python写网络爬虫的环境搭建
网上找了好多资料,都不全,通过资料的整理,包括自己的测试,终于把环境打好了,真是对于一个刚接触爬虫的人来说实属不易,现在分享给大家,若有不够详细之处,希望各位网友能补充。
第一步,下载python,
这里有一个巨坑,python2.x与python3.x变化实在是太大,博主开始用的python2.7,后来发现很多模块版本太新,根本没办法使用,兼容性出了问题,索性把python2.7给卸了,然后下了python3.4,如果你习惯了用python2.x,就不要轻易升级,如果你是刚学python,建议还是安装3.x版本。还有就是注意python是64位还是32位。
第二步,环境变量设置,由于会使用python命令,所以最好还是设一个
桌面计算机—>右键“属性”—>点击“高级系统设置”—>高级属性里点击“环境变量”—>在系统变量里path中添加python安装目录。
第三步,下载一个合适的idl(代码编辑器),python自带的idle实在是太水了,对于一个项目来说,根本满足不了需求,只能做简单的测试。现在成熟的idl很多,博主使用的是Pycharm,觉得挺好用的,其他的不了解,你们可以尝试装机试试。

第四步,下载Beautiful Soup,
Beautiful Soup是一个非常流行的python模块,这个模块可以解析网页,并提供定位内容的便捷接口,对于Beautiful Soup的介绍,大家在网上都能查到,博主就不浪费时间了。对于python3.x必须安装Beautiful Soup4,其他版本可能安装不了。
下载后解压到Python安装目录下
打开cmd编辑器,进入到beautifulsoup文件夹内
执行
setup.py build
然后执行
setup.py install
这样 Beautiful Soup模块就顺利的安装到了python3.4里
第五步,下载lxml库,lxml是Python语言里和XML以及HTML工作的功能最丰富和最容易使用的库。这一步博主真是走了好多弯路,先是下载lxml的版本不匹配,再是pip版本太低,弄了好久终于解决了。
在资源库里下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/,这里lxml有好多版本:

cp27代表是python2.7,cp34代表python3.4,amd64是64位的系统,不加代表32位。大家一定要对号入座,版本下错就惨了,就像博主我。。。
下载后把它放进python的安装目录下,此操作与Beautiful Soup一样,这样主要是为了方便管理。在cmd命令里,先执行“python -m pip install wheel”,安装wheel,成功后在python目录下的Lib\site-packages,能查看到wheel文件夹,代表安装成功。
然后安装lxml,“python -m pip install 你的lxml的路径(D:\workapps\python3.4.4\lxml-3.6.4-.....)”,如果提示你pip版本太低,则先更新pip(pip是一个安装和管理 Python 包的工具),命令行输入“python
-m pip upgrade pip”,升级完成后,再次安装lxml,就完成了。最后打开Pycharm,测试程序OK!!!
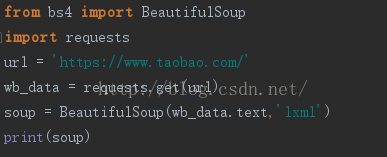
附上淘宝网页抓取测试代码:
本文转载于:https://blog.csdn.net/u011139117/article/details/52788785
python写网络爬虫的环境搭建的更多相关文章
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
- Python写网络爬虫爬取腾讯新闻内容
最近学了一段时间的Python,想写个爬虫,去网上找了找,然后参考了一下自己写了一个爬取给定页面的爬虫. Python的第三方库特别强大,提供了两个比较强大的库,一个requests, 另外一个Bea ...
- 笔记之《用python写网络爬虫》
1 .3 背景调研 robots. txt Robots协议(也称为爬虫协议.机器人协议等)的全称是"网络爬虫排除标准"(Robots Exclusion Protocol),网站 ...
- 读书笔记--用Python写网络爬虫02--数据抓取
抓取(scraping)---爬虫从网页中抽取一些数据用以实现某些用途. 三种抽取网页数据的方法:正则表达式.Beautiful Soup和lxml. 2.1 分析网页 通过浏览器自带选项,查看网页源 ...
- Python 写网络爬虫思路分析
首先从程序入口开始分析,在程序入口处传入一个待爬取的网址, 使用下载器Html_downloader类下载该地址的内容,使用解释器 parser分析内容,利用BeautifulSoup包抓取想要爬取的 ...
- 读书笔记--用Python写网络爬虫01--网络爬虫简介
Wiki - Web crawler 百度百科 - 网络爬虫 1.1 网络爬虫何时使用 用于快速自动地获取网络信息,避免重复性的手工操作. 1.2 网络爬虫是否合法 网络爬虫目前人处于早期的蛮荒阶段, ...
- 用python写网路爬虫 PDF高清完整版免费下载 Python基础教程免费电子书 python入门书籍免费下载
<用python写网路爬虫PDF免费下载>PDF书籍下载 内容简介 作为一种便捷地收集网上信息并从中抽取出可用信息的方式,网络爬虫技术变得越来越有用.使用Python这样的简单编程语言,你 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
随机推荐
- (转) GAN应用情况调研
本文转自: https://mp.weixin.qq.com/s?__biz=MzA5MDMwMTIyNQ==&mid=2649290778&idx=1&sn=9816b862 ...
- Java中常用的方法
枚举: 1:DemoEnum.valueOf(String str) 从枚举类中中找字符串,如果有则返回对应枚举值 2:DemoEnum.values() 获得枚举集合 3:DemoEnum.prop ...
- keySet,entrySet用法 以及遍历map的用法
Set<K> keySet() //返回值是个只存放key值的Set集合(集合中无序存放的)Set<Map.Entry<K,V>> entrySet() //返回映 ...
- PTA 输出全排列(20 分)
7-2 输出全排列(20 分) 请编写程序输出前n个正整数的全排列(n<10),并通过9个测试用例(即n从1到9)观察n逐步增大时程序的运行时间. 输入格式: 输入给出正整数n(<10). ...
- 接口Interface的四种含义
摘自<需求分析与系统设计(第3版)>第七章Q5 1. GUI——显示信息的计算机屏幕(注:其他终端) 2. API——是一套软件程序和开发工具,为应用程序提供函数调用,使程序可以访问一些级 ...
- Codeforces Round #107 (Div. 1) B. Quantity of Strings(推算)
http://codeforces.com/problemset/problem/150/B 题意: 给出n,m,k,n表示字符串的长度为n,m表示字符种类个数,k表示每k个数都必须是回文串,求满足要 ...
- Python cmd中输入'pip' 不是内部或外部命令,也不是可运行的程序或批处理文件。
配置一下环境变量,找到 添加一下Scripts文件夹的路径,如:这是我的路径C:\Users\ck\AppData\Local\Programs\Python\Python36 就是你python的安 ...
- template-web.js 引用变量、函数
1.关键字 $imports.+变量/函数 {{if $imports.myParseInt(b.health_money)}} <span class="num"> ...
- win10上安装keras
下载Anaconda https://www.anaconda.com/ 点击进入下载界面 选择Windows版本64位,python3.7 下载完成后 ,双击安装 等待安装完成! 安装MinGW包, ...
- Python安装第三方库的安装技巧
电脑:Windows10 64位. Python IDE 软件:JetBrains PyCharm Community Edition 2018.1.3 x64 Python version : Py ...