03爬虫-requests模块基础(1)
requests模块基础
什么是requests模块 requests模块是python中原生基于网络模拟浏览器发送请求模块。功能强大,用法简洁高效。
为什么要是用requests模块
- 用以前的urllib模块需要手动处理url编码
- 手动处理post参数
- 处理cookie和代理操作繁琐
..............
requests模块
- 自动处理url编码
- 自动处理post参数
- 简化cookie和代理操作
...............
如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
- 安装:
- 1、基于requests模块的get请求 需求:爬取搜狗指定词条搜索后的页面数据
import requests
#指定url
base_url = "https://www.sogou.com/web"
#搜索词条的关键字
query = {
"query":"python"
}
#模仿User-Agent(伪造电脑版本信息以及什么浏览器信息)
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
#requests.get(url, params=None, **kwargs),第一个是url地址,第二个关键字参数。
response = requests.get(url=base_url,params=query,headers=headers)
#因为发送的是get方式 所以返回的是一个字符串,即text可得相关html标签页
print(response.text)2、基于requests模块ajax的get请求 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
import requests
url = "https://movie.douban.com/j/chart/top_list"
#根据需求取数据
start = input("enter start:")
limit = input("enter limt:")
#请求头里面的请求关键字
param = {
"type": "",
"interval_id": "100:90",
"action": "",
"start": start,
"limit": limit,
}
#伪造机型和浏览器
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
#开始get请求,因为是ajax的get方法所以请求应该是get
response = requests.get(url=url,params=param,headers=headers)
#返回的是一个json数据,因此要用json解析
print(response.json())3、基于requests模块ajax的post请求 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
import requests
url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
#输入保存信息地点
keyword = input("enter a word:")
#请求头里面的请求关键字
for i in range(1,9):
data = {
"cname":"",
"pid": "",
"keyword": keyword,
"pageIndex": i,
"pageSize": "",
}
#伪造机型和浏览器
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
#因为是ajax的post方法所以post请求
response = requests.post(url=url,data=data,headers=headers)
#响应的是一个text数据,因此要用text解析
fileName = str(i)+".txt"
with open(fileName,"w",encoding="utf8") as f:
f.write(response.text)显示文件有:
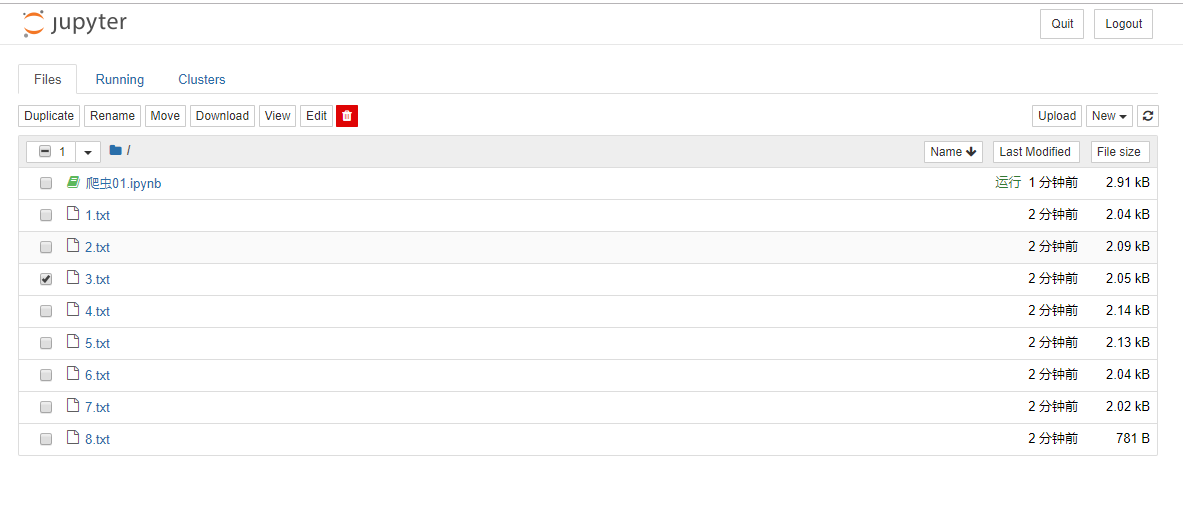
4、综合练习 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据http://125.35.6.84:81/xk/
import requests url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList"
ID_list = []
# 伪造机型和浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
for i in range(1,16):
data = {
"on": "true",
"page": i,
"pageSize": "",
"productName": "",
"conditionType": "",
"applyname": "",
"applysn": "",
} #因为是ajax的post方法所以post请求
response = requests.post(url=url,data=data,headers=headers).json() ID_list.append(response["list"][0]["ID"])
base_url = "http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById"
for i in ID_list:
data = {
"id": i,
}
# 响应的是一个json数据,因此要用json解析
response = requests.post(url=base_url,data=data,headers=headers)
print(response.json())Jupyter notebook应该是库出问题了,找了很久都没弄到原因,还一直以为自己代码出现问题了。换到pycharm成功运行

03爬虫-requests模块基础(1)的更多相关文章
- 05爬虫-requests模块基础(2)
今日重点: 1.代理服务器的设置 2.模拟登陆过验证码(静态验证码) 3.cookie与session 4.线程池 1.代理服务器的设置 有时候使用同一个IP去爬取同一个网站,久了之后会被该网站服务器 ...
- 爬虫之requests模块基础
一.request模块介绍 1. 什么是request模块 - python中原生的基于网络请求的模块,模拟浏览器发起请求. 2. 为什么使用request模块 - urllib需要手动处理url编码 ...
- 03 requests模块基础
1. requests 模块简介 什么是requests 模块 requests模块是python中原生的基于网络请求的模块,功能强大,用法简洁高效.在爬虫领域中占据着半壁江山的地位.requests ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
- 爬虫 requests模块的其他用法 抽屉网线程池回调爬取+保存实例,gihub登陆实例
requests模块的其他用法 #通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下 Host Referer #大型网站通常都会根据该参数判断请求的来源 ...
- 爬虫——requests模块
一 爬虫简介 #1.什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样. #2.互联网建立的目的? 互联网的核心价值在于数据的共享/传递:数据是 ...
- 2 爬虫 requests模块
requests模块 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,reques ...
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- 爬虫--requests模块学习
requests模块 - 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能 ...
随机推荐
- vector function trmplate
/* vector function template programmer:qpz */ #include <iostream> #include <vector> #def ...
- Java集合框架之LinkedList浅析
Java集合框架之LinkedList浅析 一.LinkedList综述: 1.1LinkedList简介 同ArrayList一样,位于java.util包下的LinkedList是Java集合框架 ...
- 在Azure云上实现postgres主备切换
以下是工作上实现postgres主备切换功能所用到的代码和步骤,中间走了不少弯路,在此记录下.所用到的操作系统为centos 7.5,安装了两台服务器,hostname为VM7的为Master,VM8 ...
- ABC133F - Colorful Tree
ABC133FColorful Tree 题意 给定一颗边有颜色和权值的树,多次询问,每次询问,首先更改颜色为x的边的权值为y,然后输出u到v的距离. 数据都是1e5量级的. 思路 我自己一开始用树链 ...
- 基于GitLab+Jenkins的DevOps赋能实践
随着微服务.中台架构的兴起,DevOps也变得非常关键,毕竟是一些基础设施层面的建设,如果搞好了对后面的研发工作会有很大的效率提升.关于DevOps本身的概念,网上已经非常多了,在园子里随便搜索一些都 ...
- 【Offer】[52] 【两个链表的第一个公共结点】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 输入两个链表,找出它们的第一个公共结点.下图中6为公共结点:  牛客网刷题地址 思路分析 如果两个链表有公共节点,那么公共节点出现在两 ...
- 【Offer】[23] 【链表中环的入口结点】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 一个链表中包含环,如何找出环的入口结点?  思路分析 判断链表中是否有环:用快慢指针的方法,慢指针走一步,快指针走两步,如果快指针追上 ...
- Python 的整数与 Numpy 的数据溢出
某位 A 同学发了我一张截图,问为何结果中出现了负数? 看了图,我第一感觉就是数据溢出了.数据超出能表示的最大值,就会出现奇奇怪怪的结果. 然后,他继续发了张图,内容是 print(100000*20 ...
- 04 python之函数详解
一.函数初识 函数的产生:函数就是封装一个功能的代码片段. li = ['spring', 'summer', 'autumn', 'winter'] def function(): count = ...
- 结合生活案例实现rabbitmq消息通信
title: 基于springboot实现rabbitmq消息通信 date: 2019-09-11 09:00:30 tags: - [rabbitmq] categories: - [spring ...