class TopicRabbitConfig {
final static String message = "topic.message";
final static String messages = "topic.messages";
@Bean
public Queue queueMessage() {
return new Queue(TopicRabbitConfig.message);
}
@Bean
public Queue queueMessages() {
return new Queue(TopicRabbitConfig.messages);
}
@Bean
TopicExchange exchange() {
return new TopicExchange("exchange");
}
@Bean
Binding bindingExchangeMessage(Queue queueMessage, TopicExchange exchange) {
return BindingBuilder.bind(queueMessage).to(exchange).with("topic.message");
}
@Bean
Binding bindingExchangeMessages(Queue queueMessages, TopicExchange exchange) {
return BindingBuilder.bind(queueMessages).to(exchange).with("topic.#");
}
}
1.5. springboot配置
我们的常用配置如下
spring.rabbitmq.addresses=localhost:5672
spring.rabbitmq.username=user
spring.rabbitmq.password=123456
spring.rabbitmq.virtual-host=/
spring.rabbitmq.connection-timeout=1000
##设置监听限制:最大10,默认5
spring.rabbitmq.listener.simple.concurrency=5
spring.rabbitmq.listener.simple.max-concurrency=10
spring.rabbitmq.publisher-confirms=true
spring.rabbitmq.publisher-returns=true
spring.rabbitmq.template.mandatory=true
spring.rabbitmq.listener.simple.acknowledge-mode=manual
其中最后四条配置需要着重解释:
spring.rabbitmq.publisher-confirms为true,表示生产者消息发出后,MQ的broker接收到了消息,发送回执表示确认接收,不设置则可能导致消息丢失spring.rabbitmq.publisher-returns为true,表示当消息不能到达MQ的Broker端,,则使用监听器对不可达的消息做后续处理,这种一般是路由键没配好,或MQ宕机才可能发生spring.rabbitmq.template.mandatory当上面两个为true时,这个一定要配true,否则上面两个不起作用spring.rabbitmq.listener.simple.acknowledge-mode这个为manual表示手工确认,实际生产应该设为手工,才能保证你的业务是处理完成的,注意业务的幂等性,可重复调用,手工确认代码如下例子
@Component
public class RabbitReceiver {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "queue-1",
durable="true"),
exchange = @Exchange(value = "exchange-1",
durable="true",
type= "topic",
ignoreDeclarationExceptions = "true"),
key = "springboot.*"
)
)
@RabbitHandler
public void onMessage(Message message, Channel channel) throws Exception {
System.err.println("--------------------------------------");
System.err.println("消费端Payload: " + message.getPayload());
Long deliveryTag = (Long)message.getHeaders().get(AmqpHeaders.DELIVERY_TAG);
//手工ACK,获取deliveryTag
channel.basicAck(deliveryTag, false);
}
}
1.6. 队列属性
queue : 队列的名字
durable : 为true表示队列中数据持久化到磁盘,可以防止mq宕机重启数据丢失
exclusive : 为true表示排他性,只允许一个当前连接访问该队列,当前已连接就不允许新的连接进入否则报错,当连接断开当前队列会销毁
autoDelete : 为true表示自动删除,当没有Connection连接到队列的时候,会自动删除
arguments : 这个参数用来添加一些额外参数的,如下图片
- 比如添加
x-message-ttl为5000,则表示消息超过5秒没被处理就会超时过期; x-expires设置120000表示队列在2分钟内没被消费则被删除;x-max-length,x-max-length-bytes表示传送数据的最大长度和字节数x-dead-letter-exchange,x-dead-letter-routing-key表示死信交换机和死信路由,放在需要过期或处理失败的队列属性中,这些数据会转发到死信队列存储起来,创建普通的交换机和队列绑定,把交换机名填到x-dead-letter-exchange的值,填写路由键要符合死信队列的路由键x-max-priority,表示设置优先级,范围为0~255,只有当消息堆积的时候,这个优先级才有意义,数字越大优先级越高x-queue-mode当为lazy,表示惰性队列,3.6.0之后才被引入的概念,相比默认的模式,惰性队列模式会将生产者产生的消息直接存到磁盘中,这当然会增加IO开销,但适合应对大量消息堆积的情况;因为当大量消息堆积时,内存也不够存放,会将消息转存到磁盘,这个过程也是比较耗时且过程中不能接收新的消息。如果需要将普通队列转换成惰性队列需要将原来的队列删除,重新创建个惰性队列绑定。
- 比如添加

1.7. 交换机属性
exchange : 交换机名称
type : 交换机类型
durable : 持久化,同队列
autoDelete : 是否自动删除,同队列
internal : 若为true,表示这个exchange不可以被client用来推送消息,仅用来进行exchange和exchange之间的绑定。
arguments : 额外参数,目前只有个
alternate-exchange,表示当生产者发送消息到这个交换机,路由不到该交换机的队列,则会尝试这个参数指定的交换机进行路由,若路由键匹配,则路由到alternate-exchange指定的队列,相当于转发了,刚好和上一个参数internal配合,若不想本交换机起到路由队列的作用,可以设置internal为true,把消息都转发到alternate-exchange指定的交换机,由该交换机来路由指定队列,- 如下图:
exchange0设置了alternate-exchange交换机为exchange1,生产者发送数据到exchange0路由键为test1,在exchange0路由不到,则转发到exchange1判断路由符合,发送到队列queue1
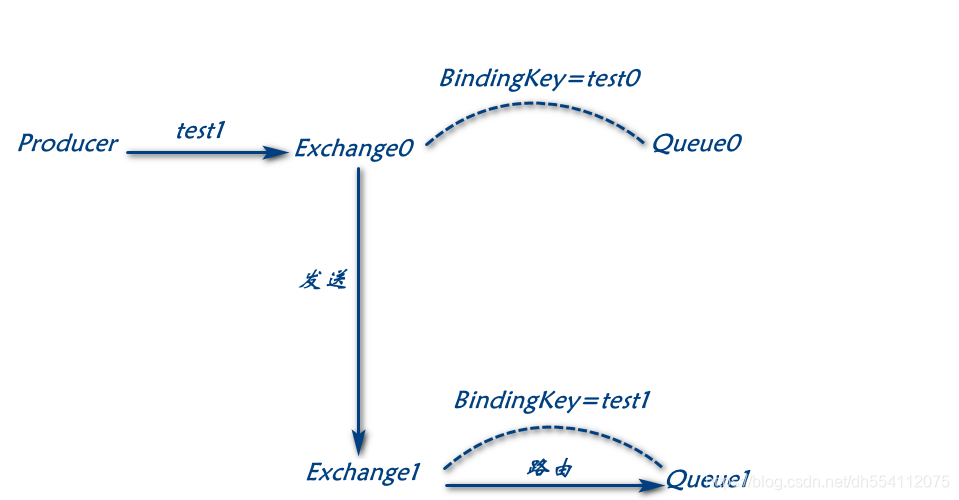
- 如下图:
1.8. 磁盘和内存
在RabbitMQ的管理界面,当我们集群部署时可以看到Nodes节点中Info字段可能为disc也可能ram,表示了磁盘存储或内存储存。事实上,在集群部署的时候,我们至少要一个磁盘储存,它代表了将交换机,队列,绑定,用户等元数据持久化保存到磁盘,一遍重启RabbitMQ也能恢复到原先的状态,当只有一个节点时,必定是磁盘存储;而内存储存也有它的优势,就是效率更高速度更快
1.9. 报错案例
- 当报下列错误,表示你一定存在排他性队列,也就是设置了
exclusive属性的队列,由于同一个连接创建的不同通道可以访问同一个队列,此时由于这个排他属性会得到资源被锁定错误,也就是下列的错误。 - 由此我们可以知道,若你把队列设置成了
exclusive属性的,那么就别创建新的连接去访问同一个队列
ESOURCE_LOCKED - cannot obtain exclusive access to locked queue xxxxxx
今日教学视频:RabbitMQ消息队列从入门到精通,长按图片到百度云

欢迎关注公众号,一起学习进步
RabbitMQ实战应用技巧的更多相关文章
- rabbitMQ实战(一)---------使用pika库实现hello world
rabbitMQ实战(一)---------使用pika库实现hello world 2016-05-18 23:29 本站整理 浏览(267) pika是RabbitMQ团队编写的官方Pyt ...
- Java SpringBoot集成RabbitMq实战和总结
目录 交换器.队列.绑定的声明 关于消息序列化 同一个队列多消费类型 注解将消息和消息头注入消费者方法 关于消费者确认 关于发送者确认模式 消费消息.死信队列和RetryTemplate RPC模式的 ...
- websocket+rabbitmq实战
1. websocket+rabbitmq实战 1.1. 前言 接到的需求是后台定向给指定web登录用户推送消息,且可能同一账号会登录多个客户端都要接收到消息 1.2. 遇坑 基于springbo ...
- celery+RabbitMQ 实战记录2—工程化使用
上篇文章中,已经介绍了celery和RabbitMQ的安装以及基本用法. 本文将从工程的角度介绍如何使用celery. 1.配置和启动RabbitMQ 请参考celery+RabbitMQ实战记录. ...
- RabbitMQ实战经验分享
前言 最近在忙一个高考项目,看着系统顺利完成了这次高考,终于可以松口气了.看到那些即将参加高考的学生,也想起当年高三的自己. 下面分享下RabbitMQ实战经验,希望对大家有所帮助: 一.生产消息 关 ...
- 使用C语言调用mysql数据库编程实战以及技巧
今天编写使用C语言调用mysql数据库编程实战以及技巧.为其它IT同行作为參考,当然有错误能够留言,共同学习. 一.mysql数据库的C语言经常使用接口API 1.首先当然是链接数据库mysql_re ...
- 【全面解禁!真正的Expression Blend实战开发技巧】第十章 FluidMoveBehavior完全解析之三飞出ListBox吧
原文:[全面解禁!真正的Expression Blend实战开发技巧]第十章 FluidMoveBehavior完全解析之三飞出ListBox吧 刚才有人说我的标题很给力,哈哈.那这个标题肯定更给力了 ...
- 【全面解禁!真正的Expression Blend实战开发技巧】十一章 全面解析布局(Grid & Canvas &StackPanel &Wrappanel)
原文:[全面解禁!真正的Expression Blend实战开发技巧]十一章 全面解析布局(Grid & Canvas &StackPanel &Wrappanel) 写这篇文 ...
- 【全面解禁!真正的Expression Blend实战开发技巧】第九章 FluidMoveBehavior完全解析之二平滑运动的滚动条
原文:[全面解禁!真正的Expression Blend实战开发技巧]第九章 FluidMoveBehavior完全解析之二平滑运动的滚动条 这一章讲解FluidMoveBehavior的另一个应用, ...
随机推荐
- [UIApplication sharedApplication].keyWindow.rootViewController
一般来说 [UIApplication sharedApplication].keyWindow.rootViewController 会在 appDelegate 中初始化,并且整个应用运行过程中都 ...
- SourceInsight教程
概述: Source Insight是一个面向项目开发的程序编辑器和代码浏览器,它拥有内置的对C/C++, C#和Java等程序的分析.Source Insight能分析你的源代码并在你工作的同时动态 ...
- [转]RHEL7上配置NFS服务
原文地址:http://380531251.blog.51cto.com/7297595/1659865 1.课程目标 了解什么是NFS及其功能: 掌握NFS的配置: 掌握NFS的验证: 能够单独熟练 ...
- HttpClient忽略SSL证书
今天公司项目请求一个接口地址是ip格式的,如:https://120.20.xx.xxx/xx/xx,报一个SSL的错: 由于之前请求的接口地址都是域名地址,如:https://www.xxx.com ...
- PHP代码篇(五)--如何将图片文件上传到另外一台服务上
说,我有一个需求,就是一个临时功能.由于工作开发问题,我们有一个B项目,需要有一个商品添加的功能,涉及到添加商品内容,比如商品名字,商品描述,商品库存,商品图片等.后台商品添加的接口已经写完了,但是问 ...
- try ... except...,好处是执行失败后,仍然可以继续运行
import requeststry: a=requests.get("https:///www.baidu.com") print('连接成功')except: print('连 ...
- 快读&快写模板【附O2优化】
快读&快写模板 快读快写,顾名思义,就是提升输入和输出的速度.在这里简单介绍一下几种输入输出的优劣. C++ cin/cout 输入输出:优点是读入的时候不用管数据类型,也就是说不用背scan ...
- WEB 中的文件下载(待修改、完善)
在 WEB 开发中,我们会期望用户在点击某个链接的时候,下载一个文件(不管这个文件能不能被浏览器解析,都要下载).以前接触过一种方式,就是在响应 header 中设置 force-download : ...
- MySQL 行溢出数据
MySQL 行溢出数据 MySQL 对一条记录占用的最大储存空间是有限制的,除了 BLOB 和 TEXT 类型之外,其他所有列 (不包括隐藏列和记录头信息) 占用的字节长度不能超过 65535 个字节 ...
- C++ string push_back()
函数功能: 在后面添加一项 vector头文件的push_back函数,在vector类中作用为在vector尾部加入一个数据.string中的push_back函数,作用是字符串之后插入一个字符. ...