hbase 相关
----------------------------------------hbase的 安装----------------------------------------
本地安装:
1 解压文件夹。
2 修改 conf/hbase-site.xml ,配置 数据文件夹
<property>
<name>hbase.rootdir</name>
<value>file:///DIRECTORY/hbase</value>
</property>
3 然后就可以启动了:./bin/start-hbase.sh 4 进入客户端:./bin/hbase shell 分布式安装:
1 修改 数据文件目录( habse-site.xml)
hbase.rootdir
2 开启分布式( habse-site.xml)
hbase.cluster.distributed
3 配置regionserver (regionservers) 4 停用 自带的 zk ( hbase-en.sh)
HBASE_MANAGES_ZK=false 5 配置 zk 集群地址,和 配置 只看数据文件地址( habse-site.xml)
hbase.zookeeper.quorum
hbase.zookeeper.property.dataDir 6 复制 hdfs-site.xml 到hbase的 配置文件目录。 7 启动 hbase
./bin/start-hbase.sh 备注:默认 只会在启动 hbase 的机器上启动一个 hmaster 。但是我们可以在别的 任意节点再次启动其他 hmaster。
8 启动别的 hmaster
./hbase-daemon.sh start master
----------------------------------------hbase的常见语法----------------------------------------
1 创建表 :
create 'test', 'cf'
2 插入一行: (一次只能插入一列,如果有多列 反复用这个rowkey 插入)
put 'test', 'row1', 'cf:a', 'value1'
3 查询:
scan 'test'
4 查询一行
get 'test', 'row1' 5 禁用一张表
disable 'test' 6 删除一张表:(只有禁用了的才能删除)
drop 'test' 7 停止 hbase:
./bin/stop-hbase.sh
8 查看表结构:
desc 'test'
----------------------------------------hbase的理论知识点---------------------------------------- 1 hbase 是一个nosql 数据库。 2 hbase 是一个 列存数类型nosql据库 3 hbase 数据存放的 没一行必须有 rowkey 。并且查询几乎都需要使用到 rowkey,所以 rowkey 生成规则非常重要。 4 hbase 需要预定义列族( column fmaliy ),在定义表的时候5 hbase 官方建议 列族不超过3 个,因为为超过三个带来的性能消耗问题目前还没有太好的解决方
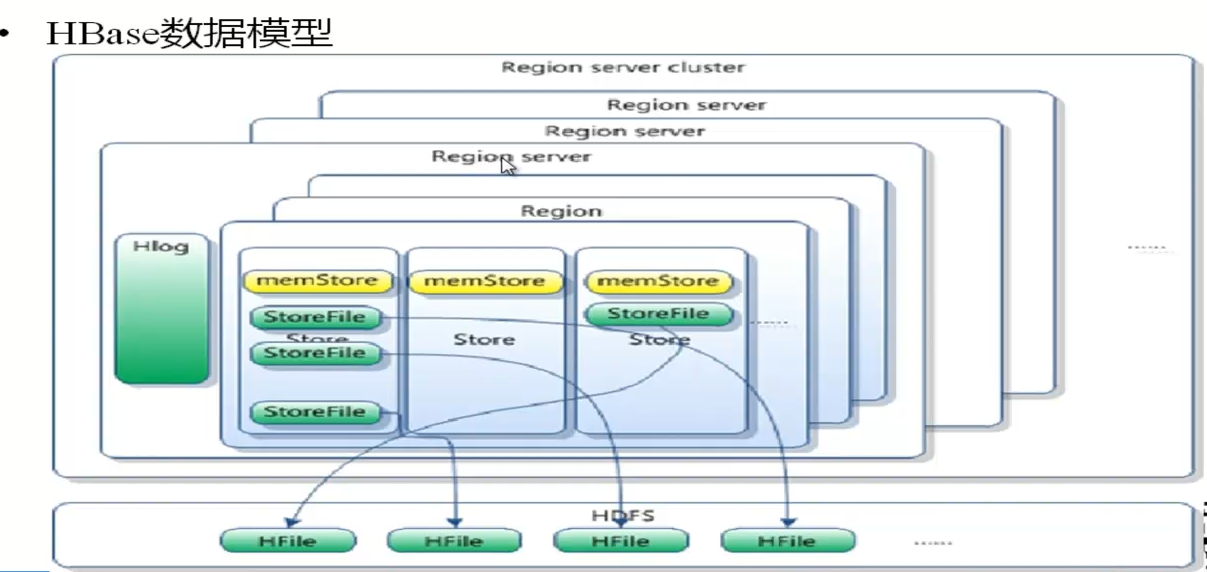
6 hbase 的 真正列叫做 colunm。 可以在 put 数据的时候任意指定。 7 hbase 决定一个数据cell的因数 , rowkey( 行号) ,cf(列族) ,column(列)和 timestamp( 时间)。 8 cell 中的数据是 以 key value 的形式存储的。key 的组成:key = {rowkey + column + version}, cell 里面的 value 是 数据的字数组。和 基于内存的 key-value nosql 数据库不同的是 这个 value 主要是放在 硬盘。 9 cell 是 hbase存储数据的基本单元。 10 每次向 hbase 使用的 hdfs 存储数据,不利于修改,hbase的修改 是一时间毫秒数最为 version 另外存了一份,如果 最大当前 rowkey 对应的 column 对应的数据版本超过表允许的版本,那么会自动删除当前数据块最旧一个的版本。 11 HLog ( WAL log ) 类似数据库 的 tranlog , 具体里面有什么 有空查询一下。 12 hbase 体系架构图
13 hbase 的 主节点叫做 HMaster,从节点叫做 HRegionserver。 14 一个 HRegionServer 有 多个 Hregion, 但是 只有一个Hlog 。
15 HRegion 把表中的数据进行横向切分(按照rowkey ,rowkey 连续的一部分放在一起的,有序的)。
16 HRegion 下面有多个 Store ,每一个 Store 代表一个 列族。如果这个表只有一个 cf 那么 就只有一个 store。(并且每一个 cf 的数据都存在同一个目录下)
17 store 分 2 种 ,一种叫做 memStore ,一种叫做 storeFile。
18 memStore 是数据刚 写入的时候在内存中。这时候就是在 memstore 里面。
19 当 memstore 触发溢写的时候 ,产生 storeFile ,每次溢写都产生一个新的 storeFile。
20 当系统的 storeFile 多到一定数量,就会触发合并压缩,产生更大的 单个 storeFile。
21 合并压缩分2 中,一种 辅助压缩( minor compaction),一种是主要压缩( major compaction )
22 只有 major compaction 才能版本合并和删除老版本数据。
23 当某个 region 的所有的 storeFile 大于 一定值的时候会吧自己分成2 个region,这个过程叫做裂变,并且 hmaster 会把其中一个region 分到合适的regionserver 上。
24 master 做的事情
1 为 region server 分配region。
2 负责 region server 的负载均衡(吧 region 分给 region 少的region server)
3 如果有 region server下线。那么在别的region server 上找到 这个 region server 上的 region ,并且重新复制这些region,并且分配各合适的 region server。
4 管理用户的 table的 增删改操作。
region server 做的事情
1 维护自己管理的region,处理这些region的io 请求
2 负责切片 运行过程中变得 过大的 region,这个过程叫做 region的 裂变。
25 HRegion 是hbase 中分布式存储和负载均衡的最小单元。 一个表的多个 region 可以在不同region server 上。
26 storeFile 是 以 Hfile 的格式存在hdfs 上的。
27 如果没有溢写 过,那么这时候 store 没有storeFile, 在 hdfs 上 就没有 数据。
28 hbase 数据模型
hbase 相关的更多相关文章
- HBase相关的一些点
1.在运行Hbase时,如果遇到出错之后: 可以通过{HBASE_HOME}目录,我的是在/usr/soft/hbase下的logs子目录中的日志文件查看错误原因.2.启动关闭Hadoop和HBase ...
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
- HBase相关
hadoop和hbase节点添加和单独重启 有时候hadoop或hbase集群运行时间久了后,某些节点就会失效,这个时候如果不想重启整个集群(这种情况在很多情况下已经不被允许),这个时候可以单独重启失 ...
- HBase 相关API操练(三):MapReduce操作HBase
MapReduce 操作 HBase 在 HBase 系统上运行批处理运算,最方便和实用的模型依然是 MapReduce,如下图所示. HBase Table 和 Region 的关系类似 HDFS ...
- HBase 相关API操练(一):Shell操作
HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”. HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建. ...
- 暑假第五周总结(学习HBASE相关知识)
本周主要对HBASE的相关知识进行了学习,主要是通过视频的讲解了解到了HBASE的存储机制,HBASE的机制与普通的关系型数据库完全不同,HBASE以列进行存储,其主要执行的就是增删查操作,其更改主要 ...
- 大数据Hbase相关运维题
1.启动先电大数据平台的 Hbase 数据库,其中要求使用 master 节点的RegionServer.在 Linux Shell 中启动 Hbase shell,查看 HBase 的版本信息.(相 ...
- HBase篇--HBase操作Api和Java操作Hbase相关Api
一.前述. Hbase shell启动命令窗口,然后再Hbase shell中对应的api命令如下. 二.说明 Hbase shell中删除键是空格+Ctrl键. 三.代码 1.封装所有的API pa ...
- HBase相关问题
HBase和Hive的异同之处? 共同点:HBase与Hive都是架构在Hadoop之上,底层存储都是使用HDFS 区别: 1). Hive是建立在Hadoop之上为了减少MapReduce jobs ...
随机推荐
- [Spring]初识Spring-Spring的基础使用-如何通过Bean来实例化?
Spring框架的基础使用 XML配置信息,Bean的不同实例化方式,注入 实例化 XML文件中的参数设置 1.通过构造器进行实例化(重点,常用方式) <bean name="aCls ...
- jetty404web界面服务器信息隐藏
jetty服务器报以上的404错误时,为了信息安全必须隐藏信息错误提示 在jetty的配置文件jetty.xml添加以下内容: 重启一下jetty服务器就OK了,在验证时是这样的:
- Python 操作系统介绍 进程的创建
背景知识 顾名思义,进程即正在执行的一个过程.进程是对正在运行程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内 ...
- Python Algorithms – chapter2 基础知识
一.渐进记法 三个重要的记号 Ο.Ω.Θ,Ο记法表示渐进上界,Ω记法表示渐进下界,Θ记法同时提供了函数的上下界 几种常见的渐进运行时间实例 三种重要情况 最好的情况,最坏的情况,平均情况 最坏的情况通 ...
- c++下基于windows socket的多线程服务器(基于TCP协议)
之前用c++实现过基于windows socket的单线程TCP服务器(http://www.cnblogs.com/jzincnblogs/p/5170230.html),今天实现了一个多线程的版本 ...
- Kaggle:Home Credit Default Risk 数据探索及可视化(1)
最近博主在做个 kaggle 竞赛,有个 Kernel 的数据探索分析非常值得借鉴,博主也学习了一波操作,搬运过来借鉴,原链接如下: https://www.kaggle.com/willkoehrs ...
- ubuntu discuz 该函数需要 PHP 支持 XML。请联系空间商,确定开启了此项功能
apt-get install php-xml apt-get install php-xml-parser
- Project Euler 54
#include<bits/stdc++.h> using namespace std; ]; ]; ; map<char,int> mp; //map<char,cha ...
- vue的理解
vue提供的MVVM框架模式的数据双向绑定,实现了HTML和js的代码分离,提高代码的维护性 vue.js的核心思想包括:数据驱动和组件化思想. 如果没有中间的ViewModel则关系图编程下面所示: ...
- easyui表单校验
痛苦使人清醒,痛苦使人警惕.生于忧患,死于安乐.付出总会有回报. 1.下面跟大家分享使用easyui时表单中的值如何校验. 1.1 首先,在你的jsp/html页面引入JQuery和easyui的js ...