(数据科学学习手札70)面向数据科学的Python多进程简介及应用
本文对应脚本已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
一、简介
进程是计算机系统中资源分配的最小单位,也是操作系统可以控制的最小单位,在数据科学中很多涉及大量计算、CPU密集型的任务都可以通过多进程并行运算的方式大幅度提升运算效率从而节省时间开销,而在Python中实现多进程有多种方式,本文就将针对其中较为易用的几种方式进行介绍。
二、利用multiprocessing实现多进程
multiprocessing是Python自带的用于管理进程的模块,通过合理地利用multiprocessing,我们可以充分榨干所使用机器的CPU运算性能,在multiprocessing中实现多进程也有几种方式。
2.1 Process
Process是multiprocessing中最基础的类,用于创建进程,先来看看下面的示例:
single_process.py
import multiprocessing
import datetime
import numpy as np
import os
def job():
print(f'进程{os.getpid()}开始计算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
for j in range(100):
_ = np.sum(np.random.rand(10000000))
print(f'进程{os.getpid()}结束运算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == '__main__':
process = multiprocessing.Process(target=job)
process.start()
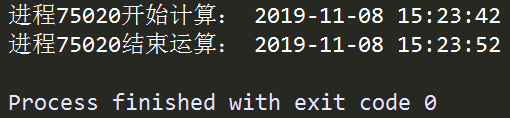
图1 single_process.py运行结果
在上面的例子中,我们首先定义了函数job(),其连续执行一项运算任务100次,并在开始和结束的时刻打印该进程对应的pid,用来唯一识别一个独立的进程,接着利用Process()将一个进程实例化,其主要参数如下:
target: 需要执行的运算函数
args: target函数对应的传入参数,元组形式传入
在process创建完成之后,我们对其调用.start()方法执行运算,这样我们就实现了单个进程的创建与使用,在此基础上,我们将上述例子多线程化:
multi_processes.py
import multiprocessing
import datetime
import numpy as np
import os
def job():
print(f'进程{os.getpid()}开始计算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
for j in range(100):
_ = np.sum(np.random.rand(10000000))
print(f'进程{os.getpid()}结束运算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == '__main__':
process_list = []
for i in range(multiprocessing.cpu_count() - 1):
process = multiprocessing.Process(target=job)
process_list.append(process)
for process in process_list:
process.start()
for process in process_list:
process.join()
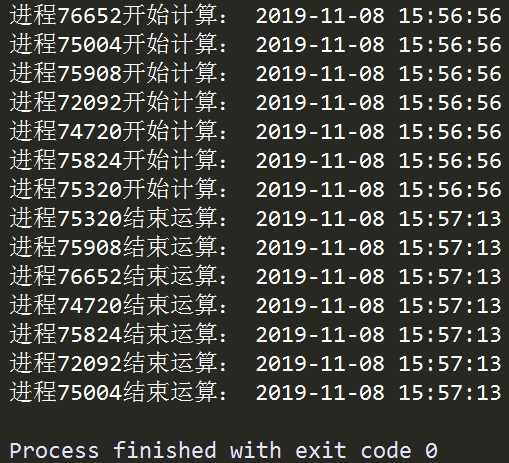
图2 multi_processes.py运行结果
在上面的例子中,我们首先初始化用于存放多个线程的列表process_list,接着用循环的方式创建了CPU核心数-1个进程并添加到process_list中,再接着用循环的方式将所有进程逐个激活,最后使用到.join()方法,这个方法用于控制进程之间的并行,如下例:
join_demo.py
import multiprocessing
import os
import datetime
import time
def job():
print(f'进程{os.getpid()}开始:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
time.sleep(5)
print(f'进程{os.getpid()}结束:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == '__main__':
process1 = multiprocessing.Process(target=job)
process2 = multiprocessing.Process(target=job)
process1.start()
process1.join()
process2.start()
process2.join()
print('='*200)
process3 = multiprocessing.Process(target=job)
process4 = multiprocessing.Process(target=job)
process3.start()
process4.start()
process3.join()
process4.join()
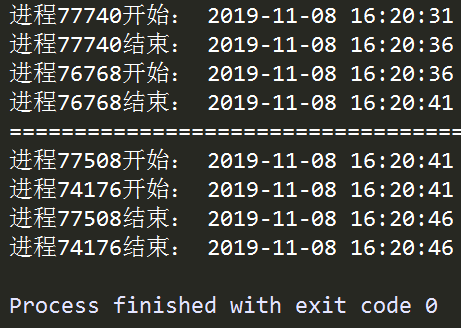
图2 multi_processes.py运行结果
观察对应进程执行的开始结束时间信息可以发现,一个进程对象在.start()之后,若在其他的进程对象.start()之前调用.join()方法,则必须等到先前的进程对象运行结束才会接着执行.join()之后的非.join()的内容,即前面的进程阻塞了后续的进程,这种情况下并不能实现并行的多进程,要想实现真正的并行,需要现行对多个进程执行.start(),接着再对这些进程对象执行.join(),才能使得各个进程之间相互独立,了解了这些我们就可以利用Process来实现多进程运算;
2.2 Pool
除了上述的Process,在multiprocessing中还可以使用Pool来快捷地实现多进程,先来看下面的例子:
Pool_demo.py
from multiprocessing import Pool
import numpy as np
from pprint import pprint
def job(n):
return np.mean(np.random.rand(n)), np.std(np.random.rand(n))
if __name__ == '__main__':
with Pool(5) as p:
pprint(p.map(job, [i**10 for i in range(1, 6)]))
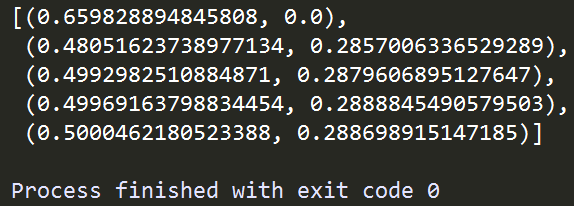
图3 Pool_demo.py运行结果
在上面的例子中,我们使用Pool这个类,将自编函数job利用.map()方法作用到后面传入序列每一个位置上,与Python自带的map()函数相似,不同的是map()函数将传入的函数以串行的方式作用到传入的序列每一个元素之上,而Pool()中的.map()方法则根据前面传入的并行数量5,以多进程并行的方式执行,大大提升了运算效率。
三、利用joblib实现多进程
与multiprocessing需要将执行运算的语句放置于含有if name == 'main':的脚本文件中下不同,joblib将多进程的实现方式大大简化,使得我们可以在IPython交互式环境下中灵活地使用它,先看下面这个例子:
from joblib import Parallel, delayed
import numpy as np
import time
import datetime
def job(i):
start = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
time.sleep(5)
end = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return start, end
result = Parallel(n_jobs=5, verbose=1)(delayed(job)(j) for j in range(5))
result
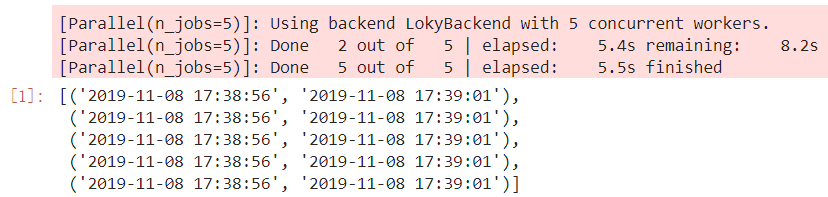
图4 joblib并行示例
在上面的例子中,我们从joblib中导入Parallel和delayed,仅用Parallel(n_jobs=5, verbose=1)(delayed(job)(j) for j in range(5))一句就实现了并行运算的功能,其中n_jobs控制并行进程的数量,verbose参数控制是否打印进程运算过程,如果你熟悉scikit-learn,相信这两个参数你一定不会陌生,因为scikit-learn中RandomForestClassifier等可以并行运算的算法都是通过joblib来实现的。
以上就是本文的全部内容,如有笔误望指出!
(数据科学学习手札70)面向数据科学的Python多进程简介及应用的更多相关文章
- (数据科学学习手札18)二次判别分析的原理简介&Python与R实现
上一篇我们介绍了Fisher线性判别分析的原理及实现,而在判别分析中还有一个很重要的分支叫做二次判别,本文就对二次判别进行介绍: 二次判别属于距离判别法中的内容,以两总体距离判别法为例,对总体G1,, ...
- (数据科学学习手札22)主成分分析法在Python与R中的基本功能实现
上一篇中我们详细介绍推导了主成分分析法的原理,并基于Python通过自编函数实现了挑选主成分的过程,而在Python与R中都有比较成熟的主成分分析函数,本篇我们就对这些方法进行介绍: R 在R的基础函 ...
- (数据科学学习手札20)主成分分析原理推导&Python自编函数实现
主成分分析(principal component analysis,简称PCA)是一种经典且简单的机器学习算法,其主要目的是用较少的变量去解释原来资料中的大部分变异,期望能将现有的众多相关性很高的变 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
随机推荐
- 夯实Java基础系列20:从IDE的实现原理聊起,谈谈那些年我们用过的Java命令
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- Java 学习笔记之 方法内的临时变量是线程安全
方法内的临时变量是线程安全: 方法内部的私有变量,是线程安全的. public class HasSelfPrivateNum { public void addI(String username) ...
- Zookeeper 学习笔记之 Leader Election
ZooKeeper四种节点类型: Persist Persist_Sequential Ephemeral Ephemeral_Sequential 在节点上可注册的Watch,客户端先得到通知再得到 ...
- (八十三)c#Winform自定义控件-导航菜单(扩展)
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kwwwvagaa/NetWinformControl 码云:ht ...
- yii2 对字段 自动加一 或 减一
用于数字类型,将值进行 累加 或者 累减 $count = 1, 就是加一 . $count = -1, 就是减一 . $effect = Model::updateAllCounters( [ ...
- 究竟是.NET淹没在汪洋大海,还是人心的浮躁、见识的短浅?
这些年来有相当多的.net开发者转了其他语言,也有一部分是迫不得已因为公司的转型而转,其中也有一大部分觉得.net没前途性能不好比某些语言性能差.还有一部分会说出一些名词去指责.net说他做不到,其实 ...
- Rust到底值不值得学--Rust对比、特色和理念
前言 其实我一直弄不明白一点,那就是计算机技术的发展,是让这个世界变得简单了,还是变得更复杂了. 当然这只是一个玩笑,可别把这个问题当真. 然而对于IT从业者来说,这可不是一个玩笑.几乎每一次的技术发 ...
- group by 如何合并字符串优化记?
sqlserver 2005及以上版本 表(tb) id value 1 aa 2 cc 3 bb 3 dd 4 aa 4 cc 4 dd ...
- Git学习记录-基本命令篇
目录 网页在线练习地址 https://learngitbranching.js.org/ 1.git commit Git 仓库中的提交记录保存的是你的目录下所有文件的快照,就像是把整个目录复制,然 ...
- Linux上安装jdk1.8和配置环境变量
前言 Linux 上安装jdk1.8 和配置环境变量,参考相关文档,本人在此总结,操作归纳如下. 第一步:创建jdk安装目录(该/usr/local/src 目录是空的,最好把我们自己下载的放到这,容 ...